数据库分库分表那些事
Posted Qunar技术沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库分库分表那些事相关的知识,希望对你有一定的参考价值。
走过路过不要错过
王鹏,去哪儿网高级研发工程师,2017 年加入去哪儿机票事业部,主要从事后端研发工作,目前在机票事业部负责行程单、故障演练平台和公共搜索服务ES相关的研发和运维工作,个人对于分布式海量数据存储架构以及大数据有浓厚的兴趣。
背景:
最近工作在做Elastic Search 相关的服务的运维开发工作,从索引的类型来看主要的是对于订单的索引,国内、国际机票订单的各种维度的查询,简单的比如按照用户名查询订单列表,通过手机号查询订单列表,根据订单号查询订单信息等等。从查询的方式来看很多数据查询可以通过数据库分库分表来搞定,为什么要用索引的方式去查询呢?互联网公司海量的数据存储和查询都是采用什么技术呢?
海量数据存储几种方案
在互联网时代,每天海量的用户会产生海量的数据,比如:
用户表:亿级别总量
订单表:百万、千万级别/天
交易表:千万、亿级别/天
那我们是如何存储这么多数据的呢?有目前三种方案:
表分区
NoSQL/NewSQL
分库分表
一、表分区
表分区:数据库中的数据是以文件的方式存储在磁盘上,表分区就是将这些数据按照一定规则存储到不同的文件中。以mysql为例一张表对应三个文件,frm结尾存放表结构,myd结尾存储表数据,myi存储表索引。如果一张表数据量过大,myd 和 myi 文件就会变的很大,这时候我们利用表分区在物理上讲一张表的三个文件分割为许多小块,查询的时候就不用全部都查,查其中某一块就可以了。
这个方案貌似非常好,可以对查询透明,即使不知道这个表做了分区,也可以去使用它,那为什么这么多互联网公司没有采用这种方案呢?
1.无论是分成多少份文件毕竟还是一个Mysql的实例,所以这个实例的性能就限制了整体的负载能力,连接数,网络IO 以及TPS 都受单机的限制;
2.分区健设置不灵活,如果不走分区键,很容易出现全表锁。
所以分区的应用场景:并发量比较小,查询不多并且数据有明显的冷热之分的情况,比如操作日志类型的存储,完全可以按照时间维度切分,最近的日志可能更多的被查看,历史的很少被查看。
二、NoSQL/NewSQL
