新 V8 为 NODE.JS 带来的性能变化
Posted 大前端工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新 V8 为 NODE.JS 带来的性能变化相关的知识,希望对你有一定的参考价值。
V8 的 TurboFan 将会如何影响我们的代码优化方式
2017-07-27
本文首发于知乎专栏:大前端工程师,大家可以打开【阅读原文】进行评论。
原文经过了来自 V8 团队的 Franziska Hinkelmann 和 Benedikt Meurer 的审阅。
Node.js 从它诞生的第一天开始,就依赖于 V8 javascript 引擎来执行我们的 JavaScript 代码。V8 引擎是由 Google 打造的 JavaScript 虚拟机,被应用在它的 Chrome 浏览器中。从一开始,V8的主要目标就是让 JavaScript 执行地更快,或者至少要胜过其它竞争者。对于 JavaScript 这样一个具有高度动态性、弱类型语言而言,达到这个目标绝非易事。让我们先来回顾一下 V8 以及 其它 JS 引擎在性能方面的演化历史。
让 V8 引擎可以快速执行 JavaScript 的核心要素是 JIT(Just In Time)编译器。它是一个可以在运行时优化代码的动态编译器。V8 最早设计的 JIT 编译器被取名为 FullCodegen,随后 V8 团队又实现了 Crankshaft,其中实现了许多 FullCodegen 中所没有的性能优化。
感谢 Yang Guo 告诉我们 FullCodegen 是 V8 中首个经过优化的编译器。
我从上世纪 90 年代就开始观察和使用 JavaScript,我感到似乎无论在哪个 JavaScript 引擎中,代码的执行速度经常是反直觉的,面对一些明显执行很慢的 JavaScript 代码我们很难知道其背后的原因。
近几年来,我和 Matteo Collina 致力于研究如何写出高性能的 Node.js 代码。这意味着我们要搞清楚在 V8 引擎上怎样的代码会执行比较快或慢。
但现在,挑战我们现有认知的时刻到了,因为 V8 团队推出了一个新的 JIT 编译器:Turbofan。
