不要为了“分库分表”而“分库分表”
Posted 51CTO技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不要为了“分库分表”而“分库分表”相关的知识,希望对你有一定的参考价值。
当数据库的数据量过大,大到一定的程度,我们就可以进行分库分表。那么基于什么原则,什么方法进行拆分,这就是本篇所要讲的。
数据库瓶颈
在业务 Service 来看, 就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞吐量、崩溃)。
IO 瓶颈:
第一种:磁盘读 IO 瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的 IO,降低查询速度→分库和垂直分表。
第二种:网络 IO 瓶颈,请求的数据太多,网络带宽不够→分库。
CPU 瓶颈:
第一种:SQL 问题:如 SQL 中包含 join,group by,order by,非索引字段条件查询等,增加 CPU 运算的操作→SQL 优化,建立合适的索引,在业务 Service 层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL 效率低,增加 CPU 运算的操作→水平分表。
分库分表
水平分库
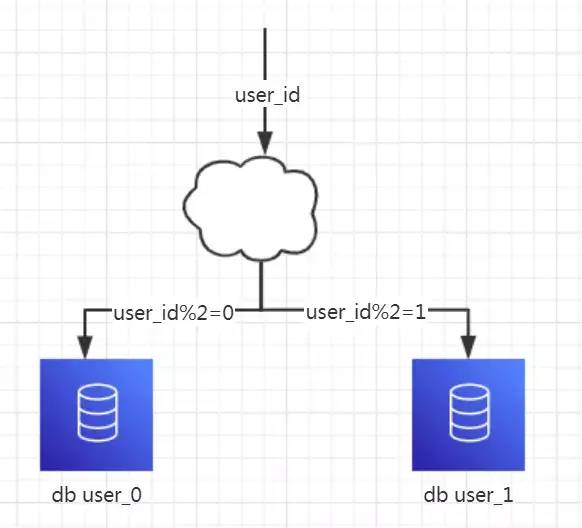
每个库的结构都一样
每个库中的数据不一样,没有交集
所有库的数据并集是全量数据
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
分析:库多了,IO 和 CPU 的压力自然可以成倍缓解。
水平分表
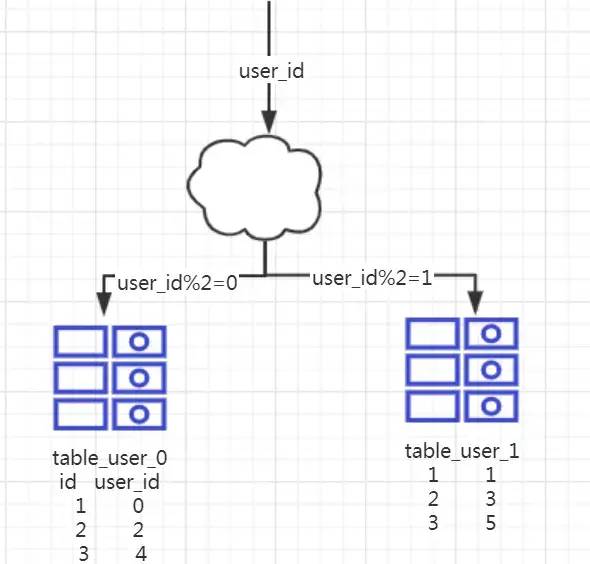
每个表的结构都一样。
每个表的数据不一样,没有交集,所有表的并集是全量数据。
场景:系统绝对并发量没有上来,只是单表的数据量太多,影响了 SQL 效率,加重了 CPU 负担,以至于成为瓶颈,可以考虑水平分表。
分析:单表的数据量少了,单次执行 SQL 执行效率高了,自然减轻了 CPU 的负担。
垂直分库
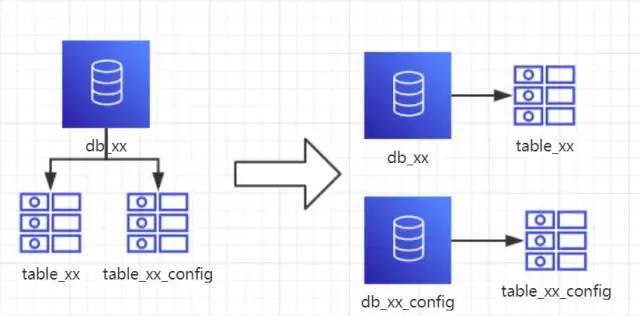
每个库的结构都不一样。
每个库的数据也不一样,没有交集。
所有库的并集是全量数据。
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块的情况下。
分析:到这一步,基本上就可以服务化了。例如:随着业务的发展,一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。
再者,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
垂直分表
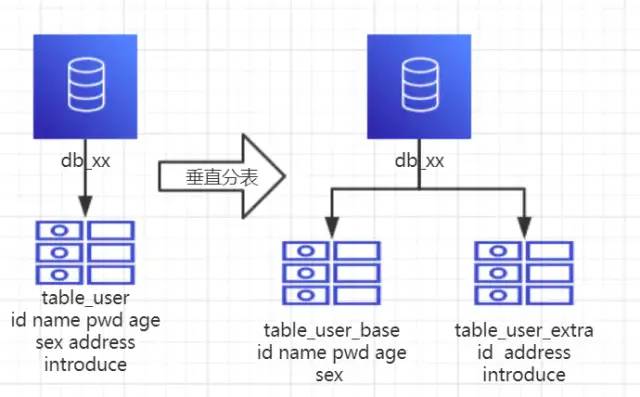
每个表的结构不一样。
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据。
所有表的并集是全量数据。
场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大,以至于数据库缓存的数据行减少,查询时回去读磁盘数据产生大量随机读 IO,产生 IO 瓶颈。
分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能经常会查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表,这样更多的热点数据就能被缓存下来,进而减少了随机读 IO。
