Node.js背后的V8引擎优化技术
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node.js背后的V8引擎优化技术相关的知识,希望对你有一定的参考价值。
Node.js的执行速度远超Ruby、Python等脚本语言,这背后都是V8引擎的功劳。本文将介绍如何编写高性能Node.js代码。V8是Chrome背后的javascript引擎,因此本文的相关优化经验也适用于基于Chrome浏览器的JavaScript引擎。
V8优化技术概述
V8引擎在虚拟机与语言性能优化上做了很多工作。不过按照Lars Bak的说法,所有这些优化技术都不是他们创造的,只是在前人的基础上做的改进。
隐藏类(Hidden Class)
为了减少JavaScript中访问属性所花的时间,V8采用了和动态查找完全不同的技术实现属性的访问:动态地为对象创建隐藏类。这并不是什么新想法,基于原型的编程语言Self就用map来实现了类似功能。在V8中,当一个新的属性被添加到对象中时,对象所对应的隐藏类会随之改变。
我们用一个简单的JavaScript函数来加以说明:
function Point(x, y) { this.x = x; this.y = y; }
当newPoint(x, y)执行时,一个新的Point对象会被创建。如果这是Point对象第一次被创建,V8会为它初始化一个隐藏类,不妨称作C0。因为这个对象还没有定义任何属性,所以这个初始类是一个空类。到此时为止,对象Point的隐藏类是C0(如图1)。
图1 对象Point的隐藏类C0
执行函数Point中的第一条语句会为对象Point创建一个新的属性x。此时,V8会在C0的基础上创建另一个隐藏类C1,并将属性x的信息添加到C1中:这个属性的值会被存储在距Point对象偏移量为0的地方(如图2)。
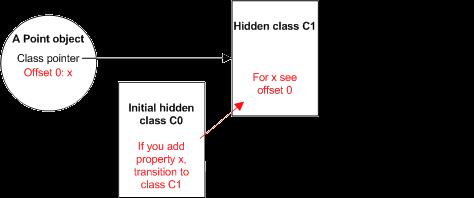
图2 对象Point的隐藏类被更新为C1
在C0中添加适当的类转移信息,使得当有另外的以其为隐藏类的对象在添加了属性x之后能找到C1作为新的隐藏类。此时对象Point的隐藏类更新为C1。
执行函数Point中的第二条语句会添加一个新的属性y到对象Point中。同理,此时V8会有以下操作。
在C1的基础上创建另一个隐藏类C2,并在C2中添加关于属性y的信息:这个属性将被存储在内存中离Point对象的偏移量为1的地方。
在C1中添加适当的类转移信息,使得当有另外的以其为隐藏类的对象在添加了属性y之后能找到C2作为新的隐藏类。此时对象Point的隐藏类被更新为C2(如图3)。
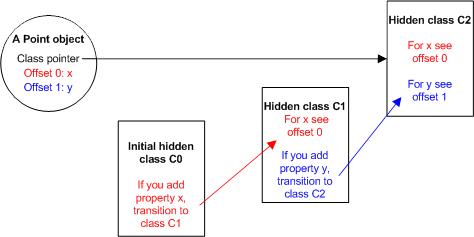
图3 对象Point的隐藏类被更新为C2
乍一看似乎每次添加一个属性都创建一个新的隐藏类非常低效。实际上,利用类转移信息,隐藏类可以被重用。下次创建一个Point对象时,就可以直接共享由最初那个Point对象所创建出来的隐藏类。
例如,又有一个Point对象被创建出来,一开始Point对象没有任何属性,它的隐藏类将会被设置为C0。当属性x被添加到对象中时,V8通过C0到C1的类转移信息将对象的隐藏类更新为C1,并直接将x的属性值写入到由C1所指定的位置(偏移量0)。当属性y被添加到对象中时,V8又通过C1到C2的类转移信息将对象的隐藏类更新为C2,并直接将y的属性值写入到由C2所指定的位置(偏移量1)。尽管JavaScript比通常的面向对象编程语言都更加动态一些,然而大部分JavaScript程序都会表现出像上文描述的那样运行时高度结构重用的行为特征来。使用隐藏类主要有两个好处:属性访问不再需要动态字典查找;为V8使用经典的基于类的优化和内联缓存技术创造了条件。
内联缓存(Incline Cache)
在第一次执行到访问某个对象的属性的代码时,V8会找出对象当前的隐藏类。同时,假设在相同代码段里的其他所有对象的属性访问都由这个隐藏类进行描述,并修改相应的内联代码让他们直接使用这个隐藏类。当V8预测正确时,属性值的存取仅需一条指令即可完成。如果预测失败,则再次修改内联代码并移除刚才加入的内联优化。
例如,访问一个Point对象的x属性的代码如下:
point.x
在V8中,对应生成的机器码如下:
