PyTorch 深度剖析:并行训练的 DP 和 DDP 分别在啥情况下使用及实例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 深度剖析:并行训练的 DP 和 DDP 分别在啥情况下使用及实例相关的知识,希望对你有一定的参考价值。
参考技术A作者丨 科技 猛兽
编辑丨极市平台
这篇文章从应用的角度出发,介绍 DP 和 DDP 分别在什么情况下使用,以及各自的使用方法。以及 DDP 的保存和加载模型的策略,和如何同时使用 DDP 和模型并行 (model parallel)。
PyTorch 提供了几种并行训练的选项。
Data Parallel 这种方法允许我们以最小的代码修改代价实现有1台机器上的多张 GPU 的训练。只需要修改1行代码。但是尽管 Data Parallel 这种方法使用方便,但是 Data Parallel 的性能却不是最好的。我们先介绍下 torch.nn.DataParallel 这个 PyTorch class。
定义:
CLASS torch.nn.DataParallel (module,device_ids=None,output_device=None,dim=0)
torch.nn.DataParallel 要输入一个 module ,在前向传播过程中,这个 module 会在每个 device 上面复制一份。同时输入数据在 batch 这个维度被分块,这些数据会被按块分配在不同的 device 上面。最后形成的局面就是:所有的 GPU 上面都有一样的 module ,每个 GPU 都有单独的数据。在反向传播过程中,每一个 GPU 上得到的 gradient 会汇总到主 GPU (server) 上面。主 GPU (server) 更新参数之后,还会把新的参数模型参数 broadcast 到每个其它的 GPU 上面。
DP 使用的是 Parameter Server (PS) 架构。 Parameter Server 架构 (PS 模式) 由 server 节点和 worker 节点组成,server 节点的主要功能是初始化和保存模型参数、接受 worker 节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数。
worker 节点的主要功能是各自保存部分训练数据,初始化模型,从 server 节点拉取最新的模型参数 (pull),再读取参数,根据训练数据计算局部梯度,上传给 server 节点 (push)。
PS 模式下的 DP,会造成负载不均衡,因为充当 server 的 GPU 需要一定的显存用来保存 worker 节点计算出的局部梯度;另外 server 还需要将更新后的模型参数 broadcast 到每个 worker,server 的带宽就成了 server 与worker 之间的通信瓶颈,server 与 worker 之间的通信成本会随着 worker 数目的增加而线性增加。
所以读完了以上的分析,自然而然的2个要求就是:
下面是2条重要的注意信息:
参数定义:
使用:
这一节通过具体的例子展示 DataParallel 的用法。
1) 首先 Import PyTorch modules 和超参数。
2) 设置 device。
3) 制作一个dummy (random) dataset,这里我们只需要实现 getitem 方法。
4) 制作一个示例模型。
5) 创建 Model 和 DataParallel,首先要把模型实例化,再检查下我们是否有多块 GPU。最后是 put model on device:
输出:
6) Run the Model:
输出:
以上就是 DataParellel 的极简示例,注意我们并没有告诉程序我们要使用多少块 GPU,因为 torch.cuda.device_count() 会自动地计算出当前的所有可用的 GPU 数,假设电脑里面是8块,那么输出就会是:
Distributed Data Parallel 这种方法允许我们在有1台或者多台的机器上分布式训练。与 Data Parallel 的不同之处是:
我们先介绍下 torch.nn.parallel.DistributedDataParallel 这个 PyTorch class。
定义:
CLASS torch.nn.parallel.DistributedDataParallel (module,device_ids=None,output_device=None,dim=0,broadcast_buffers=True,process_group=None,bucket_cap_mb=25,find_unused_parameters=False,check_reduction=False,gradient_as_bucket_view=False)
torch.nn.DistributedDataParallel
torch.nn.DataParallel 要输入一个 module ,在模型构建的过程中,这个 module会在每个 device 上面复制一份。同时输入数据在 batch 这个维度被分块,这些数据会被按块分配在不同的 device 上面。最后形成的局面就是:所有的 GPU 上面都有一样的 module,每个 GPU 都有单独的数据。在反向传播过程中,每一个 GPU 上得到的 gradient 会被平均。
使用这个 class 需要 torch.distributed 的初始化,所以需要调用 [torch.distributed.init_process_group()](https://link.zhihu.com/?target=https%3A//pytorch.org/docs/stable/distributed.html%23torch.distributed.init_process_group) 。