比较有代表性的 MongoDB/ES或者TiDB/RocksDB/LevelDB,无论是NoSQL还是NewSQL的情况,后台的存储都是采用非RDBMS的方式,TiDB底层采用了RocksDB来存储海量数据,存储上面的分布式这一层是用 Raft,MVCC以及上层的SQL解析,是TiDB团队自主开发的,相对于NewSQL。
RDBMS的 优点:
- RDBMS生态完善;
- RDBMS绝对稳定;
- RDBMS的事务特性;
- RDBMS 完善的运维体系以及人才储备;
Nosql的数据库出现没有多久,但是RDBMS数据库已经存在将近三十年,相关的体系完善,运维开发等各种资料文档齐全,而Nosql的数据库从各个方面都无法和RDBMS相提并论。
目前国内的绝大部分互联网公司都是以RDBMS数据库为主,Nosql或者NewSql数据库为辅,将一些离线的数据存储到这些数据库中进行批量的处理等操作,而像金融支付相关的业务基本都是存储到ORACLE/DB2数据库,开源的RDBMS的稳定性以及商业支持没有这两大厂商做的好,总而言之,Nosql数据库还是在处于一个快速发展的阶段,目前互联网公司都是尝试将一些不重要的业务接入这种性能更高的数据库来试验效果。
三、分库分表
分库分表是现在目前互联网公司的通用解决方案,原因很简单就是因为这种改造是可控的,底层还是基于RDBMS这套体系结构,整个DB的运维体系以及相关基础设施都是可重用的。
分库分表必然需要中间件来做这一层工作,而且希望对于客户端是透明的,但是目前还没有一个一统江湖的中间件,列举一些大公司的解决方案供大家参考:
阿里 TDDL DRDS (基于阿里云的RDS 做分库分表的中间件)
开源 sharding-jdbc
Atlas(Qihoo 360)
alibaba.cobar(是阿里巴巴(B2B)部门开发)
MyCAT(基于阿里开源的Cobar产品而研发)
Oceanus(58同城数据库中间件)
OneProxy(支付宝首席架构师楼方鑫开发)
vitess(谷歌开发的数据库中间件)
分为两大类型:
Client端分片
服务端代理模式
客户端分片架构
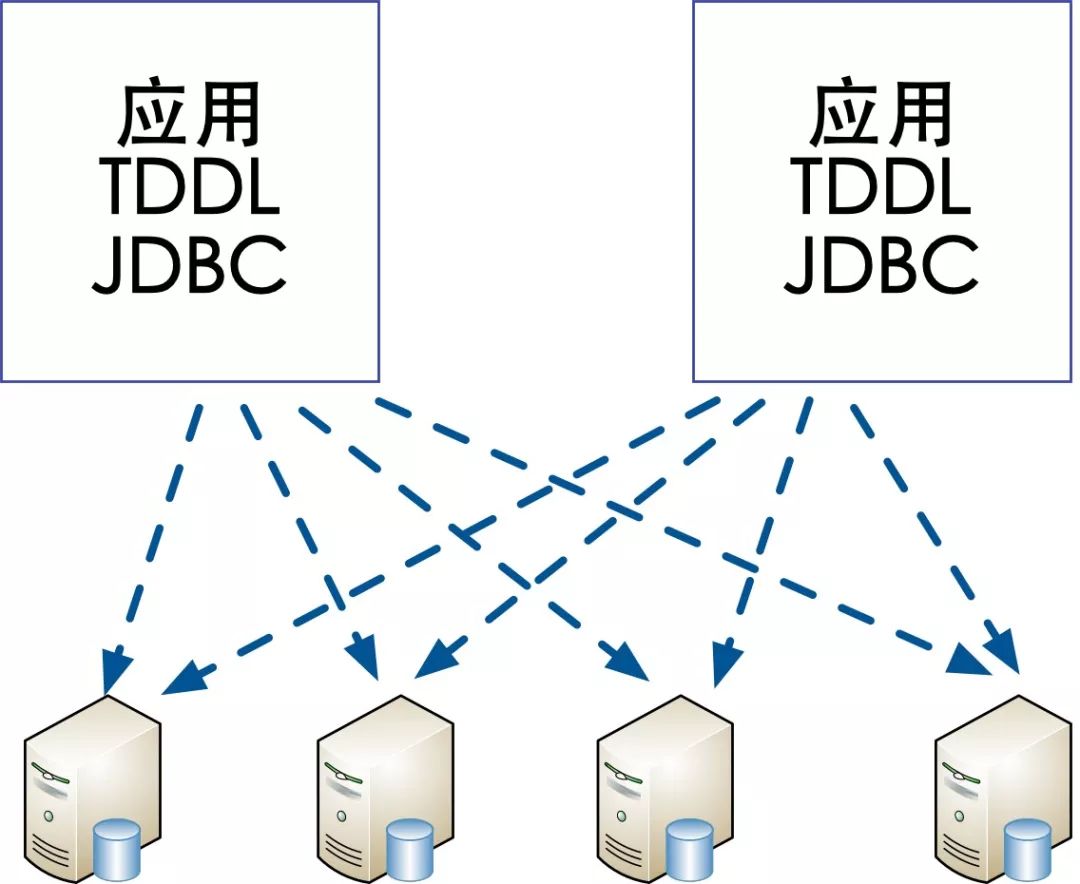
客户端分片架构
优点:
1.实现相对简单,分库分表中间件部署在各个应用作为组件形式存在。
缺点:
1.连接的管理是一个大问题,每个应用都需要创建对应每个数据库实例的连接池,当分库过多的时候连接的管理将是梦魇;
2.所有的路由策略配置到不同的应用,当要扩容的时候需要很多的设计才能实现平滑的扩容。
服务端代理模式
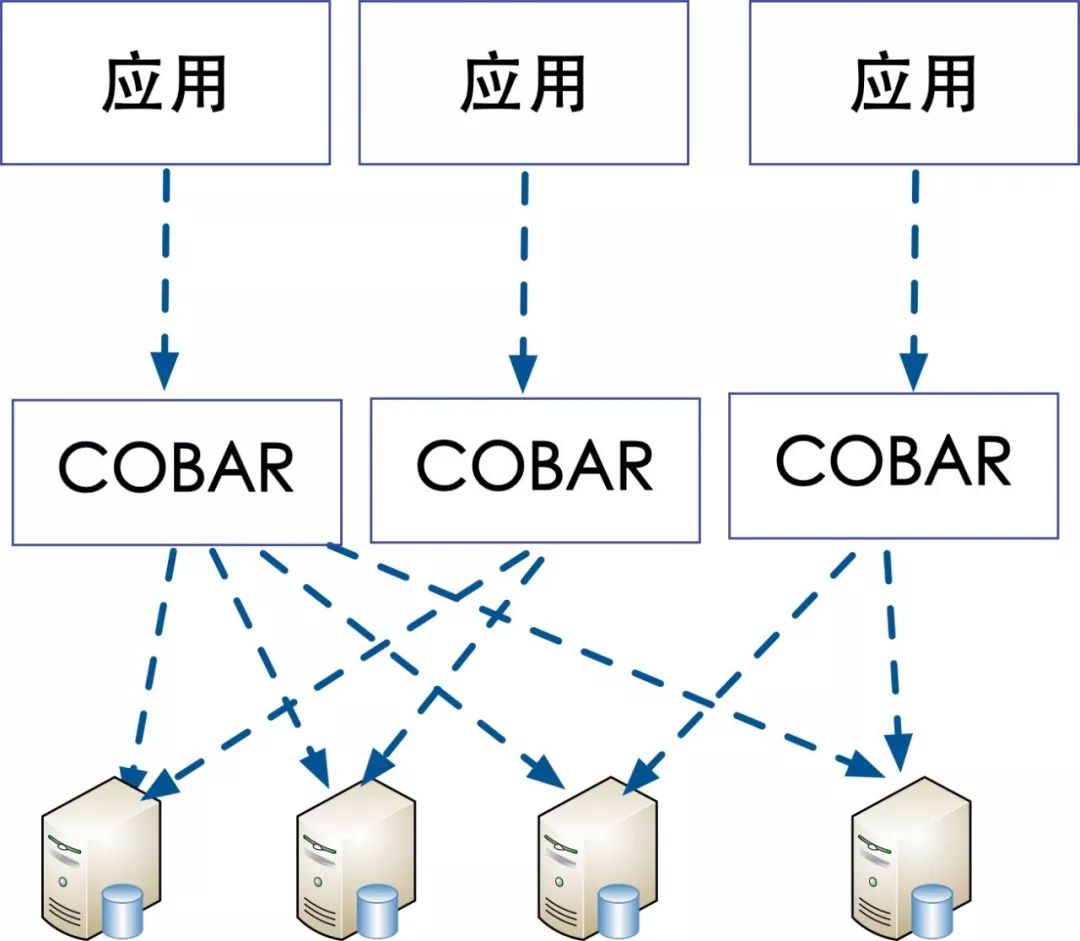
