TiDB 的 Golang 实践
Posted GoCN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB 的 Golang 实践相关的知识,希望对你有一定的参考价值。
今天讲一下 Go 在我们 TiDB 的应用。我先自我介绍一下,我2012年自己创业做基础架构方向的创业,但是没有做起来,然后去了360基础架构组搞 mysql 的开源中间件。后来觉得中间件这个方案是一个会受到限制的方案,于是我们就开始探索可能需要像NewSQL 的东西。再后来发现 TiDB 也在做同样的事情,所以就加入了 TiDB。我今天主要讲 TiDB 从测试到优化。
图1
大家知道做数据库非常难,做单机数据库就已经很艰难了如果做一个分布式的,而且是带SQL、带事务的数据库,更是难上加难。对于我来说在做 TiDB 的过程中觉得最难的一点,就是怎么确保我们写的代码是对的。我们在内部将测试分很多块,一个是最简单的单元测试,还有集成测试,都是持续在跑。比如说,我们在 Github 提交一个代码就会跑我们的单元测试和集成测试,每天和每个星期跑的测试量不一样,除了这些我们还有一个叫薛定谔的测试平台待会我会给大家介绍一个 Failpoint 的测试框架,最后会讲讲我们怎么做 TiDB 内存上的优化,演讲的过程就像做软件的过程,我们先把事情做正确,再把事情做快。
我们是一个 toB 的公司。toB 公司跟互联网公司不一样,我们的试错成本很高,我们不能像那些互联网公司一样上线之后,让客户给测或者有灰度策略。我们不能做这些事情,所以我们内部做了很多测试相关的事情。
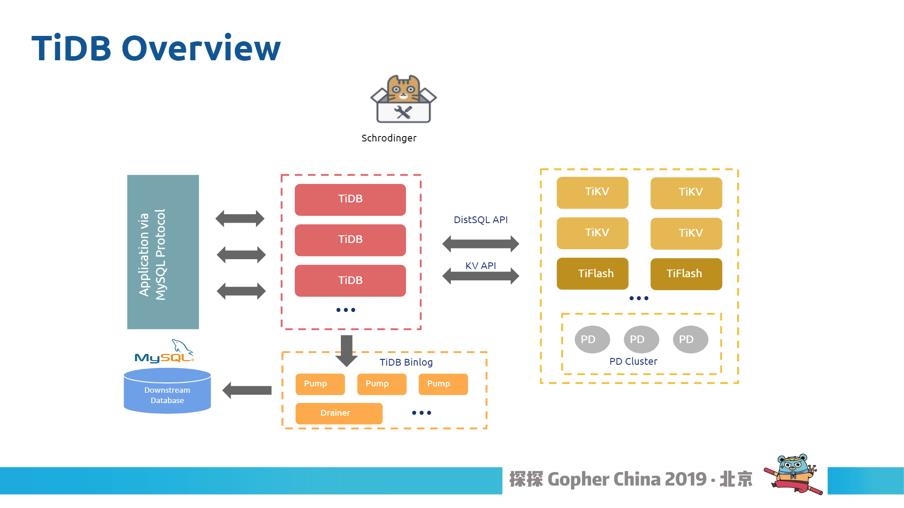
图2
这个是我们主要的产品概览。TiDB 可以认为是 SQL的引擎,可以发给存储,存储分两块,一个是 TiFlash,一个是TiKV,这就是我们的行存和列存。PD 是做数据调度的部分,大家可以看到,Go 用在除了存储外的所有组件,包括 PD、TiDB 、Binlog、还有周边的 k8s、薛定谔等。
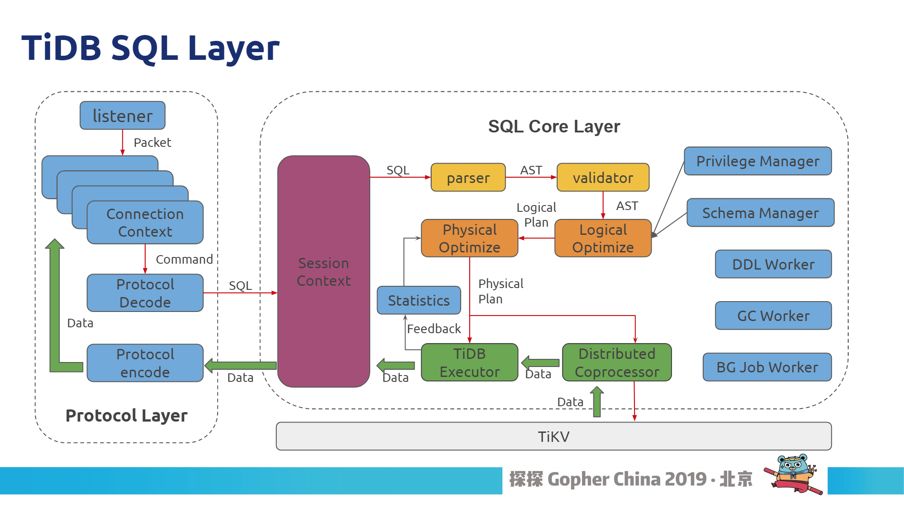
图3
给大家讲一下 TiDB 的 SQL Layer 架构。首先从左边看过来是一个 SQL,它先解析协议,拿出来 SQL 以后进行 Parse,解析成一个一个的 AST 树,然后进行改写,改写变成我们内部表示的一个Logical Plan 的树形结构。然后我们会做两个事情,先对这个树做一个逻辑的优化,逻辑优化就是对它做关系代数上的等价转化,这里还不涉及走哪个执行路径。之后到了物理优化,物理优化就会找出比较优的路径,比如是否走索引,是否直接扫表等等,这里会通过统计信息里面的概要信息来计算出一个代价,来选择路径,之后下面就是一个分布式的执行器,当然还有一些别的模块。这个 SQL Layer 是非常复杂的东西,要实现整个 SQL 的逻辑有很多组合。那么我们怎么测试这个复杂的东西呢?

