分享一个爬虫框架
Posted 逆风骑车
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享一个爬虫框架相关的知识,希望对你有一定的参考价值。
我们用了7天已经讲完了Python基础,有坚持学习的朋友应该有所得,今天主要利用之所学的内容开发一个简单的爬虫框架爬取豆瓣电影信息,这个框架主要特点就是上手快,我尽量用最简单的语言讲解,不涉及登录等高级功能,适合不想花太多时间抓取静态网页的同学,后附代码就可以自己实验,也可以用来爬取自己喜欢的静态网页。
开发框架的背景
当年在做研究的时候,需要网页上的静态数据做分析,数据的类型就是那种一页几条,然后有几百上千页,那时没有技术手段,所以通宵达旦的人肉复制黏贴,后来以这个为契机学习了Python的爬虫,从而开始了漫长的学习之路。这里作为展示,用来爬取豆瓣电影。
框架结构
框架的结构大致分为:Url的管理,Url的下载,Url的解析,主程序以及主程序的入口,各部分可以针对不同的网页,单独修改使用。
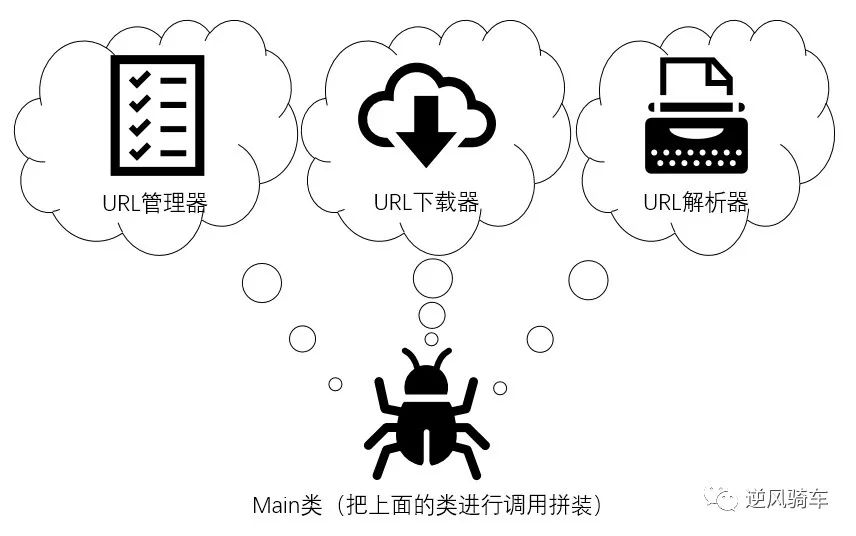
URL管理器,程序中为UrlManager
1class UrlManager(object):
2 def __init__(self):
3 self.new_urls = set()
4 self.old_urls = set()
5 def add_new_url(self, url):
6 if url is None:
7 return
8 if url not in self.new_urls and url not in self.old_urls:
9 self.new_urls.add(url)
10 def add_new_urls(self, urls):
11 if urls is None or len(urls) == 0:
12 return
13 for url in urls:
14 self.add_new_url(url)
15 def has_new_url(self):
16 return len(self.new_urls) != 0
17 def get_new_url(self):
18 new_url = self.new_urls.pop()
19 self.old_urls.add(new_url)
20 return new_url
初始化的时候,需要有两个容器,一个装新的url(new_urls),一个装爬取过的url(old_urls),这里用set集合(另一种Python的容器,数据有序存放,以后会讲)来充当容器。
管理网址的时候需要有添加新的url函数(add_new_url)、批量添加url的函数(add_new_urls)、判断容器(new_urls)里是不是有新的url的函数(has_new_url)以及从容器里获取一个新的url的函数(get_new_url)。
add_new_url:注意要判断是不是在新容器和就容器里,如果在的话,那么就是一个待爬取的url或者是一个已经爬取过的url。
add_new_urls:这个函数主要是后面解析器对页面解析后得到页面上的所有的url,然后批量添加进容器里,函数体里会调用上面的add_new_url函数。
has_new_url:这个好说,只要新容器里有url就返回真,反之为假。
get_new_url:提一个新的出来,然后把新的添加进旧容器(old_urls)即可。这里可能有个问题,没考虑到url的进入顺序就随便提取出来,如果需要有序的先进先出据说可以用Queue()库,里面有个这样的类可以用。
URL下载器,程序中为htmlDownloader
1class HtmlDownloader(object):
2 def download(self, url):
3 if url is None:
4 return None
5 response = urllib.request.urlopen(url)
6 if response.getcode() != 200:
7 return None
8 return response.read()
这个类只有一个函数,只要用urllib下载网页内容,然后返回即可。
URL解析器,程序中为HtmlParser
1class HtmlParser(object):
2 def parse(self, page_url, html_cont):
3 if page_url is None or html_cont is None:
4 return
5 soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