服务端分库架构
优点:
1.Proxy层管理所有与数据库实例的连接,这样能大量的降低连接的数量;
2.所有的路由策略统一配置在代理层,方便以后平滑的扩容、缩容。
缺点:
1.实现相对复杂,需要有单独的代理层服务代理所有客户端的请求,需要保证代理层的高可用,代理层的稳定性决定了整个系统的稳定性,访问数据库出现问题基本就是应用不可用的状态;
2.实现难度比较高,需要对SQL进行解析,解析后改写,需要对于Mysql协议有很深入的了解。
无论是服务端分库分表还是客户端分库分表,无外乎几个核心的步骤:SQL解析,SQL的改写,路由,执行,结果的归并。
根据不同的公司体量以及用途可以选择不同的中间件满足业务诉求,比如企业有一定历史数据的情况下,只是希望我可以存储更多的数据,写有一定压力的情况下可以选择客户端分片的模式,简单易维护。如果公司规模逐渐发展,应用越来越多,客户端分片的弊端就显现出来,那么就可以考虑切换到Proxy 服务端分库的模式,当然这种就需要专业的人员维护这一次层服务保证系统的高可用,数据连接层出现问题,影响还是非常大的!
说了不同方式的分库分表架构,那么接下来就要分析下目前的查询业务,来看下如何将现有业务进行分库分表,分库后我们应该如何查询这才是重点。
数据库分组架构和分片架构:
在谈分库分表的时候,首先明确几个概念:
数据库分组(Group):一主多从的数据库集群称为 “组”。
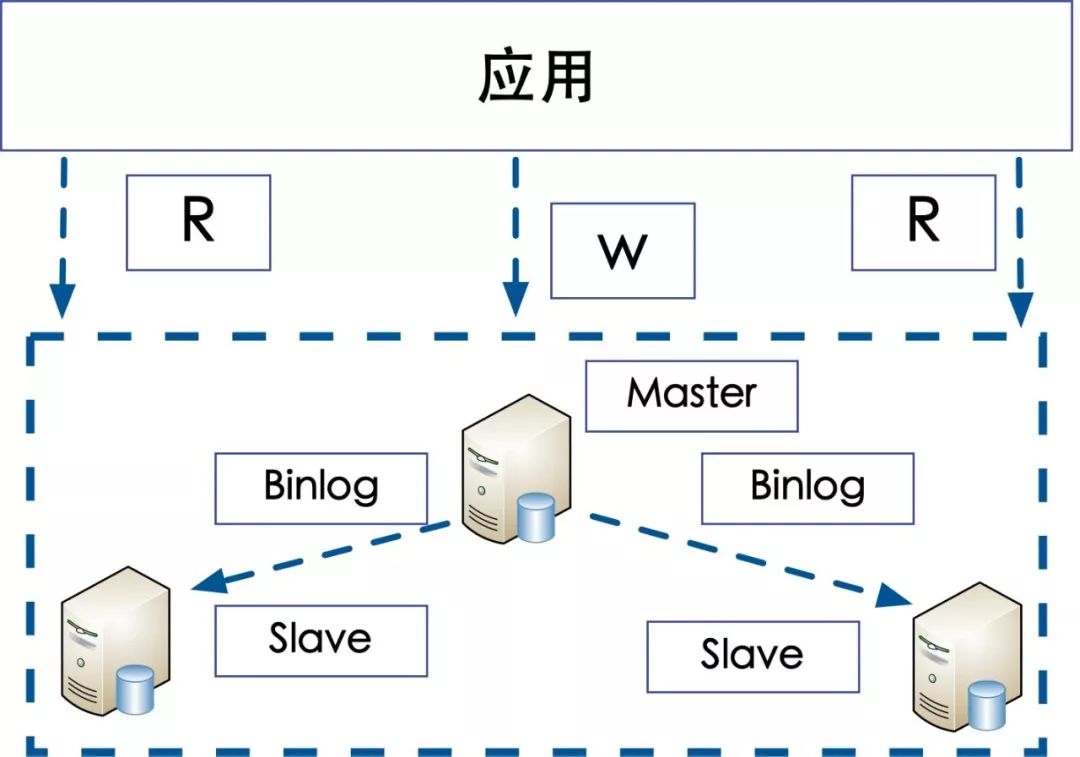
数据库分组架构
分组架构常见的是一主多从,主从同步,读写分离的数据库架构:
应用的写数据访问的是主库;
应用的读数据访问的事从库。
分组的数据库集群特点:
1.主从通过Binlog实时同步;
2.多个实例之间的数据库结构和数据完全相同。
分组的数据库集群解决的问题:
1.大部分互联网业务是读多写少,数据库的读往往是最先成为瓶颈的地方,所以这种分组架构解决的事读性能的问题;
2.线性的提升数据库的读性能;
3.消除读写锁冲突提升主库的写性能;
4.通过冗余提升读库的高可用。
数据库分片(Sharding):根据分片的字段(Sharding Column)将数据存储到不同的分片中去,各个分片中的数据是不一致的。
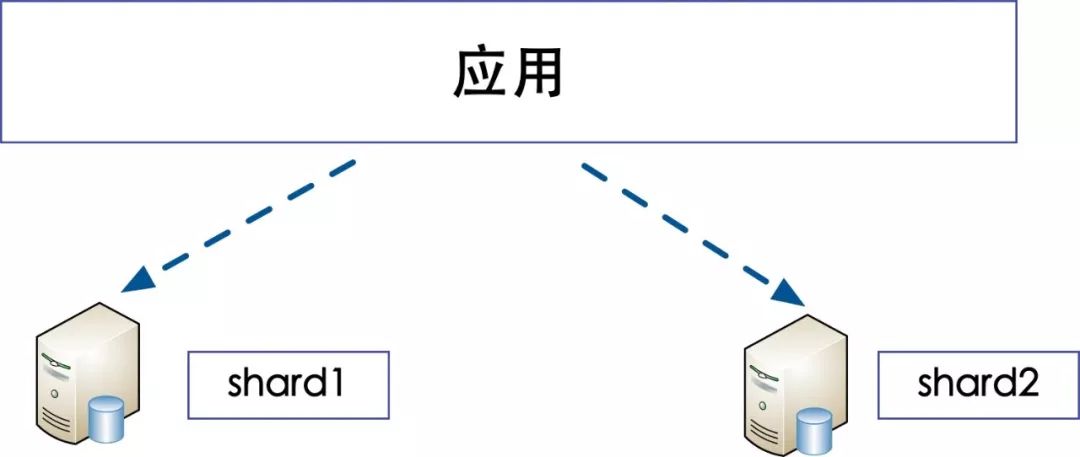
数据库水平分片
数据库分片架构:常见的场景是海量数据的存储,为了解决写压力过大的问题。