图4
我们在分布式系统里面遇到的一些测试问题,这些问题可能出现在所有的模块,不止是我们自己写的模块,它有可能遇到磁盘坏了、内核的Bug、网络断了、CPU 有问题、包括时钟有问题等我们都遇到过;软件层面的问题就更多了,包括我们自己写代码的 Bug、、协议栈出现 Bug 等。我们怎么办呢?

图5
我们会引入一个随机的错误注入的框架,它叫做 Schrodinger(薛定谔平台),它是可以通过配置文件来选现在要组建的集群,比如说选多少个 CPU、多少个内存、运行几个TiDB 节点、几个PD节点,它会帮我把配置的集群拉起来,我们跑这些测试的过程中会注入一些随机的错误,我们通过这个平台发现了非常多之前自己测试时没有意识到的问题。
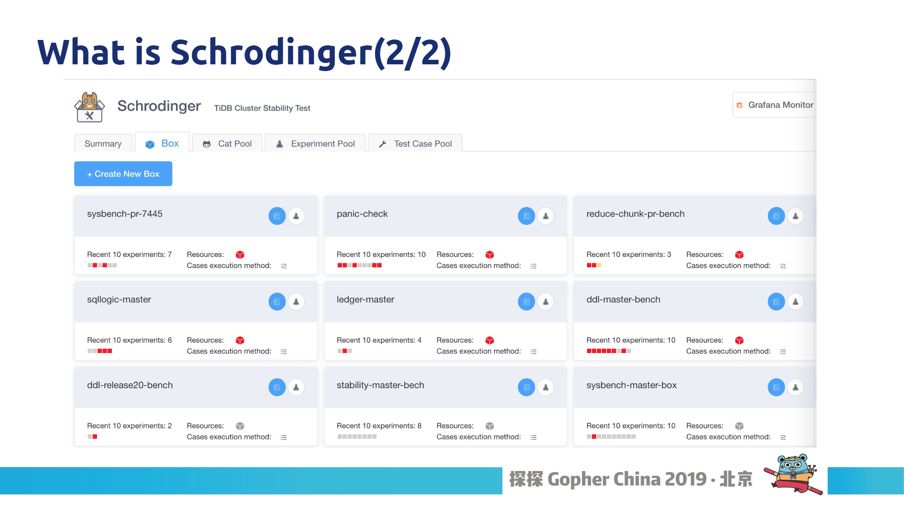
图6
这个就是我们的界面,我们通过 Create new box 就可以启动一个测试,一旦出问题就会汇报回馈给我们,。有非常非常多的测试。,Schrodinger是一个可以随机注入错误的平台,这个错误是不能预知的,。Schrodinger 很多时候会帮我们完成随机测试。那么对于一些确定性的测试方案该如何注入呢?

