pytorch分布式训练(DataParallel/DistributedDataParallel)
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch分布式训练(DataParallel/DistributedDataParallel)相关的知识,希望对你有一定的参考价值。
一、模型并行与数据并行
并行训练分为模型并行和数据并行:
- 模型并行:由于网络过大,将网络拆分成几个部分分别在多个GPU上并行训练;
- 数据并行:将batch中的数据拆分为多份,分别在多个GPU上训练。
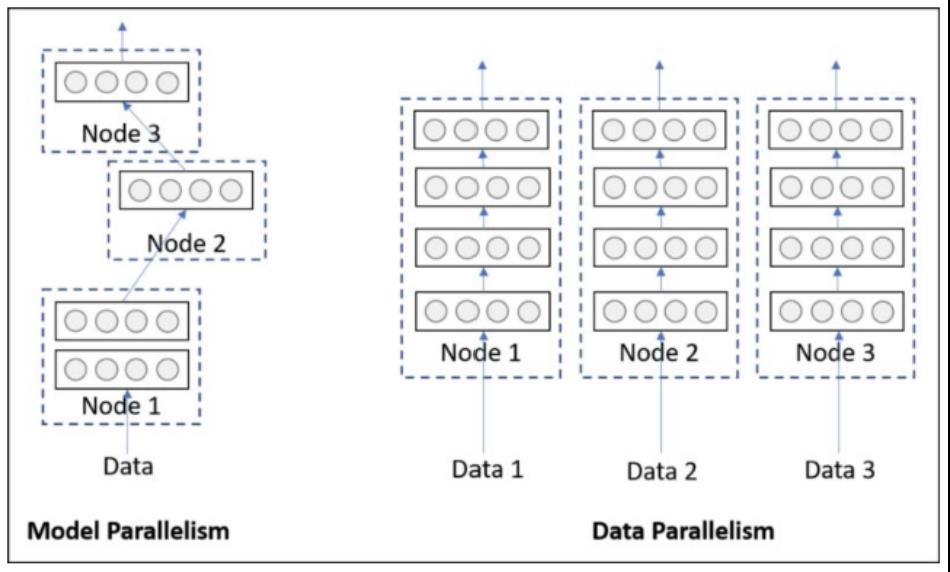
二、数据并行nn.DataParallel(DP)和DistributedDataParallel(DDP)的区别:
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题。
- 参数更新的方式不同:
1)DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将平均梯度 broadcast 到所有进程后,各进程用该梯度来独立的更新参数。
2)而 DP是梯度汇总到GPU0,反向传播更新参数,再将模型参数广播给其他剩余的GPU。
由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个 optimizer,对各个GPU上梯度进行求平均,而在主卡进行参数更新,之后再将模型参数 broadcast 到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。
- DDP支持 all-reduce(指汇总不同 GPU 计算所得的梯度,并同步计算结果),broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信,缓解了进程间通信有大的开销问题。
详细知识参见下面链接:
pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel - fnangle - 博客园pytorch的并行分为模型并行、数据并行 源码详见我的github: TextCNN_parallel,个人总结,还有很多地方理解不到位,求轻喷。 左侧模型并行:是网络太大,一张卡存不了, https://www.cnblogs.com/yh-blog/p/12877922.html
https://www.cnblogs.com/yh-blog/p/12877922.html
以上是关于pytorch分布式训练(DataParallel/DistributedDataParallel)的主要内容,如果未能解决你的问题,请参考以下文章