数据库分片架构的特点:
每个分片的数据结构相同,但是数据内容是不同的;
没有数据同步。
数据库分片架构解决的问题:
海量数据的存储问题;
业务高峰写压力过大的问题,通过分散写压力到不同的分片来解决问题。
常见的数据水平切分有两种方式:
1. 范围法 :就是将0-1kw 的数据放到一个库,1kw-2kw 放到第二个库,后边的以此类推;
优点:切分策略简单容易实现;
扩容简单只需要增加数据库节点即可;
缺点:Uid 必须是递增;
请求量不均,最新注册的用户和活跃的用户基本会集中在某个库上,所以导致服务器利用资源不均匀。
2. 哈希法:根据uid 对一个数值取模操作 讲数据分配到不同的节点。
优点:
切分策略简单,根据uid的hash值取模即可;
数据量和请求量均衡,Uid的生成策略是均衡的那么数据分布与请求也是均衡的。
缺点:
数据扩容比较麻烦,增加一个节点的书序需要对整个系统的数据进行迁移。
实战分库分表:
分库分表最重要的就是根据什么字段(Sharding Column)去划分不同的分片(Sharding),这个字段的选取非常的有讲究,首先要分析下整体的流量,看看你的业务那些的流量最大,之后通过这些大流量的API统计下执行的SQL语句,如果这些SQL语句都有一个条件是用户ID,那么我们就可以把用户ID作为我们的Sharding Column。这只是我们分库分表考虑的一个方面,根据业务的不同我们可以把分库分表的思路总结如下:
用户库

用户表
用户中心是一个网站最常见的业务,主要是提供用户注册、登录、个人信息的查询修改服务,核心的业务字段如上图所示:
用户表10亿数据量,如何水平拆分?
User(uid,uname,passwd,mobile,email,createtime)
业务需求
登陆 (请求量1%) where uname=xxx or mobile =xxx or email = xxx and passwd =xxx
查询 (请求量98%) where uid=xxx
查询弱密钥 where passwd=xxx
查询最近注册 order by create_time desc 0,10
主要有上边的几种业务诉求:
假设我们是按照用户的Uid进行分库的,那么另外的请求如何满足呢?
1.用户登录诉求,根绝用户名或者手机、邮箱 还有密码登录
根据各种用户的唯一ID登录这是我们最常见的需求,但是我们的用户库是根据Uid进行分库的,那么我如果查询一个username=‘张三’的人怎么做呢?