图7
我们在 Go 里面注入一些埋点。Failpoint 是指比如说一个正常函数正常返回是下面这个 Default 字符串,那我们注入一个 failpoint。这里有一个注释,最后会有一个 Return SomeFuncStringDefault 的语句,如果我们把它激活,他在函数进来就会返回这个值。有这个东西,我们就可以在关键路径注入任意错误,包括可以随机触发,有概率性的触发这个事情都可以做到。为什么要有这样一个 Failpoint 的东西呢?就是因为有一些我们已经确认过会触发某些问题的场景,比如说在客户那里或者在薛定谔我们在自己工作中遇到一些问题,我们已经查明问题,就需要把它加入确定性测试中,保证我们以后改动不会再出现这个问题(回归测试),这个时候我们需要借助于 Failpoint。原因一方面就是因为随机性的问题很难重现,所以我们用这种方法重现,另一方面是我们自己想出来的问题不能通过薛定谔平台去随机注入,所以。Failpoint 是薛定谔测试的一个补充。

图8
我们之前很早的时候用 Go 注入,我们就是用 ETCD Gofail 注入。大家有用过吗?Failpoint 是 FreeBSD 里面最早用的东西,它是用 C 写的。Gofail 就是把它移植到 Go里面。,它是以注释的形式出现的,触发以后,会变成真正的代码。

图9
我们来看一个例子,这是在 TiDB 里的一段代码。比如说事务提交的时候我会遇到很多问题,这里注入一个 error,看看这个系统是不是跑对了。大家看一下 Gofail 其实写出来是不太可读的。如果变成下面这样呢?反正我估计没个10分钟看不懂写的是什么意思。

图10
那么,我们就想 Gofail 有什么问题?首先 Gofail 只能有一种写法,静态分析的工具像 IDE 是没办法分析代码,因为它并不认为你这个是代码,因为它在激活以前只是一段注释。还有通常写 Gofail,写完之后注释,要再回来改注释,测试一下再改回去,这个过程不太方便。还有一点就是因为 Gofail 是全局的测试,如果注入了 Failpoint,所有的代码直接到这里,都有可能被它触发,这个可能不是我想要的,因为我如果要的是一个并发测试,就要自己把握状态。

图11
如果你不小心改变这个代码,又想变回 注释,在你知道改动历史的情况下可以回退回去,如果不知道改动历史就会很麻烦,只能调取以前的代码出来,其实非常麻烦。针对这些问题我们实现了一个叫 Failpoint 的东西,现在已经开源了 。
接下来讲讲PingCAP 的 Failpoint 怎么做。

图12
TiKV 是用 rust 写的,用 rust 写 Failpoint 很容易,因为Rust里面有宏,预编译阶段打开关闭 FailPoint 很方便。在Go里面没有宏,也没有编译器的插件,如果用 Build Flags 不太优雅也不好写。首先说说 我们设计 Failpoint 的一些原则:Failpoint 肯定不能影响我们的正常代码,这是最重要的原则,还有就是希望这个代码可以看起来像正常的代码,像一个 rust 宏的形式存在,Go里面是没有宏的,大家看一下下边的这段代码,就是最简单的 Failpoint 注入错误的代码,首先左边是 Failpoint.name,他会告诉我们要触发哪一个 Failpoint,,这里以包的形式出现,就比较容易隔离函数的命名空间。但是上面的代码是没有办法给你真的注入一段代码的。

图13
我先讲怎么变成下面的形式,下面是转换之后的形式,它会判断你的 Failpoint 是不是要开启,如果开启就直接转移到下面去。我们会解析 GO 的代码文件,然后parse,会得到一堆AST的结构,最后拿到 callexpr,我们通过 parse 可以改写左边 IF 的 Statement。我们改造过的 AST 树,再写回文件进行复写,就变成下面的形式。
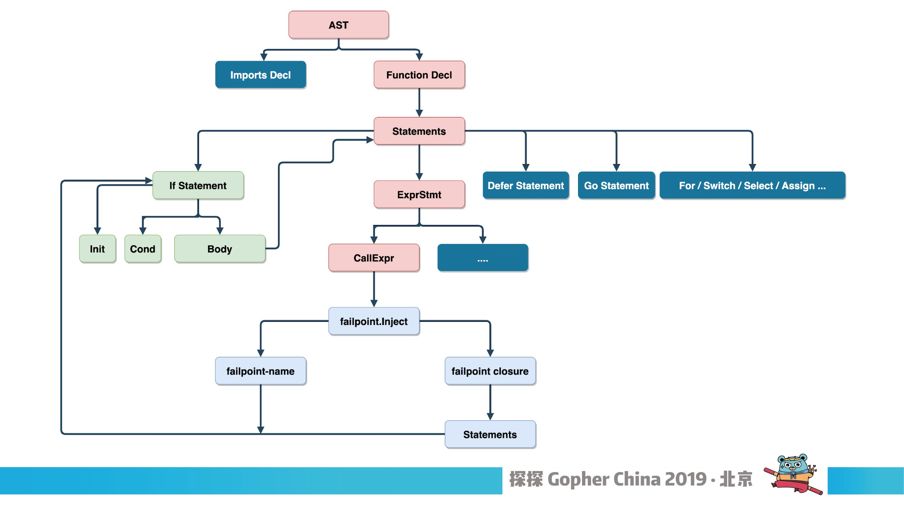
图14
我们注入的函数其实是一个标记 ,主要是为了方便我们 Parse 的时候认识它。
至于这里面为什么不直接用 Break,而是要用failpoint.Break() 的标记函数因为如果直接在代码里面写一个 Break,会变成 Break 外部的代码,所以只能用标记函数做。

