「大数据」互联网应用数据大了就分库分表
Posted ITMAOO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「大数据」互联网应用数据大了就分库分表相关的知识,希望对你有一定的参考价值。
一起来探索大数据的奥秘
To explore bigdata
打开一切科学的钥匙都毫无异议地是问号,我们大部分的伟大发现都应当归功于如何?而生活的智慧大概就在于逢事都问个为什么?
——巴尔扎克
一
什么是分库分表
在信息爆炸的互联网时代,经过时间积累下来的信息可以给后来人提供重要的帮助,信息共享是互联网的核心 。时间积累下来的数据量非常巨大,存储和查询都不容易。插入的时候会锁表,并发量大会降低效率。查询的时候应因为数据量大会非常耗时。上面的情况最终导致服务运行效率慢,用户体验差。分库分表可以解决上面问题,道理很简单,原来一台机器干活现在多台机器干活,但实现起来并不简单。
分库分表即把原来存在一个表中的数据,拆分到多个数据库的多张表中存储。那么问题来了,数据如何拆分?拆分后保存和查询的时候,如何在众多的表中找到正确的表?


二
如何分库分表
概括来讲只有两种拆分方式,水平拆分和垂直拆分。垂直拆分即一个表中的多个字段拆分成多个表,每个表中的字段相对减少,这种拆法需要设计合理的ER模型,可以有效的减少重复数据。水平拆分即一个表中的多条数据分成过个表存储,每个表中的数据条数相对减少,这种拆法需要设计一个合理的拆分规则,如对用户ID取模余数是3,那么这条数据就存在第三个表中,这种拆法可以有效的减少但表中的数据量 。
拆分之后数据库的IO性能可以得到大幅提高,同时在未来IO出现瓶颈时可以按照同样的方式进行扩容,从而支撑更高的并发量。那么这种变更对运维和开发会带来哪些复杂度的提升,需要如何解决这些问题? 业界已经存在一些比较好的中间件, 可以系统的解决分库分表中遇到的问题。

三
分库分表带来的问题
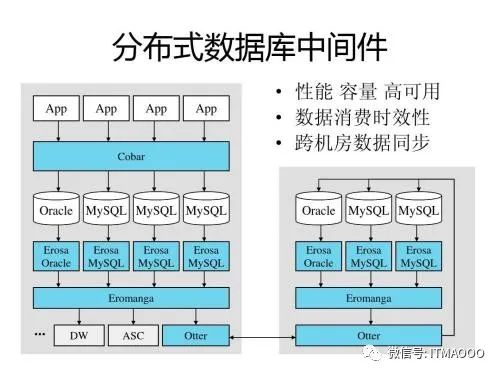
因为多库多表,一条数据要存入哪个表中需要一个计算过程,这个计算过程会增加开发人员的工作量。在单库的情况下,事务的一致性很容易得到保证,多个库的情况下保证事务的一致性,同样会增加开发人员的工作量。为了降低开发人员的工作量,前前后后涌现的一批开源插件,如:Cobar, Atlas, Sharding-jdbc,Mycat。比较推荐的有两个Sharding-jdbc和Mycat,Sharding-jdbc使用的范围相对比较广,而Mycat功能比较齐全, 由于Mycat比较新所以用户量没有Sharding-jdbc多。
最后一个比较难处理的问题是数据迁移。无论是水平分库分表还是垂直分库分表,都会伴随数迁移。相对来讲,由于水平拆分对表的结构影响小,开发人员需要做出的调整非常小,需要运维人员根据分库分表规则把数据存入相应的表中即可。相反,垂直拆分迁移数据比较复杂,需要开发人员和运维人员根据最新的ER模型做出相应的调整。
—— E N D ——
声明:原创内容未经允许请勿转载
长
按
关
注
IT咨询
ID : ITMAOO
一起寻找生命中的光.....
以上是关于「大数据」互联网应用数据大了就分库分表的主要内容,如果未能解决你的问题,请参考以下文章