有一些大家众所周知的代码编写方式会导致执行效率低下(尽管在 Turbofan 中可能并非如此),我和 Matteo 在进行 Crankshaft 性能研究过程中也有一些其它不大为人所知的发现。在这篇文章里,我们将讨论所有这些点,通过一系列性能基准测试,来看一看它们在各版本 V8 中有什么样的变化。
当然,在为 V8 优化我们的代码之前,我们应该首先把精力放在 API 设计、算法和数据结构上。本文中的性能测试仅仅是为了比较在 Node 中 JavaScript 运行效率的变化。我们当然可以据此来改变我们编写代码的方式以改善代码运行的效率,但是在这之前,我们应该首先使用一些更为通用的优化手段。
接下来我们将对 V8 5.1、5.8、5.9、6.0 和 6.1 进行性能测试。
V8 5.1 是 Node 6 使用的引擎,包含了 Crankshaft JIT 编译器;V8 5.8 则用于 Node 8.0 到 8.2,使用的是 Crankshaft 和 Turbofan 的混合体。
V8 6.0 被包含在 Node 8.3(也可能是 8.4)里,而写作本文时最新的 V8 版本是 6.1,它被整合在 node-v8 的试验仓库(https://github.com/nodejs/node-v8)中。换句话说,V8 6.1 最终将会出现在 Node 未来的某个版本中,有可能是 Node.js 9。
在呈现测试结果的同时,我们也会讨论这些变化对未来意味着什么。这些基准测试都是用 benchmark.js 运行的,结果数值反映的是每秒钟的执行次数,因此在每幅图表中,结果值越高意味着性能越好。
Try / Catch
有一个大家众所周知的反优化模式就是使用 try/catch。
在这个测试中我们对 1 到某个自然数进行累加求和,比较了四种不同编码方式的性能:
把累加过程包含在一个
try/catch中(sum with try catch)不对累加过程进行
try/catch(sum without try catch)把累加过程写成一个函数,再在一个
try块中执行它(sum wrapped)把累加过程写成一个函数,然后简单地直接执行它(sum function)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/try-catch.js
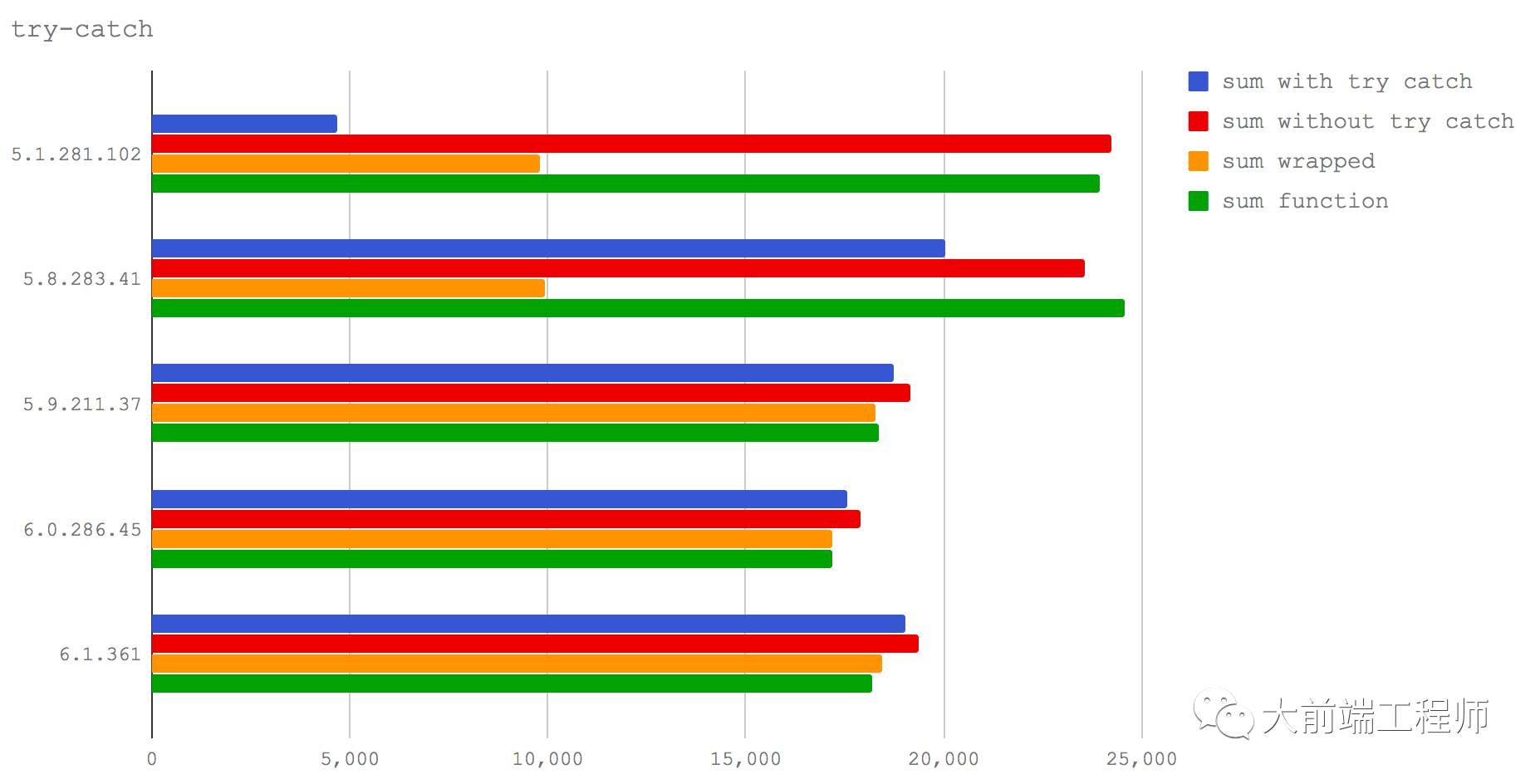