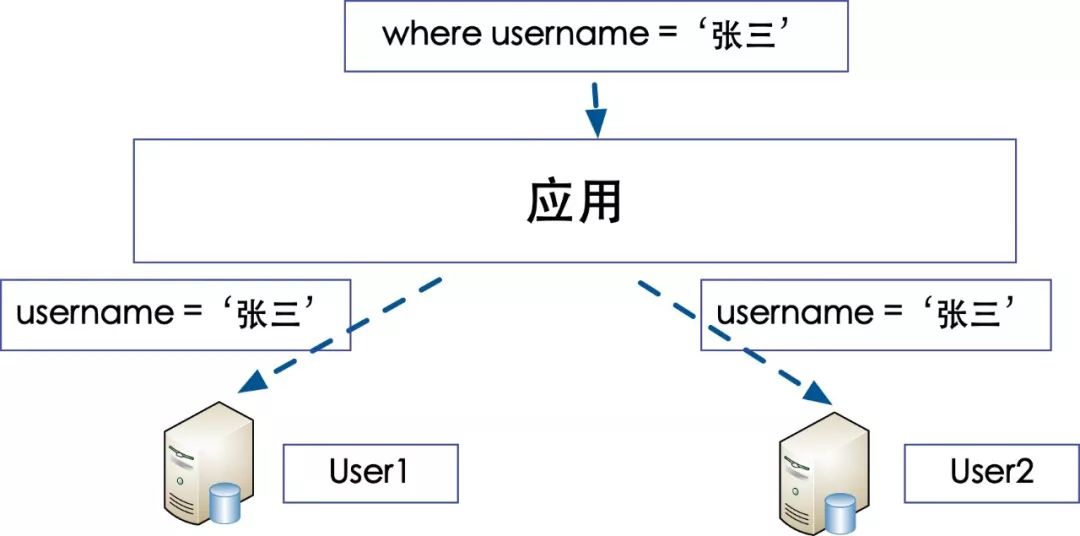
按照用户名查询
就是将所有的用户名为张三的在所有的库遍历一遍,那样效率其实相当的低下,怎么来解决按照某个Sharding Cloumn (Uid)进行分库但是需要按照其他Cloumn(username)查询的问题呢?
方案一:冗余关系法
我们想通过另外一个Cloumn进行查询,其实首先要找到这个分库分表的Sharding Cloumn 之后就顺利的解决问题了,那么就冗余一份username -- uid 的关系就可以了。可以建立一张关系表,这张关系表可能很大,但是里面的内容就两列,存储这种冗余的关系。如果量特别大也可以考虑使用username进行分库,降低单表的容量。
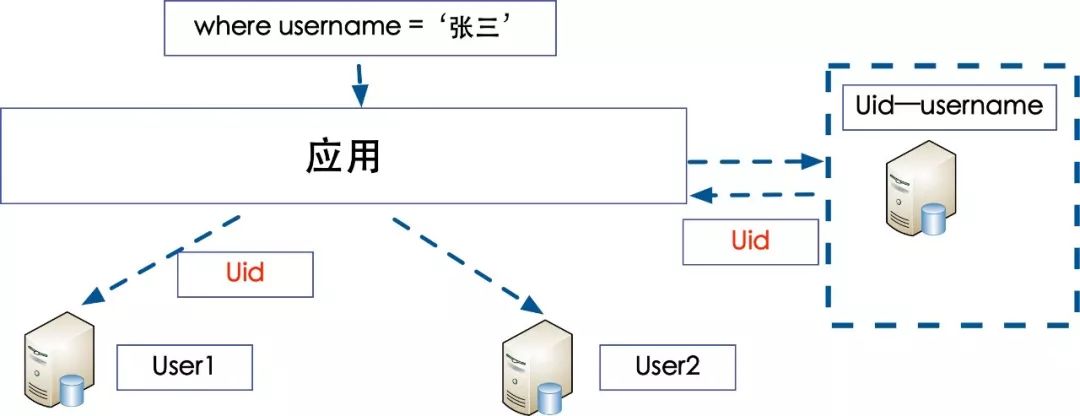
映射方式解决
这种方式的问题不足,增加了一次数据库的查询,性能下降一倍。
方案二:缓存记录对应关系提升性能
针对于每个用户的Uid 对应的用户名、手机号、和邮箱都是一对一的,所以我们可以采用缓存的方式来减少一次数据库的查询,来提升性能。
方案:
将所有的uid 和 username 的数据存入到redis中;
根据username去查询的时候先访问缓存,如果缓存丢失再去访问数据库讲数据放入缓存;
username对应的uid是不会变的所以这部分的缓存可以设置较长的过期时间;
如果数据量非常大,缓存层做数据分片,Redis一般都是采用一致性Hash的方式做分片。
方案三:uid生成策略融入username的特征
通过username去查询一个用户所在的库,最终的目的就是想通过各种各样的手段来建立一个从username 找到指定的库的方式,那么这种方式可以避免两次查询,无论是查询数据库还是缓存都是有开销的,这种方案的目的就是在生成uid的时候就把信息加入进去,这样分库的特征其实是通过username来实现的。
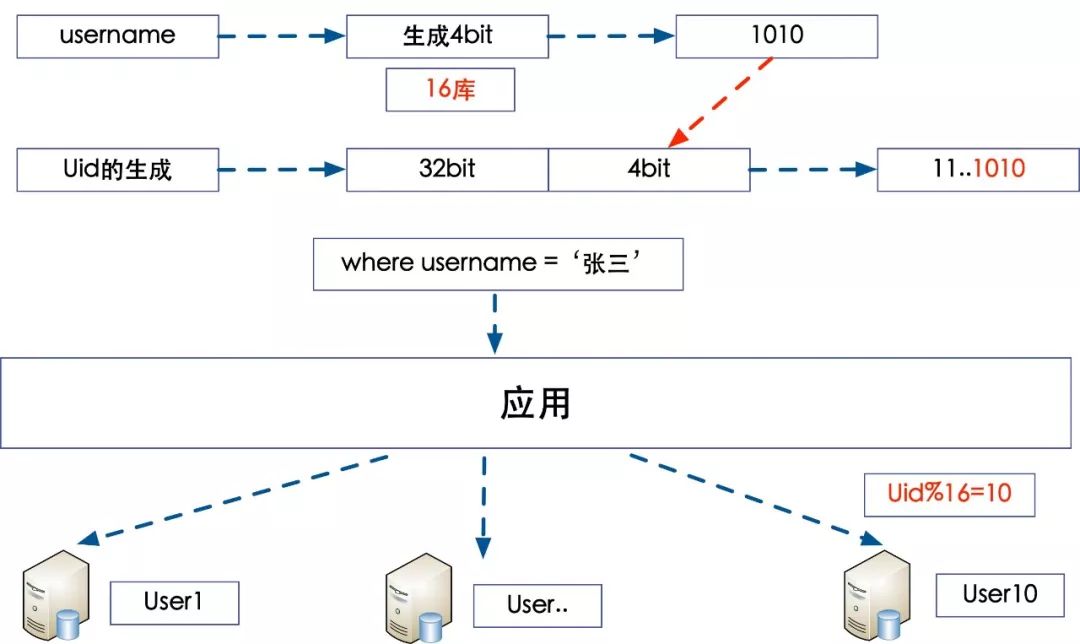
注入种子的方式
方案:
假设我们分16个库,那么只需要4bit就足够了,
第一步,通过一个函数将 username生成一个4bit的数字 ,func (username) = 1010 (4bit) 作为一个‘种子’;
第二步,在uid生成的时候,采用32位唯一标识一个用户,之后冗余一下上一步生成的‘种子’,冗余在末尾的位置,之后按照uid分库的方式插入到数据库中;