ebx = the point objectcmp [ebx, <hidden class offset>], <cached hidden class> jne<inline cache miss> mov eax, [ebx, <cached x offset>]
如果对象的隐藏类和缓存的隐藏类不一样,执行会跳转到V8运行系统中处理内联缓存预测失败的地方,在那里原来的内联代码会被修改,以移除相应的内联缓存优化。如果预测成功,属性x的值会被直接读出来。
当有许多对象共享同一个隐藏类时,这样的实现方式下,属性的访问速度可以接近大多数动态语言。使用内联缓存代码和隐藏类实现属性访问的方式与动态代码生成和优化的方式结合起来,让大部分JavaScript代码的运行效率得以大幅提升。
两次编译与反优化(Crankshaft)
尽管JavaScript是个非常动态的语言,且原本的实现是解释性的,但现代的JavaScript运行时引擎都会进行编译。V8(Chrome的JavaScript)有两个不同的运行时(JIT)编译器。
“完全”编译器(Unoptimized):一开始,所有V8代码都运行在Unoptimized状态。它的好处是编译速度非常快,使代码初次执行速度非常快。
“优化”编译器(Optimized):当V8发现某段代码执行非常热时,它会根据通常的执行路径进行代码优化,生成Optimized代码。优化代码的执行速度非常快。
编译器有可能从“优化”退回到“完全”状态,这就是Deoptimized。这是很不幸的过程,优化后的代码没法正确执行,不得不退回到Unoptimized版本。当然最不幸的是代码不停地被Optimized,然后又被Deoptimized,这会带来很大性能损耗。图4是代码Optimized与Deoptimized执行流程。
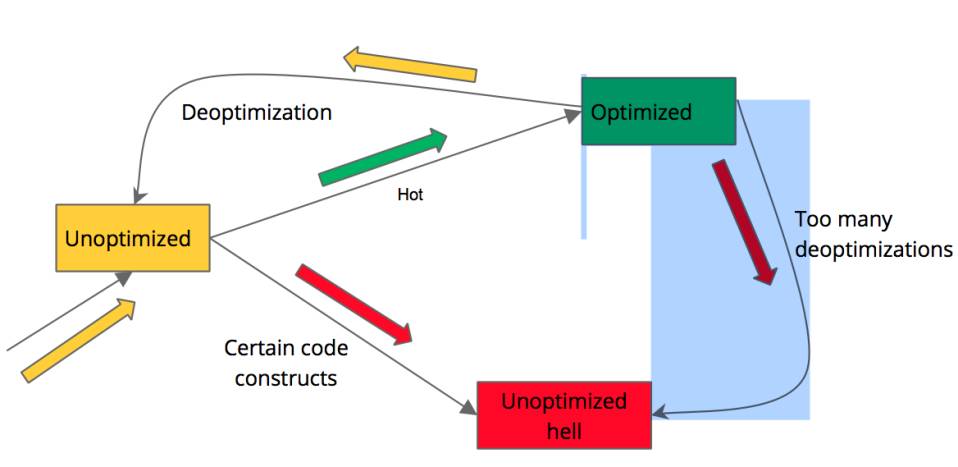
图4 代码Optimized与Deoptimized执行流程
高效垃圾收集
最初的V8引擎垃圾收集是不分代的,但目前V8引擎的GC机制几乎采用了与JavaHotspot完全相同的GC机制。对Java虚拟机有经验的开发者直接套用。
但V8有一个重要的特性却是Java没有的,而且是非常重要的特性,因此必须要提一下,这个特性叫Incremental Mark+Lazy Sweep。它的设计思路与Java的CMS垃圾收集类似,就是尽量减少GC系统停顿的时间。不过在V8里这是默认的GC方式,不象CMS需要非常复杂的配置,而且还可能有Promotion Fail引起的问题。图5是通常Full GC的MarkSweep流程。
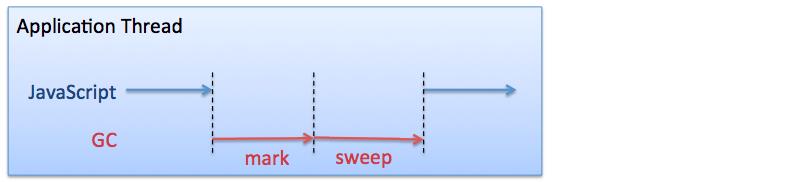
图5 通常的FullGC的Mark、Sweep流程
这个流程里每次GC都要完成完整的Mark、Sweep流程,因此停顿时间较久。
引入了IncrementMark之后的流程如图6所示。
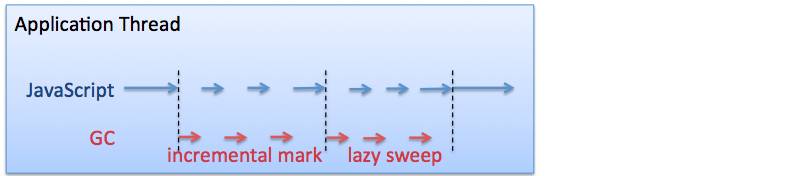
图6 引入IncrementMark后的流程
这个流程每次GC可以在Mark一半时停住,在完成业务逻辑后继续下一轮GC,因此停顿时间较短。
只要保证Node.js内存大小不超过500MB,V8即使发生Full GC也能控制在50毫秒内,这使Node.js在开发高实时应用(如实时游戏)时比Java更有优势。
编写对V8友好的高性能代码
隐藏类(Hidden Class)的教训
在构造函数里初始化所有对象的成员(因此这些实例之后不会改变其隐藏类)。
总是以相同的次序初始化对象成员。
永远不要delete对象的某个属性。
示例1
function Point(x, y) { this.x = x; this.y = y; } var p1 = new Point(11, 22); var p2 = new Point(33, 44); // At this point, p1 and p2 have ashared hidden class// 这里的p1和p2拥有共享的隐藏类 p2.z = 55; // warning! p1 and p2 now have different hidden classes!// 注意!这时p1和p2的隐藏类已经不同了!