图15
还有刚刚说到了,我们做的并行测试,可以通过 Context,可以对之前的 Context 进行 Hook,我们在里面写一些判断条件,比如说我们只允许某一些 Context 触发,就不会被其他的 test case 触发掉,然后把正常 Context 传进去,就可以进行并发测试。

图16
左边我们把所有列在里面,如果写一个 Failpoint,大概是左边这样的形式,右边就是变出来之后的,可以看到上面还有一个 label,如果不这样写,就会被外部代码识别掉,所以我们用标记函数做这个事情。Failpoint 刚才说了,注入是解析 Call Expr,所以可以让被函数调用的地方都注入。当然不只是这些地方,我们 test cases 里面写了非常多的 Context,大家永远不会觉得注入的地方我们也注入了。像这样,整个代码就会比较可读一点,因为首先 IDE 可以识别,包括语法错误可以直接被 IDE 检测。之前写 Gofail 不方便,导致大家不愿意去注入更多,现在比较方便可能大家就更愿意做这个事情了。

图17
图18
注入一个函数,会不会对最终的性能有影响?刚刚列出来的Maker函数,它其实是空函数,我们右边一个参数,进去的时候全是空的,并不会执行,正常情况下就是为了让我们 Parse 认识,找到并标记这个东西,改写了这么一个东西。通过看汇编也会发现这个空函数之后被直接消除。根本原因还是 GO 没有宏,我们如果用 C 来写这个东西,宏很容易做到这一点,GO 的话我们只能努力写得更优雅一些。到此,我把 failpoint 讲完了,推荐大家试用一下。
接下来讲一讲,我们内部怎么检测 Goroutine 泄露,Goroutine泄露不太常见,但是一旦出现,线上会出现很大的事故,而且不太好查。所以我们写代码的时候尽量早发现问题,不让问题往上层发展。

图19
什么样情况会导致Goroutine leak?

图20
中间的 GO 我们启动了 Goroutine,他会读 channel,这个 channel 不会被 Close,其实不是不会被 Close,而是被忘记 close,或者永远不会有数据进来了,它要从别的地方读数据,按理说我们代码读完了应该 Close 掉,那个时候就会退出,正常逻辑是这样。但是因为代码写得有疏漏,忘记 Close 的话 Goroutine 就会泄露掉。
我们通过 Runtime 的函数拿到现在正在跑的栈,我们认为Routine 跑的是正常的就滤掉。Testing 之前这个 T 之前把之前正在跑的Routine 全部记起来,按理说跑完了Test Cases 就应该把 Routine 全部回收。你跑下来,如果再调用Runtime.stack,发现之前出现了新的 routine,这大概是被泄露的 routine,那就不让它过我们的 CI, PR 不能合并。

图21
我讲到我们用了一些测试的方法,其实我们分布式数据库在客户那边还是会遇到一些小的问题,比如一些兼容性的问题。我们只能以更多的测试的类型把这些问题规避掉,但是我相信我们只能往这个方向努力,毕竟总会有一些问题被忽略。发现新的问题,一定要加上相应的测试,这样就会让这些问题越来越少。其实我们在 2.1 之后,在 3.0 发布之前,我们做了大量这样的事情,我们花非常多的时间在测试上面,包括构建薛定谔平台,包括内部 CI 的平台,我们花费了很多机器资源、人力做这个事情。