6 new_urls = self._get_new_urls(page_url,soup)
7 new_data = self._get_new_data(page_url,soup)
8 return new_urls, new_data
9 def _get_new_urls(self, page_url, soup):
10 new_urls = set()
11 links = soup.find_all('a',href=re.compile("https://movie.douban.com/subject/"))
12 for link in links:
13 new_url = link['href'].split('/')[4]
14 new_full_url = "https://movie.douban.com/subject/" + new_url
15 new_urls.add(new_full_url)
16 return new_urls
17 def _get_new_data(self, page_url, soup):
18 if page_url == "豆瓣电影":
19 res_data = {'url':"https://movie.douban.com/",'pic_url':"无",'title':"首页",'year':"无",'star':"无"}
20 return res_data
21 else:
22 items = ['导演', '编剧', '主演', '类型', '片长', '制片国家/地区']
23 info = {}
24 info['影片简介'] = [x for x in soup.find('div', class_/="related-info").find('div').find('span').get_text().split('\u3000') if len(x) > 40]
25 info['影片标题'] = soup.find("title").get_text().split(' ')[8]
26 info['豆瓣评分'] = soup.find('strong', class_="ll rating_num").get_text()
27 info['电影年份'] = soup.find('span', class_="year").get_text()[1:5]
28 info_x = soup.find('div', id="info")
29 for item in info_x.get_text().split('\n'):
30 if item != '' and item != ' ':
31 if item.strip().split(': ')[0] in items:
32 info[item.strip().split(': ')[0]] = item.strip().split(': ')[1]
33 return info
顾名思义就是把上面网页下载器的下载内容进行解析,涉及俩块,一块是把网址url进行爬取下来汇集成集合然后丢给上面的add_new_urls进行批量添加;一块是解析页面的内容,这块的内容是比较重要的,因为如果要用这个框架去爬取其他网页,你需要去看目标网页的网页结构,有针对性的进行更改,这里以豆瓣为例,我来说一下我爬取豆瓣电影的信息是如何来写这块的。
parse:就是这个类的主函数,它有两个传入参数page_url和html_cont,前面一个好理解就是这个页面的url,另外一个就是上面下载器返回的网页内容,可以理解为原始的网页内容,这个函数需要做的就是先用beautifulsoup函数进行解析,然后查找出网页上的目标url(_get_new_urls),进行下一步爬取,然后找出目标的网页内容(_get_new_data)。
_get_new_urls:获取新的url集合,这里以豆瓣电影为例,说明这个网站的页面的url怎么抓取。豆瓣电影的url相对来说比较简单,一部电影的url里都有特定的格式,例如这部电影,基本都是以“movie.douban.com/subject”构成,所以我们只需在网页中抓取“movie.douban.com/subject”格式的网址即可,但是有个问题,抓取的时候会出现下面红圈出来的url,这时我们就需要进行字符串的处理,只需把后面那段数字取出来,然后合成新的url即可。
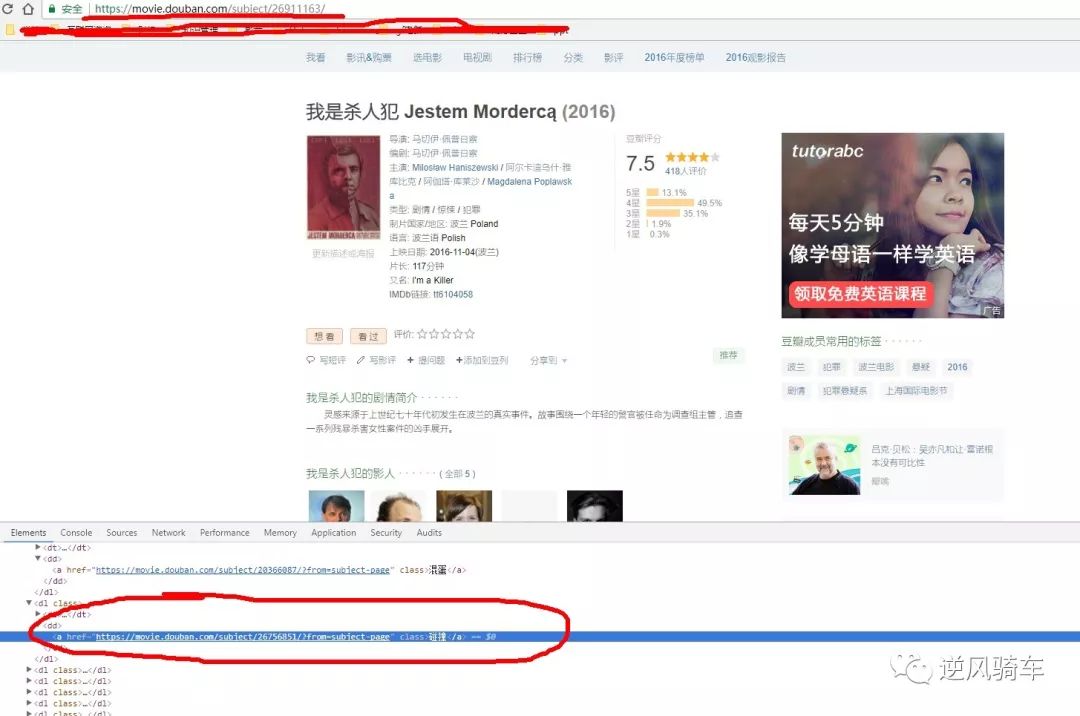
