基于cassandra做分表路由
Posted 易研家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于cassandra做分表路由相关的知识,希望对你有一定的参考价值。
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。因此分库分表方案已经成了互联网行业的项目中必不可少的一个环节。
分库分表的策略
分库分表有垂直切分和水平切分两种。
垂直切分: 即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB、日志数据库logDB等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
水平切分: 当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如userID散列进行划分,然后存储到多个结构相同的表,和不同的库上。例如,我们的userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
从分库分表策略可以看出这种方案貌似可以解决系统海量数据导致的系统处理能力的瓶颈问题,将多份数据分别存储在不同的DB库中,但是这样必然就带来了另外一个问题,数据的路由问题。比如之前系统的用户数据都存储在User一张表中,当有新用户注册或者登陆时,只需要在固定的User表中去查询或者写入即可,但是分表之后,如果是按照UserId的散列划分,系统在登录时候则必须能按照用户的账号路由到该数据存在的表。如果系统还存在有按照其他的数据维度去查询,比如:用户的昵称或者时间段查询,那么处理系统就非常困难了。很多系统在处理这种路由问题时的解决方案都是:新建查询维度字段和账号字段的对应关系表。显然这种方案数据无形当中又冗余了多份。
今天我这里主要是介绍一种分表之后的数据路由方案:基于cassandra的分表路由。
什么是cassandra
Apache Cassandra是一套开源的、分布式、无中心、支持水平扩展、高可用的KEY-VALUE类型的NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集Google BigTable的数据模型与AmazonDynamo的完全分布式的架构于一身。Cassandra的存储抽象结构和数据库一样,keyspace对应关系数据库的database或schema,column family对应于table。
对于cassandra的一些特性本文不做过多介绍,有兴趣的同学可以参考这里:http://cassandra.apache.org/。这里主要介绍一下cassandra的数据读写方式。先介绍一下cassandra的数据结构:
COLUMN
Column是Cassandra中最小的数据单元。它是一个3元的数据类型,包含:name,value和timestamp。
SUPERCOLUMN
我们可以将SuperColumn想象成Column的数组,它包含一个name,以及一系列相应的Column。
Columns和SuperColumns都是name与value的组合。最大的不同在于Column的value是一个“string”,而SuperColumn的value是Columns的Map。
还有一点需要注意的是:SuperColumn’本身是不包含timestamp的。
COLUMNFAMILY
ColumnFamily是一个包含了许多Row的结构,你可以将它想象成RDBMS中的Table。
每一个Row都包含有client提供的Key以及和该Key关联的一系列Column。
KEYSPACE
Keyspace是我们的数据最外层,你所有的ColumnFamily都属于某一个Keyspace。一般来说,我们的一个程序应用只会有一个Keyspace。
比如我这里安装cassandra并启动之后,可以做一些数据写入的测试:
这个时候,Cassandra中就已经有3条数据了。
其中插入数据的各个字段含义如下:
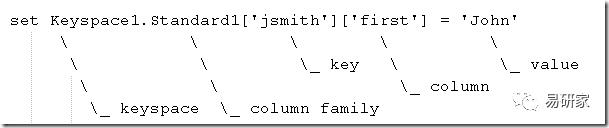
接下来,我们执行查询操作:
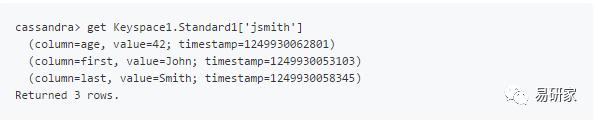
这样,我们就可以将之前插入的数据查询出来了。
给出一个整体的模型图则是这样的:

排序
有一点需要明确,我们使用Cassandra的时候,数据在写入的时候就已经排好顺序了。
在某一个Key内的所有Column都是按照它的Name来排序的。我们可以在storage-conf.xml文件中指定排序的类型。
目前Cassandra提供的排序类型有:BytesType, UTF8Type,LexicalUUIDType, TimeUUIDType,AsciiType,和LongType。
现在假设你的原始数据如下:

当我们storage-conf.xml文件中指定排序的类型为LongType时:
 排序后的数据就是这样的:
排序后的数据就是这样的:

如果我们指定排序的类型为UTF8Type
排序后的数据就是这样的:

另外Cassandra的排序功能是允许我们自己实现的,只要你继承org.apache.cassandra.db.marshal.IType就可以了。
Cassandra中的数据复制
在Cassandra中,集群中的一个或多个节点充当给定数据片段的副本。如果检测到一些节点以过期值响应,Cassandra将向客户端返回最近的值。返回最新的值后,Cassandra在后台执行读修复以更新失效值。
下图显示了Cassandra如何在集群中的节点之间使用数据复制,以确保没有单点故障的示意图。
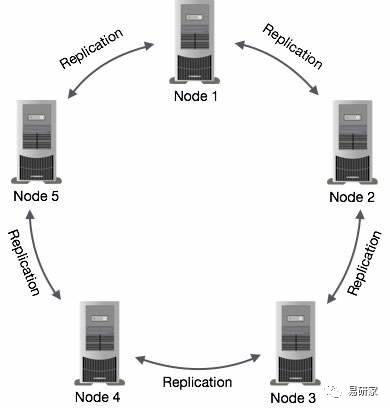
基于Cassandra的这些特性,我们可以在系统的分库分表之前,通过Cassandra来架设一层数据路由方式,每条新产生的数据,先写入到Cassandra集群中。当然写入的数据并非原始数据,因为要考虑到一些关联查询的问题(Cassandra在关联查询这块没办法做到像mysql这种关系型数据库这么强大)。简单介绍一下实际项目中的场景。
场景:用户支付
Mysql的Pay表结构如下:
当用户支付时,我们按照order_id的散列做分表策略,但是在写入mysql之前,我们先将数据进行扩展,对mysql中仅仅需要的user_id的用户基本信息和用户支付的详细数据关联存储在Cassandra中。
当需要按照用户或者支付的其他任何维度查询数据时,先通过Cassandra的数据关联查找到对应的订单order_id,然后按照id的散列查询出mysql中的分表信息。
对于数据进行分库分表之后的简单查询,业内解决方案也有很多,而分库分表之后需以非分表维度的字段查询需求,目前业内也没有一种完全完美的方式来解决,对于分表之后复杂的多表关联查询就更难以控制了。以上的方案核心在于借助了Cassandra的特性来做数据路由操作,它的缺点在于对需要写入Cassandra的数据必须经过严格的设计,因为一旦写入的基础关联数据无法满足业务的查询条件,那么就必须对数据进行重新关联以及横向扩展了。我相信我们今天讨论的主题也有很多我本人不知道的更好的实现方式,希望有兴趣的朋友可以分享。同时也希望这篇文章对同样在遇到分表之后的数据查询问题上没有好办法的朋友有一定引导作用。
以上是关于基于cassandra做分表路由的主要内容,如果未能解决你的问题,请参考以下文章