图22
往下讲,我们做完了这些稳定状态后才会考虑做我们性能优化的点。这里讲一下我们 2.0 里面带进来的一个大的优化。
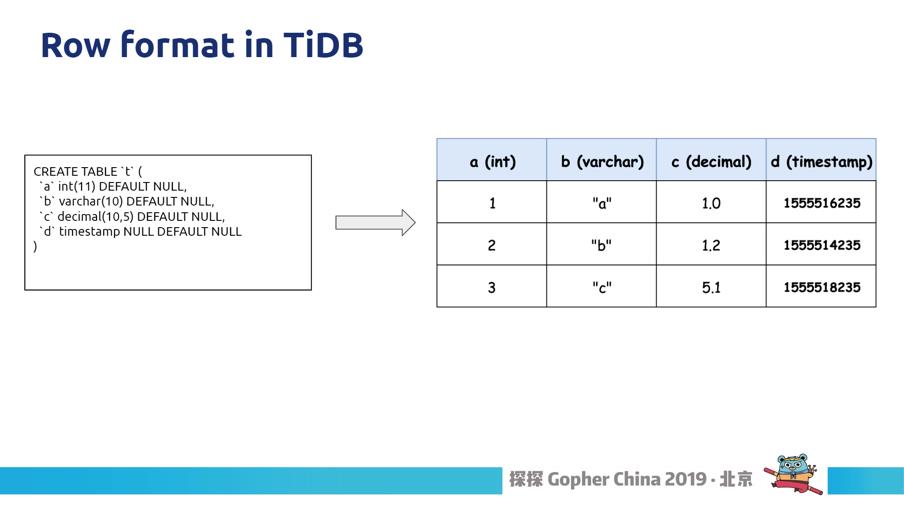
图23
我们先看这种表格,有四列,每一列都有不同的类型,逻辑上表现如果三行应该是这样的,我们想象如果在 Golang 可以表达一行一行吗?怎么用一个数据架构表示这一行,这个里面有各种类型的。以前我们的表达方式是这样的(图 23),我们一列就是 Datum 的结构体,这里包含了一个 K, K 就是表示什么类型,对于不同类型,比如是 Uint8就可以用第一个 field,如果是 uint16 就用第二个 field,如果是其它复杂类型就是下面的那个。这是最早想到的优化了,因为如果直接表达这么多类型很简单,最简单就是用 Interface{},但是 interface{} 性能不会太好。这个 Datum 有什么不好的地方呢?我们刚刚看到这个里面用了很多的无谓的空间开销,比如这是一个字节的整数,但是需要用 Datum 表示的话需要几十个字节,这个其实是非常大的浪费。还有一个比较不好就是如果我们是一个复合类型,是要拿到复合类型,需要在 Datum 里面要去做 Type Assertion。还有如果对一列做计算,每次去拿都是跳数组拿,对于 CPU Cache Miss 影响比较严重,这个对于 CPU 也不太友好。

图24
我们数据库计算当中大部分都是以列计算的,列与列之间的计算可以通过类似于并行的方式算出来一起输出。那我们代码怎么优化这个问题的?
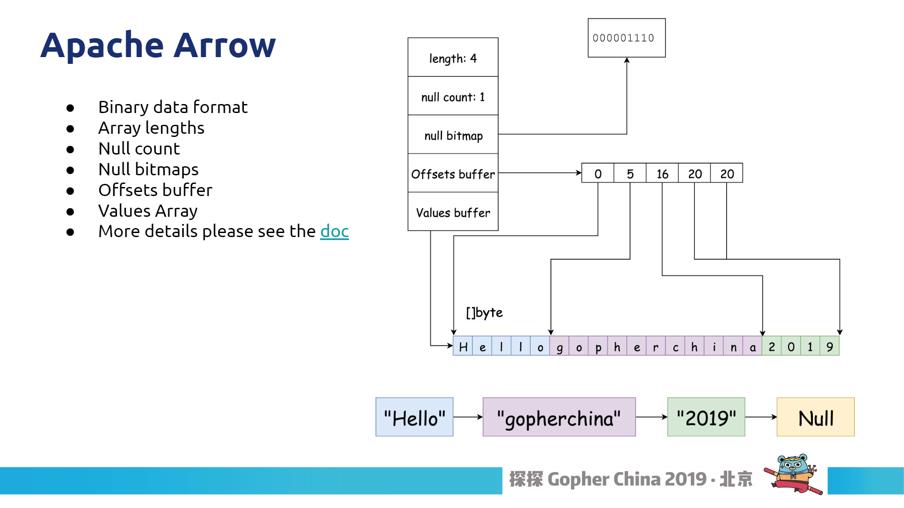
图25
这里给大家介绍一下叫做Apache Arrow 内存表达的一种格式,它是一个二进制格式,右边是一个概览图(图25),有一个长度标识会告诉我们现在 Arrow 里面会有几个元素,大家可以看到下面的例子有四个元素,所以量就是 4。它还有一个叫做 NULL bitmap,用来指示哪个位置是 NULL,主要是为了节省内存。最后是以二进制数组来保存下面的值,这个应用在很多 AP 的数据库格式里。