在以上例子中,p2.z破坏了上述原则,将导致p1与p2使用了不同的隐藏类。
在我们为p2添加“z”这个成员之前,p1和p2一直共享相同的内部隐藏类——因此V8可以生成一段单独版本的优化汇编码,这段代码可以同时封装p1和p2的JavaScript代码。派生出这个新的隐藏类还将使编译器无法在Optimized模式执行。我们越避免隐藏类的派生,就会获得越高的性能。
示例2
function Point(x, y) { this.x = x; this.y = y; } for (var i=0; i<1000000; i++) { var p1 = new Point(11, 22); delete p1.x; p1.y++; }
由于调用了delete,将导致hidden class产生变化,从而使p1.y不能用inlinecache直接获取。
以上程序在使用了delete之后耗时0.339s,在注释掉delete后只需0.05s。
Deoptimized的教训
单态操作优于多态操作;
谨慎使用try catch与for in。
示例1
如果一个操作的输入总是相同类型,则其为单态操作。否则,操作调用时的某个参数可以跨越不同的类型,那就是多态操作。例如add()的第二个调用就触发了多态操作:
function add(x, y) { return x + y; } add(1, 2); // add中的+操作是单态操作 add("a", "b"); // add中的+操作变成了多态操作
以上示例由于传入的数据类型不同,使add操作编译成Optimized代码。
示例2
该示例来自GoogleI/O 2013的一个演讲:Accelerating Oz with V8。The oz story的游戏有频繁的GC,游戏的帧率在运行一段时间后不断下降,图7是GC曲线。

图7 游戏GC曲线
是什么导致如此GC呢?有三个疑犯:
new出来的对象没有释放,这通常由闭包或集合类的操作导致;
对象在初始化后改变属性,就是hidden class示例1的例子;
某段特别热的代码运行在Deoptimized模式。
unit9的开发人员对JavaScript的开发规范了然于胸,绝对不会犯前两个错误,于是怀疑定在第3个嫌疑犯。图8是诊断time后的结果。
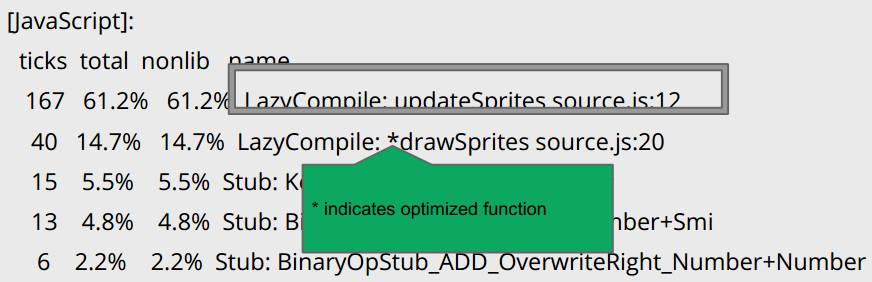
图8 诊断结果
图中drawSprites运行在Optimized状态,但updateSprites一直运行在Deoptimized状态。
导致不断GC的原凶竟然是这几行代码:
图9 导致不断GC的代码
因为forin下面的代码在V8下暂时无法优化。把for in内部的代码提出成单独的function,V8就可以优化这个function了。这时GC和掉帧率的问题就立刻解决了。GC曲线出现了缓慢平缓的状态:
图10 解决问题后的曲线
以上教训不仅仅是使用for in或try catch的问题,也许未来V8引擎会解决这两个问题。我们要理解怎么发现问题、解决问题,还有Deoptimized竟然会对GC产生影响。
以上排查过程使用了–trace-opt、–trace-deopt、–prof命令选项,及mac-tick-processor等工具。值得注意的是Node.js里直接使用mac-tick-processor或linux-tick-processor是解不出JavaScript段执行结果的,可以使用node-tick-processor这个工具。
内存管理与GC的教训
《深入浅出Node.js》书中有详细的V8内存管理和使用经验介绍。这里只展示两个简单的例子。
闭包
闭包会使程序逻辑变复杂,有时会看不清楚是否对象内存被释放,因此要注意释放闭包中的大对象,否则会引起内存泄漏。
例如以下代码:
vara = function () {
var largeStr = new Array(1000000).join(‘x’);
return function () {
return largeStr;
};
}();
例子中的largeStr会被收集吗?当然不会,因为通过全局的a()就可以取到largeStr。
那么以下代码呢?