第三步,在查询的时候,通过func (username) =1010 计算出来这个值 转化为2进制就是10,通过路由策略 uid %16 =10 得知这个username应该在第10个库。
上边三种策略都有自己试用的场景,毕竟我们是需要根据多个唯一标示和密码来去查询用户的数据,在日常的项目中一般是采用冗余关系的方法来解决问题,采用第三种方案虽然好,但是生成uid的策略的更改其实是非常难的,在设计之初就要考虑好。
其他的两种查询:
1.查询弱密钥 where passwd=xxx
解决方案:
遍历所有的库查询即可。
2.查询最近注册 order by create_time desc 0,10
解决方案:
因为业务对于展示给用户看的数据准确性也不是那么高,随机找个库遍历出来最新的10个用户即可。如果就要找最新注册的前十个用户,需要遍历所有的库拿到最新注册的十个用户进行一次内存排序,这种方式的效果肯定是准确的,但是业务的意义在哪里呢。
论坛帖子库
帖子表10亿数据量,如何水平拆分?
tiezi(tid, uid, title, content, time);
业务需求如下
(1)查询帖子详情(90%请求)
SELECT * FROM tiezi WHERE tid=$tid
(2)查询用户所有发帖(10%请求)
SELECT * FROM tiezi WHERE uid=$uid
分析一下帖子库的特点,刚才的用户库的特点是 1:1 ,而帖子库的特点是一个用户可以发多个帖子,那么就是1:n的一个结构。帖子的查询基本是按照tiezi的id去查询的,很少根据用户id去查询的,大部分的人是上论坛浏览信息,查看自己发帖的用户还是非常少的。
通过用户库的方案分析有三种方案可以对帖子库进行分库,可以采用方案二 根据流量可以按照tiezi的维度进行分库,并且 建立一个映射关系,存储tiezi和uid的关系,通过关系表可以查询这个uid下边所有的帖子。也可以采用第三种方案在生成tid的时候冗余uid 来实现分库分表。
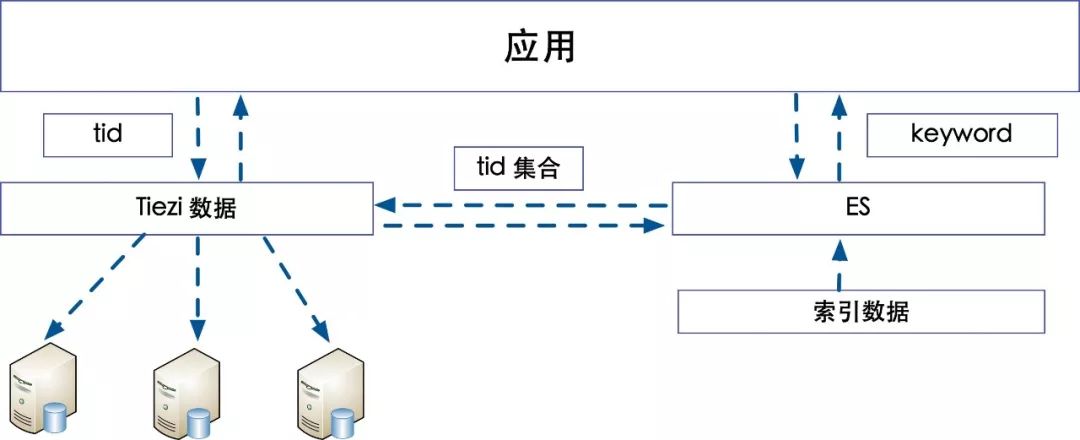
帖子库整体架构
除了分库分表对于帖子库的整体架构和用户库也是有很大不同的,用户的查询基本都是一些简单的根据某些关键字段进行查询,但是帖子库需要搜索的字段和条件非常的多,这里就需要外部索引来去支持,所以在上边的架构中引入了ES作为外部索引,通过一些属性以及关键词,通过倒排索引的方式查询出来对应的Tiezi的tid集合,通过集合再去数据库中查询具体信息。
订单库

订单表
订单表10亿数据量,如何水平拆分?