图26
这样个表达是比较紧凑的内存表达。那么我们如何以 Arrow 的内存表达变成我们 Golang 的代码?在 TiDB 里我们叫 Chunk,chunk 会有一组的 Column 的数组,每一个元素就是一列。大家可以看到(图 26),我标出来颜色一起的,就会是一列一起放在 Column 里面,我们看到这个里面会保存这一块内存里面 A 那一列所有的 1234 放在 Data 里面。如果是等长的,我们不需要 Offsets 这个数组,我们不用它,这样可以节省空间。B 那一列又是一个 Cloumn 的对象,这样组起来就可以构成内存的表达。Chunk 就是一块的意思,表达这一整块的所有东西,但实际下面是一列一列这么存的。

图27
大家可能会问你这个数据库里面如果有上亿行数据怎么存放?我们 Chunk 并不是把所有的数据放在里面,他会设置一个 Size,比如一个Chunk 最多只放 100 行,它是可以调 Size 的。大家都知道,GO 对性能最大的杀手就是不断的申请指针,这会造成非常大的影响,大家写代码的时候会容易忽略这个问题。但如果写数据库的话,这个问题会很明显,如果采用这种方式就可以在这样的场景下会有很大的性能提升、也可以节省非常多的时间。
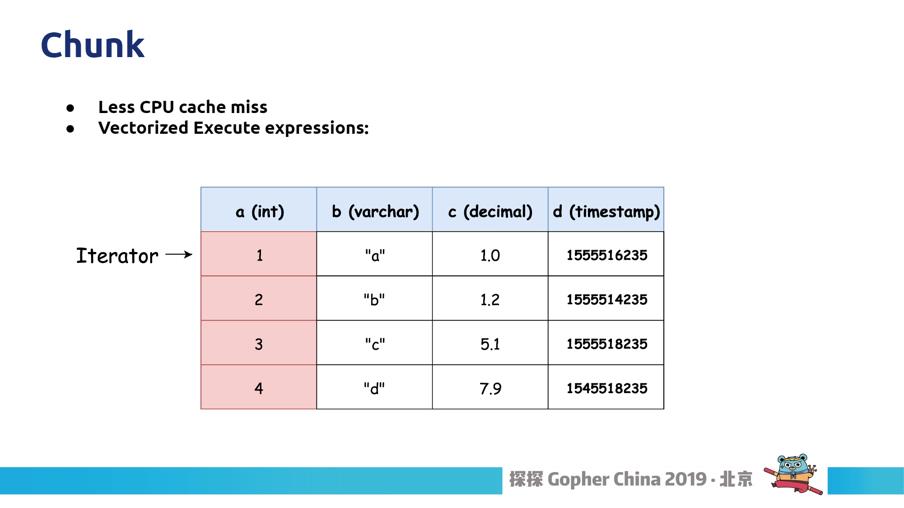
图28
使用在二进制的数组表达表示还有一个好处是,对于复杂的结构不用像刚才那样必须 type assertion 出来,对于二进制的数据直接用 Unsafe 就可以。这是一个很常规的操作,我们一段二进制数组可以变成任何类型,如果在 Go 里面做的话可以用 Unsafe 做这个事情,这样对于我们效率有很大的提升。