如果想在一个有 N 个 GPU 的设备上面使用 DistributedDataParallel,则需要 spawn up N 个进程,每个进程对应0-N-1 的一个 GPU。这可以通过下面的语句实现:
i from 0-N-1,每个进程中都需要:
为了在每台设备 (节点) 上建立多个进程,我们可以使用 torch.distributed.launch 或者 torch.multiprocessing.spawn 。
如果你在一个进程中使用 torch.save 来保存模型,并在其他一些进程中使用 torch.load 来加载模型,请确保每个进程的 map_location 都配置正确。如果没有 map_location,torch.load 会将从保存的设备上加载模型。
几点注意:
参数定义:
这一节通过具体的例子展示 DistributedDataParallel 的用法,这个例子假设我们有一个8卡 GPU。
1) 首先初始化进程:
2) 创建一个 toy module,叫它 ToyModel,用 DDP 去包裹它。注意,由于 DDP 在构造函数中把模型状态从第rank 0 的进程广播给所有其他进程,所以我们无需担心不同的 DDP 进程从不同的参数初始值启动。PyTorch提供了 mp.spawn 来在一个节点启动该节点所有进程,每个进程运行 train(i, args) ,其中 i 从0到 args.gpus - 1 。所以有以下 code。
执行代码时,GPU 数和进程数都是 world_size。
当使用 DDP 时,我们只在一个进程中保存模型,然后将其加载到所有进程中,以减少写的开销。这也很好理解,因为所有进程从相同的参数开始,梯度在后向传递中是同步的,因此,所有进程的梯度是相同的。所以读者请确保所有进程在保存完成之前不要开始加载。此外,在加载模块时,我们需要提供一个适当的 map_location 参数,以防止一个 process 踏入其他进程的设备。如果缺少 map_location,torch.load 将首先把 module 加载到 CPU,然后把每个参数复制到它被保存的地方,这将导致同一台机器上的所有进程使用同一组设备。
有关模型并行的介绍可以参考:
DDP 也适用于 multi-GPU 模型 。DDP 包裹着 multi-GPU 模型 ,在用海量数据训练大型模型时特别有帮助。
当把一个 multi-GPU 模型 传递给 DDP 时,device_ids 和 output_device 不能被设置。输入和输出数据将被应用程序或模型 forward() 方法放在适当的设备中。
参考:
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
https://pytorch.org/docs/stable/notes/ddp.html
pytorch分布式训练(DataParallel/DistributedDataParallel)
一、模型并行与数据并行
并行训练分为模型并行和数据并行:
- 模型并行:由于网络过大,将网络拆分成几个部分分别在多个GPU上并行训练;
- 数据并行:将batch中的数据拆分为多份,分别在多个GPU上训练。
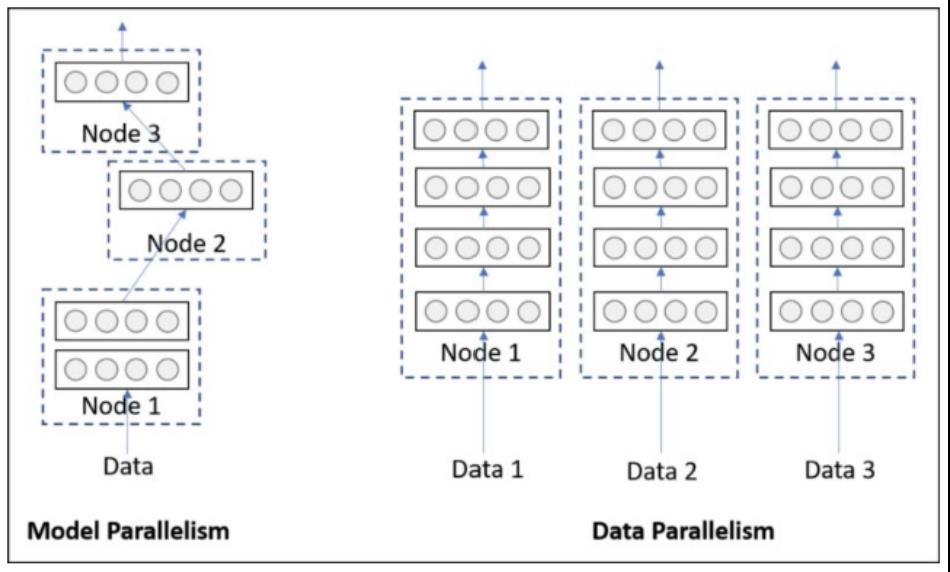
二、数据并行nn.DataParallel(DP)和DistributedDataParallel(DDP)的区别:
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题。
- 参数更新的方式不同:
1)DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将平均梯度 broadcast 到所有进程后,各进程用该梯度来独立的更新参数。
2)而 DP是梯度汇总到GPU0,反向传播更新参数,再将模型参数广播给其他剩余的GPU。
由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个 optimizer,对各个GPU上梯度进行求平均,而在主卡进行参数更新,之后再将模型参数 broadcast 到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。
- DDP支持 all-reduce(指汇总不同 GPU 计算所得的梯度,并同步计算结果),broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信,缓解了进程间通信有大的开销问题。
详细知识参见下面链接:
 https://www.cnblogs.com/yh-blog/p/12877922.html
https://www.cnblogs.com/yh-blog/p/12877922.html以上是关于PyTorch 深度剖析:并行训练的 DP 和 DDP 分别在啥情况下使用及实例的主要内容,如果未能解决你的问题,请参考以下文章
pytorch分布式训练(DataParallel/DistributedDataParallel)
pytorch分布式训练(DataParallel/DistributedDataParallel)
[理论+实操] MONAI&PyTorch 如何进行分布式训练,详细介绍DP和DDP
[理论+实操] MONAI&PyTorch 如何进行分布式训练,详细介绍DP和DDP