拆了之后,要想获取全部数据就需要关联两个表来取数据。但记住千万别用 Join,因为 Join 不仅会增加 CPU 负担并且会将两个表耦合在一起(必须在一个数据库实例上)。
关联数据应该在 Service 层进行,分别获取主表和扩展表的数据,然后用关联字段关联得到全部数据。
分库分表工具
常用的分库分表工具如下:
Sharding-JDBC(当当)
TSharding(蘑菇街)
Atlas(奇虎 360)
Cobar(阿里巴巴)
MyCAT(基于 Cobar)
Oceanus(58 同城)
Vitess(谷歌) 各种工具的利弊自查
分库分表带来的问题
事务一致性问题
①分布式事务
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间,导致事务在访问共享资源时发生冲突或死锁的概率增高。
随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
②最终一致性
跨节点关联查询 Join 问题
①全局表
②字段冗余
③数据组装
④ER 分片
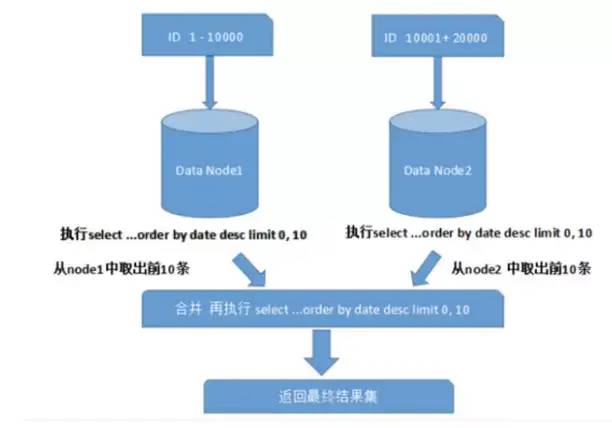
跨节点分页、排序、函数问题
需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
全局主键避重问题
①UUID
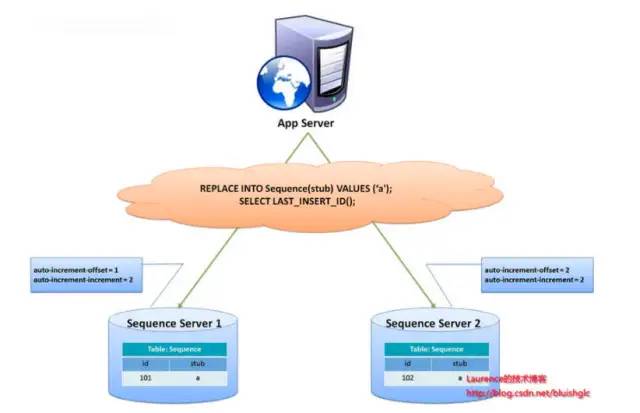
②结合数据库维护主键 ID 表
在数据库中建立 sequence 表:
CREATE TABLE `sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
当需要全局唯一的 ID 时,执行:
REPLACE INTO sequence (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
表中增长的步长是库的数量,起始值依次错开,这样就能将 ID 的生成散列到各个数据库上。
③Snowflake 分布式自增 ID 算法
第一位未使用。
接下来的 41 位是毫秒级时间,41 位的长度可以表示 69 年的时间。
5 位 datacenterId,5 位 workerId。10 位长度最多支持部署 1024 个节点。
最后 12 位是毫秒内计数,12 位的计数顺序号支持每个节点每毫秒产生 4096 个 ID 序列。
数据迁移、扩容问题
什么时候考虑分库分表
①能不分就不分
②数据量过大,正常运维影响业务访问
对数据库备份,如果单表太大,备份时需要大量的磁盘 IO 和网络 IO。
对一个很大的表做 DDL,MySQL会锁住整个表,这个时间会很长,这段时间业务不能访问此表,影响很大。
大表经常访问和更新,就更有可能出现锁等待。
③随着业务发展,需要对某些字段垂直拆分
④数据量快速增长
https://www.cnblogs.com/butterfly100/p/9034281.html
https://www.cnblogs.com/littlecharacter/p/9342129.html
编辑:陶家龙
出处:https://juejin.im/post/5dc77a9451882559465e390b
精彩文章推荐:
以上是关于不要为了“分库分表”而“分库分表”的主要内容,如果未能解决你的问题,请参考以下文章