图29
还有一个值得讲的是向量化执行,以前我们的表达(图 28)是这样一行一行的过去,如果我要做 A+C 的场景,以前的情况我就必须得从 Data 数组拿 A 再拿 C,算完以后又要到下一行拿 A 这一列的数据,再往下跳,这样来回切换好多个数组,如果这个数组非常长的话,CPU 有可能会把你整个数组先弄到 Cache 里面,刚刚的行为就是一个很大的开销,而且没办法并行起来。如果我们做成刚刚说到 Chunk 的方式一列一列存,如果算 A+C,我在初期弄一个数组A+C 是一个数组,我对这一个数组一次性扫过去,把所有结果算出来,放到刚刚说的结果数组里面,最终的结果就出来了。这个就是向量化执行最基本的概念。
在 TiDB 里面也做了这个事情,包括我们 TiKV 模块也支持向量化执行。这里是我们 TiDB 的一段代码(图 29),这里的向量化执行是:通常计算都是一列一列来做,这个时候我们输入进来大家可以看到一列,它有一个迭代器,每个 NEXT 是改了下标,但是都是访问同一个数组,大家看这个图就会比较直观。
我今天分享的跟代码相关或者是实践相关的就这么多。但是我还想跟大家分享的就是我们做数据库的过程中或者做软件的时候跟互联网不太一样的地方,在这个过程中学到的一些经验教训。