_get_new_data:获取内容,这块是整个框架比较灵活的一部分。由于我会从豆瓣电影首页开始随机漫步的形式进行不特定的电影进行爬取,所以我首先需要判断这个网页是不是首页,如果是首页的话,首页的内容不重要,我们只要那个页面的url。如果是具体的每一部电影页面,那就需要根据我们需要的内容对网页结构进行分析,然后写相应的节点,这点对于入门级选手来说比较难,我花的时间比较多也是在这一块,我的经验是找最简单的节点,例如要找导演,就找图中块对应的div id=“info” 节点,这样下来的就是全部的信息,然后再进行get_text()获取节点的文字信息,这时就可以顺便锻炼一下字符串的操作了。还有就是有明显的信息的节点,例如标题,就是title的节点。
Main类,程序中为SpiderMain类
1class SpiderMain(object):
2 def __init__(self):
3 self.urls = UrlManager()
4 self.downloader = HtmlDownloader()
5 self.parser = HtmlParser()
6 def craw(self,root_url):
7 count =1
8 self.urls.add_new_url(root_url)
9 summary = []
10 while self.urls.has_new_url():
11 try:
12 new_url = self.urls.get_new_url()
13 print('craw %d : %s' % (count,new_url))
14 html_cont = self.downloader.download(new_url)
15 new_urls, new_data = self.parser.parse(new_url,html_cont)
16 self.urls.add_new_urls(new_urls)
17 pic_title = new_data['影片标题'] + ' ' + new_data['豆瓣评分'] + ' ' + new_data['电影年份']
18 pic_path = "C:\\Users\\Desktop\\baike_spider\\豆瓣图片\\"+pic_title+".jpg"
19 pic = requests.get(new_data['pic_url'], timeout=10)
20 p = open(pic_path,'wb')
21 p.write(pic.content)
22 p.close()
23 summary.append(new_data)
24 if count == 10000:#设置爬取多少部电影的信息
25 break
26 count = count + 1
27 except:
28 print('craw '+str(count)+' failed')
29 count = count + 1
30 items = ['电影年份', '豆瓣评分', '影片标题', '影片简介', '导演', '编剧', '主演', '类型', '片长', '制片国家/地区']
31 table = {}
32 for item in items:
33 total = []
34 for movie in summary[1:]:
35 if item in movie.keys():
36 total.append(movie[item])
37 else:
38 total.append('')
39 table[item] = total
40 data_output = DataFrame(table)
41 data_output.to_csv('C:\\Users\\dell\\Desktop\\爬虫\\豆瓣电影\\电影信息\\data.csv') #输出电影信息的目录这个类是对上面几个组成部分的封装,因此该类的实例需要对上面的各部分进行初始化,然后进行抓取是craw函数,这里我还用requests添加抓取电影海报的方法,感兴趣的可以看看我的代码。其他的没什么好说的,保存信息之类百度可以查找到。
1if __name__ == "__main__":
2 root_url = "豆瓣电影"#网页自动变成中文连接,启动时输入movie.douban.com
3 obj_spider = SpiderMain()
4 obj_spider.craw(root_url)
End
每天10分钟,轻松学习fintech,如有不懂及其他想法,欢迎私信交流,后续将发布量化金融的相关研究,敬请关注!
以上是关于分享一个爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章
分享《精通Python爬虫框架Scrapy》中文PDF+英文PDF+源代码
分享《精通Python爬虫框架Scrapy》中文PDF+英文PDF+源代码