order(id, user_id, seller_id,amount,order_time,other );
业务需求如下查询订单信息(80%请求) SELECT * FROM order WHERE id=$id
我的订单(10%请求) SELECT * FROM order WHERE user_id=$my_uid
商家端 出售的订单 (10%请求) SELECT * FROM order WHERE seller_id=$my_uid
以阿里的订单举例,在某宝买东西,最近刚过去的双十一,大家肯定剁手不少,那么订单表该如何分库分表呢?
首先看业务需求,需要根据订单号查询该笔订单的详细信息,即根据id查询相关的信息,这个在整个体系中约占了80%的流量,另外的两大流量主要集中在,用户查看订单和商家查看售卖出去的订单,这两部分的量也非常大。
假设按照订单id进行分库,那么对于买家和卖家的查询,我就必须要做映射关系,通过对于用户表的分析这种方式是十分低效的,而且在双十一这么巨大的流量下边,这种方式显然行不通,既要保证买家和卖家的高并发的查询,而且还有对于订单号的高并发查询。
解决方案: 冗余买家和卖家的数据,保证买卖双方都可以快速的查询。
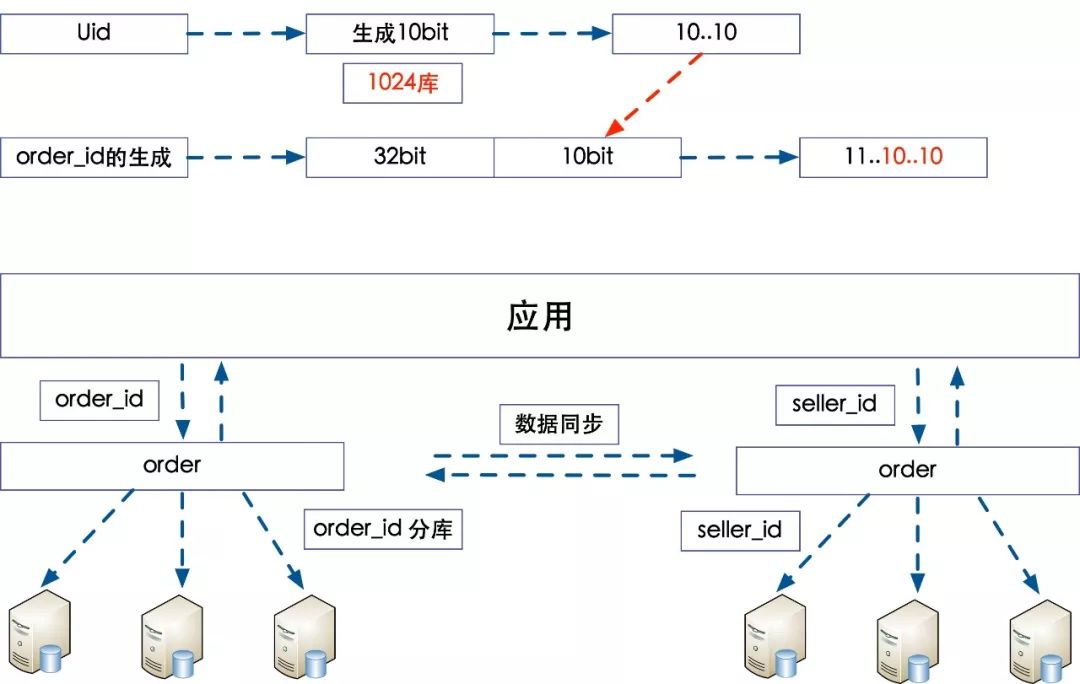
订单库分库分表
针对用户端的查询,通过在order_id中冗余uid的策略完成,对于order_id 和 uid的列表查询需求。
针对于在商家端的订单查询需求,通过数据同步的方式将所有的卖家订单同步到按照卖家分库的数据库。
另外还有数据冷热的问题,最近3个月的订单完全可以存储在数据库里面,每天将近4kw 订单量来讲,三个月就是36亿的数据,分为1024个库每个库大概承载几百万的订单量,理论讲是没有任何问题,超过3个月的订单基本都是冷数据除非有些统计需求可能会查看,大部分的用户和商家都不会再去查询,那么讲这部分数据存储到Hbase即可,可以通过ES+Hbase的方式将冷数据存储,如果用户查询超过3个月的订单,转移到其他服务查询即可。
优点:这种方案的好处是冗余数据,让双方查询的效率非常高;
缺点: 冗余了数据,这样数据所有的更新操作都需要进行双向的同步,对于数据一致性的挑战非常大,根据业务诉求来讲,卖家相对于用户来讲是非常少量的,所以这种方式满足了卖家对于订单操作效率的要求,在一些情况下可能数据的不一致会发生。
回到本文的最开始的问题,为什么很多订单的查询是需要通过ES索引去查询,那么我们可以用过分库分表的方式来解决么?了解了一下去哪儿的数据库分库策略,是根据业务进行的垂直拆库,去哪儿网的机票业务是OTA模式,去哪网这边收取用户的订单,派单给代理商,由代理商出票,并且回帖票号的模式。