图30
第一条要说的就是我们做事情之前先让事情做对,再考虑优化性能。大家知道性能优化一定会用比较 Cheek 的方式,你要是直接跟内存打交道,或者跟操作系统打交道,一旦把操作系统信息引进代码里面,一定会耦合你的代码,或者让你的代码比较复杂。这样肯定不利于你代码的稳定性或者测试的稳定性,刚开始是不好做的。所以我们只能从周边一些各种设施补全了,才能考虑做变更,因为只有做变更才有信心说,这个变更有一个回归测试,不会导致之前的代码失败掉。我只是举 Chunk 比较小的明显的例子,还有其他的例子没有分享。
还有在这个测试过程中我们会发现很多我们认为不符合预期的现象,如果不仔细调查这个现象,很多时候会被忽略掉。但是现在我们出现 Error,在薛定谔平台会直接把Error 发到邮箱,会强制你看 Error,必须把这个事情调查清楚且有一个说法,才可以继续运行起来。这种工作流程程在过去一两年让我们发现非常多隐含在我们代码里面长达几年的 Bug,它的现象表现出来很像是正常的网络故障,因为大家认为出现网络故障或者存储故障很常见,通常这种报错很容易被忽略,但是可能是隐含很大的问题,实际上很可能是代码 bug 导致的。
还有一个教训是测试是实践性的东西,怎么样的测试才是符合这个系统的。现在外部也有很多理论,包括 Chaos等方法,都需要对你的系统做一个深入了解之后做一个定制化。就像你会想到要注入一些随机的错误,你也可能会考虑到升级这一块也要有测试。
我们有一些客户会遇到可能升级之前没有问题但升级之后会有问题,因为升级是一个改动式的行为,所以升级的时候也要做一些相应的测试,保证升级之后旧数据在新的集群上能不能跑好。兼容性测试是个很大的话题,包括性能是否回退等等。
还有压测和并行测试,这一方面有很多问题是出现在边界条件的,你的整个系统无论哪一个模块,在出现能力到了一个边界的时候,就有可能有一些问题没有想到,对每一模块加压,来看它的行为对不对。
还有一个我觉得也很重要的一个测试的类型叫做稳定性测试。稳定性测试的意思就是说你的集群从零开始业务正常的写是不断扩张到几百 T 甚至到 PB 级,我们必须要保证写入的延迟或者读取的延迟不会因为扩张而导致很明显的下降。还有一个方面是系统本身集群容量比较稳定,但是主要的是 workload 是读,只要流量不上涨我们必须保证读是稳定,这就是稳定性测试。
因为我们的数据库是以统计信息作代价估算的,执行计划有可能随着集群的运行发生一些改变,这些改变会不会导致客户一些问题,我们也要加一些测试。
Q&A
提问:您好,问一下在生产环境下如何监控这个方面?
姚维:通常不会关注这个事情,通常关注的是内存。
提问:内存泄露?
姚维:可以算是 Goroutine泄露。等你发现的时候已经泄露很多了。两个指标:一个是数量,一个是内存大小。数量可能是对的,如果负载特别多,routine 数量当然多。你的内存正常情况下会一直上,但是不会再下来了,这个肯定是一种类型的泄露,当然内存也可能泄露。
提问:检查 goroutine 泄露检查得准吗?
姚维:我们 CI 是持续跑的,每一个修改都会跑 CI,被它跑出来的概率很大,一旦出现这个问题一定会查,必须确认我这个到底是 test case 导致误判断还是说是真的泄露。如果是误判断要修改 test case,如果泄露必须把 routine 回收,不能不回收。
提问:我想问一下,咱们数据库是分布式数据库吗?
姚维:对。
提问:分布式数据库不同的数据库之间修改一个数据,如何同步到别的数据库中呢?
姚维:我今天没有过多于介绍 TiDB,我简单的介绍了一下 TiDB 的架构,数据存储其实是存在 TiKV 的,是一个集群,是有状态的,它的数据像刚刚你说的,写到一个 A,并不会复制所有的存储节点,它是存储在我们叫做 Region 的逻辑单位上,就是写到Region上面去了,再由 Raft 协议来复制到不同的副本中。。
提问:你们这个 A 是用 Raft 协议的,用没有用分布式锁?
姚维:我们思路的实现是一个乐观的实现,是两个阶段提交的实现,可以认为是一个锁,但是并不是传统意义认为的等待锁。
提问:关于测试的问题。一个是 Failpoint 很有意思,打算试一试,有没有建议从什么地方开始加,很多地方都加了,我们一个项目对代码侵入还是比较多的,所以想问有没有建议?第二个你们平台有没有对于不同的配置随机产生不同配置的组合,然后提取做一些 test case。最简单的这个可以开源我们用吗?
姚维:这个随机有正在做。刚刚你说的 Failpoint 怎么注入可以看一下我们 TiDB 里面的测试代码,很容易搜到,搜关键词就是 Failpoint,就能搜到我们注入所有的代码。我们有一个 PR,是把我们的 Gofail 替换了 Failpoint。对于代码的侵入我是这么理解,我宁愿多写一点的代码,也不愿意代码真的在客户那里给我发现这个问题,我宁愿是这样。
提问:关于那位同学问过,既然你有 Rut,你怎么写,你关注是 UT 级别还是 Integration?
姚维:我们用了 Gofail,它可以通过 HTTP 接口触发,在集成测试也可以调 API 触发 Failpoint。测试之前可以先调 HTTP 接口,,它是比较完整的,也可以做集成测试。
提问:这个失败结果是事先手动写是吗?
姚维:就是你的方案本身是知道的。预期就是写 test case 知道你的 case 会失败。
提问:关于有可能本身代码有问题有思索,但是很常见是测试里面有问题,这种比较不容易复现?
姚维:我没有仔细想过这个。我没太听懂。
提问:你好,我想问一下数据表那一列数据只有 ABCD 单字符,突然修改某一列某一行数据,字符长了,把 A 改成 ABC,变成字串你这个Chunk 要变吗?
姚维:我们 Chunk 只是读要用,修改的时候其实不走 Chunk 。修改直接走 KV 接口,不会走 Chunk。Chunk 是因为有函数计算的时候用到 Chunk,拿数据需要大量的内存,所以我们写的时候不需要做这个。我们写的话直接就是 KV。提问:这个延伸下去,我一边改了,相当重新生成一份 Chunk,你这里改不是直接写这一个表,是写 KV,KV 写完了要重新出数据?
姚维:还是跟上面一样,如果需要修改列数据的话,Chunk 这个结构其实并不太适合
提问:我想了解一下 TiDB 计算方法的问题,PD 处理一个复杂的数据查询的时候,有没有集群计算的能力?
姚维:PD 为什么要处理复杂计算呢?
提问:我不是特别了解,我之前印象中 PD 是用来处理数据的查询。
姚维:查询是 TiDB 做的。你继续说。
提问:我就是想了解 TiDB 在处理一个非常复杂的查询的时候,会利用多台集群的计算能力吗?
姚维:
我们的计算是可以下推到存储节点去的,另外目前我们有一个引擎叫做 TiFlash,它可以处理更复杂的 AP 查询,目前 TiDB 的计算还是没有走 MPP 架构,还是在单个节点上计算。
提问:我想再问另外一个问题, TiDB 是否有同步 MySQL 的方案?
姚维:我们 binlog 组件会把修改都吐出来,格式不是 MySQL 的格式, 我们也可以把这个修改,给写入到下游 MySQL
提问:意思是自己解析 binlog。
姚维:我们已经有工具了,可以做这个事情。
重磅活动预告
Gopher Meetup 北京站即将开启。来自滴滴、阿里、京东、PingCAP的大咖讲师带来 Go 开发领域的一线实践经验分享,尽在9月7日,中关村软件园尚东数字山谷!
报名请戳:阅读原文
Go中国
扫码关注
国内最大、最活跃的 Go 开发者社区
以上是关于TiDB 的 Golang 实践的主要内容,如果未能解决你的问题,请参考以下文章