从结果可见,我们原本对于 try/catch会导致性能问题的观点在 Node 6(V8 5.1)上还是正确的,但是 try/catch对性能的影响在 Node 8.0-8.2(V8 5.8)上已经显著降低。
同时需要注意的是,在 Node 6(V8 5.1)和 Node 8.0-8.2(V8 5.8)中, try块内执行一个函数要比在 try块外执行它要慢得多。
但是对于 Node 8.3+,在 try块内执行函数导致的性能下降却几乎可以忽略不计了。
尽管如此,也不要以为万事大吉。我和 Matteo 在为一些关于性能的研讨会准备材料的时候,发现了一个 V8 性能方面的 bug:某种特定的代码逻辑组合可能会导致 Turbofan 陷入到一个反优化/再优化的无穷循环中去(这完全是一个性能“杀手” —— 即破坏性能的编码模式)。
从对象中移除属性
多年以来,想要写出高性能 JavaScript 代码的人都不会使用 delete操作符(或至少在我们试图优化一些高频代码时,我们会避免使用 delete)。
delete的问题根源在于 V8 对 JavaScript 对象的动态特性和原型链(也具有潜在的动态性)的处理方式。这些动态特性使得在引擎在实现对属性的查找时变得异常复杂。
V8 引擎为了提高属性和对象的处理速度,在 C++ 层面基于对象的“结构”为对象创建了 C++ 类。所谓对象的“结构”,就是指对象中所包含的属性的键及其值(也包括原型链上的键和值);而这些 C++ 类就被称为“hidden classes”。可是这种优化是发生在运行时的,如果一个对象的“结构”是不确定的,那么 V8 就无法为其创建“hidden classes”,只能使用另一种慢地多的方式即哈希表查找的方式来进行属性获取。所以一直以来,当我们从对象中 delete一个属性之后,后续的属性查找模式就会变成哈希表查找。这就是我们要避免使用 delete的原因。我们通过把要移除的属性赋值为 undefined来达到类似 delete的效果,在大多数情况下这么做完全可以满足需要了,除了可能会在检查属性是否存在时会有点问题。而且 JSON.stringify也不会在其输出结果中包含 undefined值(按照 JSON 规范, undefined并不是一个有效的值),所以这样做对于对象序列化也没有问题。
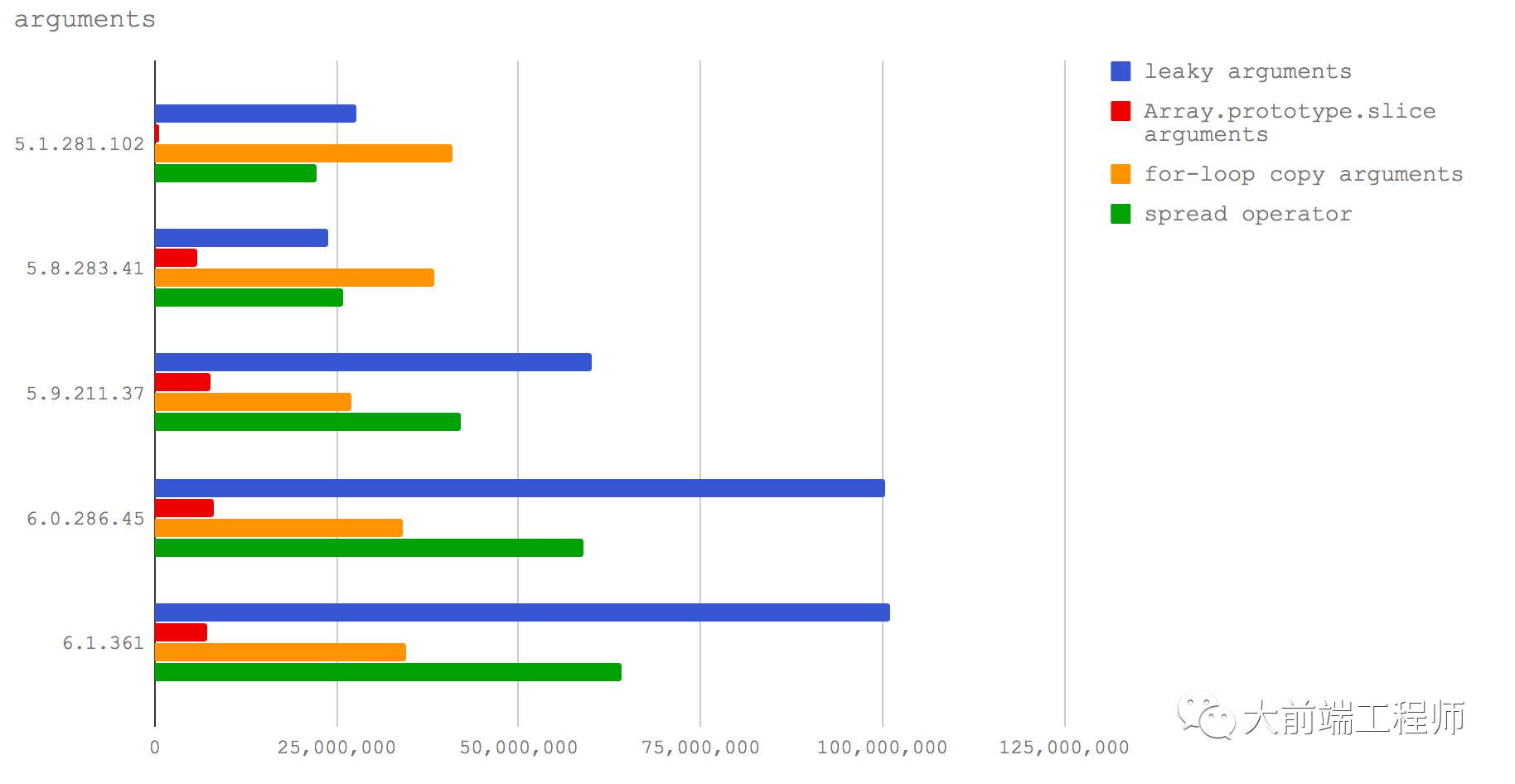