var a = function() { var smallStr = 'x'; var largeStr = newArray(1000000).join('x'); returnfunction(n) { return smallStr; }; }();
这次a()得到的结果是smallStr,而largeStr则不能通过全局变量获得,因此largeStr可被收集。
timer
timer的内存泄漏很普遍,也较难被发现。例如:
var myObj = { callMeMaybe: function() { var myRef = this; var val = setTimeout(function() { console.log('Time is running out!'); myRef.callMeMaybe(); }, 1000); } };
当调用如下代码:
myObj.callMeMaybe();
定时器会不停打印“Timeis running out”。
当用如下代码释放掉myObj:
myObj=null;
定时器仍然会不停打印“Time is running out”。
myObj对象不会被释放掉,因为内部的myRef对象也指向了myObj,而内部的setTimeout调用会将闭包加到Node.js事件循环的队列里,因此myRef对象不会释放。
其他教训
使用数字的教训
当类型可以改变时,V8使用标记来高效地标识其值。V8通过其值来推断你会以什么类型的数字来对待它。因为这些类型可以动态改变,所以一旦V8完成了推断,就会通过标记高效完成值的标识。不过有时改变类型标记还是比较消耗性能的,我们最好保持数字的类型始终不变,通常标识为有符号的31位整数是最优的。
使用Array的教训
为了掌控大而稀疏的数组,V8内部有两种数组存储方式:
快速元素:对于紧凑型关键字集合,进行线性存储;
字典元素:对于其他情况,使用哈希表。
最好别导致数组存储方式在两者之间切换。
因此:
使用从0开始连续的数组关键字;
别预分配大数组(例如大于64K个元素)到其最大尺寸,令尺寸顺其自然发展就好;
别删除数组里的元素,尤其是数字数组;
别加载未初始化或已删除的元素。
示例1
a = newArray(); for (var b = 0; b < 10; b++) { a[0] |= b; // 杯具! } a = newArray(); a[0] = 0; for (var b = 0; b < 10; b++) { a[0] |= b; // 比上面快2倍 }
以上两段代码,由于第一段代码的a[0]未初始化,尽管执行结果正确,但会导致执行效率的大幅下降。
示例2
同样的,双精度数组会更快——数组的隐藏类会根据元素类型而定,而只包含双精度的数组会被拆箱(unbox),这导致隐藏类的变化。对数组不经意的封装就可能因为装箱/拆箱(boxing/unboxing)而导致额外的开销。例如以下代码:
var a = newArray(); a[0] = 77; // 分配 a[1] = 88; a[2] = 0.5; // 分配,转换 a[3] = true; // 分配,转换
因为第一个例子是一个个分配赋值的,在对a[0] 、a[1]赋值时数组被判定为整型数组,但对a[2]的赋值导致数组被拆箱为了双精度。但对a[3]的赋值又将数组重新装箱回了任意值(数字或对象)。
下面的写法效率更高:
var a = [77, 88, 0.5, true];
第二种写法时,编译器一次性知道了所有元素的字面上的类型,隐藏隐藏类可以直接确定。
因此:
初始化小额定长数组时,用字面量进行初始化;
小数组(小于64k)在使用之前先预分配正确的尺寸;
请勿在数字数组中存放非数字的值(对象);
如果通过非字面量进行初始化小数组时,切勿触发类型的重新转换。
结论
GoogleV8使JavaScript语言的执行效率上了一大台阶。但JavaScript是非常灵活的语言,过于灵活的语法将导致不规范的JavaScript语言无法优化。因此,在编写对V8编译器友好的JavaScript或者Node.js语言时就要格外注意。
以上是关于Node.js背后的V8引擎优化技术的主要内容,如果未能解决你的问题,请参考以下文章