这种模式下代理商就是卖家,用户就是买家,很自然的想到按照代理商的维度去拆库,并且冗余了代理商的三字码作为订单号的标识位。
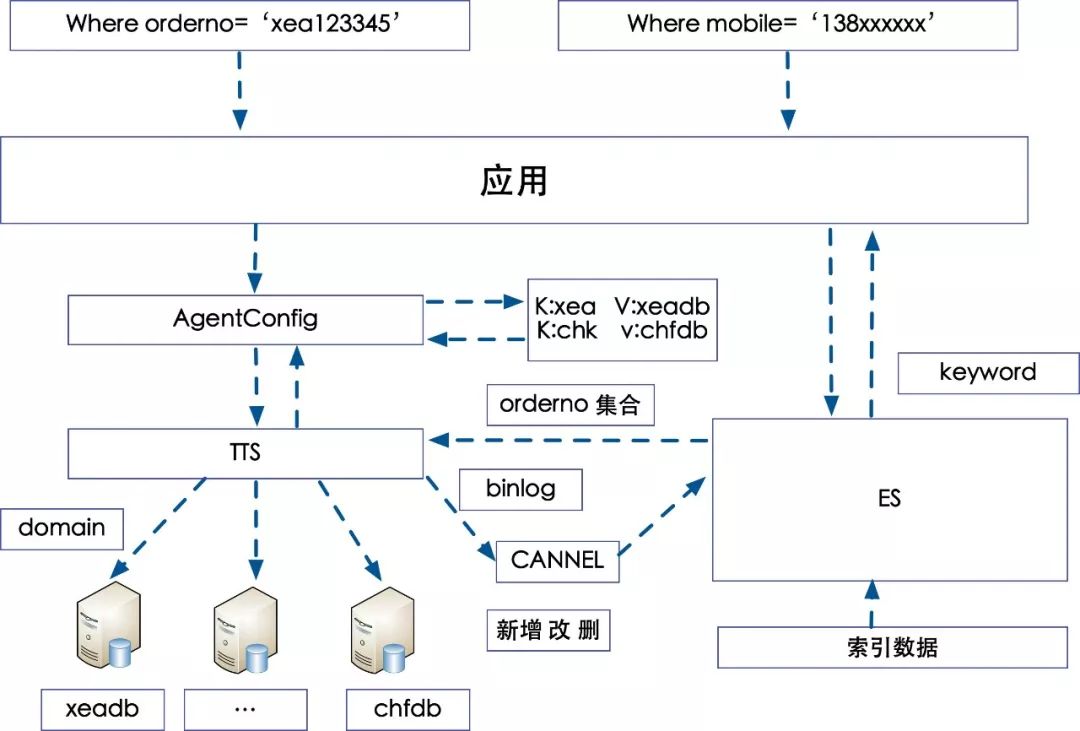
去哪儿机票分库分表方案
去那儿网分库策略 :
代理商维度分库,垂直分库,适应当时的旅游行业的业务诉求;
订单查询采取冗余代理商特征值的方法来快速的定位所在的库;
其他纬度查询则通过ES索引的方式来查询一个用户下所有的订单列表。
缺点:
数据量不均衡,随着业务量的发展逐步的有些代理商优胜略汰,造成大的代理商和小代理商差距过大,数据不均衡;
单库的数据量过大,因为航司增加了自营的订单量,这部分库的数据量增长非常快,无法再进行按照业务纬度切库,目前采用的做法是按照订单日期定期的归档,来减小单库容量不足的问题。
在用户中心一侧查询数据其实是通过将数据按照Uid的方式再进行分库,用户去查询的时候,查询的是用户中心的库。
未来的优化方向,考虑整体的重构分库的策略,结合上边的三种方式满足各种类型的用户查询方式,既满足用户侧的诉求也需要满足代理商快速出票的需求,可以考虑采用订单库的分库模式重构整个体系,机票订单库采用冗余关系表的方式,代理商的库采用冗余数据的方式,用户中心则完全不用自己冗余数据。底层数据的重构还要考虑业务现状以及整体的规划,测试回归的工作也十分的巨大,任重而道远!
总结:
| 单个 | 多个 | 多个+es | 多个+冗余+es+hbase | |
| 适用场景 | 单一 | 一般 | 广泛 | 一般 |
| 查询时效性 | 及时 | 及时 | 有延迟 | 有延迟 和不一致 |
| 存储能力 | 一般 | 一般 | 较大 | 海量 |
| 架构复杂度 | 一般 | 一般 | 复杂 | 复杂 |
对于海量数据的存储 ,而且还有很大的并发量的查询,这些架构是必须要根据具体的业务进行选型,任何脱离业务的架构都是耍流氓,有些业务适合单个字段的分库就可以满足需求,还有些业务可能需要冗余,而且分冷热数据,将冷数据转移到列式数据库。
分库分表不是一个简单的中间件就可以搞定一切的,需要从设计和架构的方向去共同的解决海量数据的存储问题,比如:id的生成策略,路由策略的制定,如何平滑的扩容,怎么解决数据一致性的问题,分布式的事务如何保证,希望以后可以和大家一起学习分享。
以上是关于数据库分库分表那些事的主要内容,如果未能解决你的问题,请参考以下文章