arguments 是一个在普通JavaScript函数(而箭头函数就没有arguments```对象)中存在的隐式对象,由于它像是数组但又不是数组,在使用时经常会碰到问题。
为了能够对 arguments对象使用数组方法,像数组一样地使用它,我们需要把它的每个索引属性都复制到一个真正的数组中。在过去,JavaScript 开发人员倾向于认为代码越少则执行速度越快。对于那些需要运行在浏览器中的代码而言,这个粗糙的规则确实会带来在传输和加载体积方面的收益,但是在服务器端,代码的执行速度远比代码的体积重要,仍然套用这一规则可能会导致问题。很多人都习惯使用一种看上去很巧妙且简便的方式来把 arguments对象转化为数组: Array.prototype.slice.call(arguments)。通过执行数组的 slice方法,把 arguments对象作为执行时的上下文即 this传入, slice方法会把传入的伪数组当做一个数组来操作。这样我们就可以得到一个包含了整个参数对象成员的数组。
可是,直接把一个函数的 arguments隐含对象从函数上下文中暴露出去(比如把它通过返回值输出到函数之外,或者说正如在 Array.prototype.slice.call(arguments)所做的一样, arguments对象被传送给了另一个函数)会导致性能下降。现在让我们看看是不是会这样。
下面这个测试基于我们的四个 V8 版本,比较了这两种做法的性能代价,即是对外泄露 arguments对象的性能好,还是把 arguments 复制为一个数组(然后再以同样的方式传送到函数之外)的性能好:
把
arguments对象暴露给另外一个函数(leaky arguments)使用
Array.prototype.slice技巧把arguments复制为一个数组(Array prototype.slice arguments)使用 for 循环复制
arguments中每个属性(for-loop copy arguments)使用 ES2015 中的 spread 操作符来转化
arguments为一个数组(spread operator)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/arguments.js
我们还可以用线状图来呈现与上图相同的数据,可以更加清楚地看出在性能上的变化:
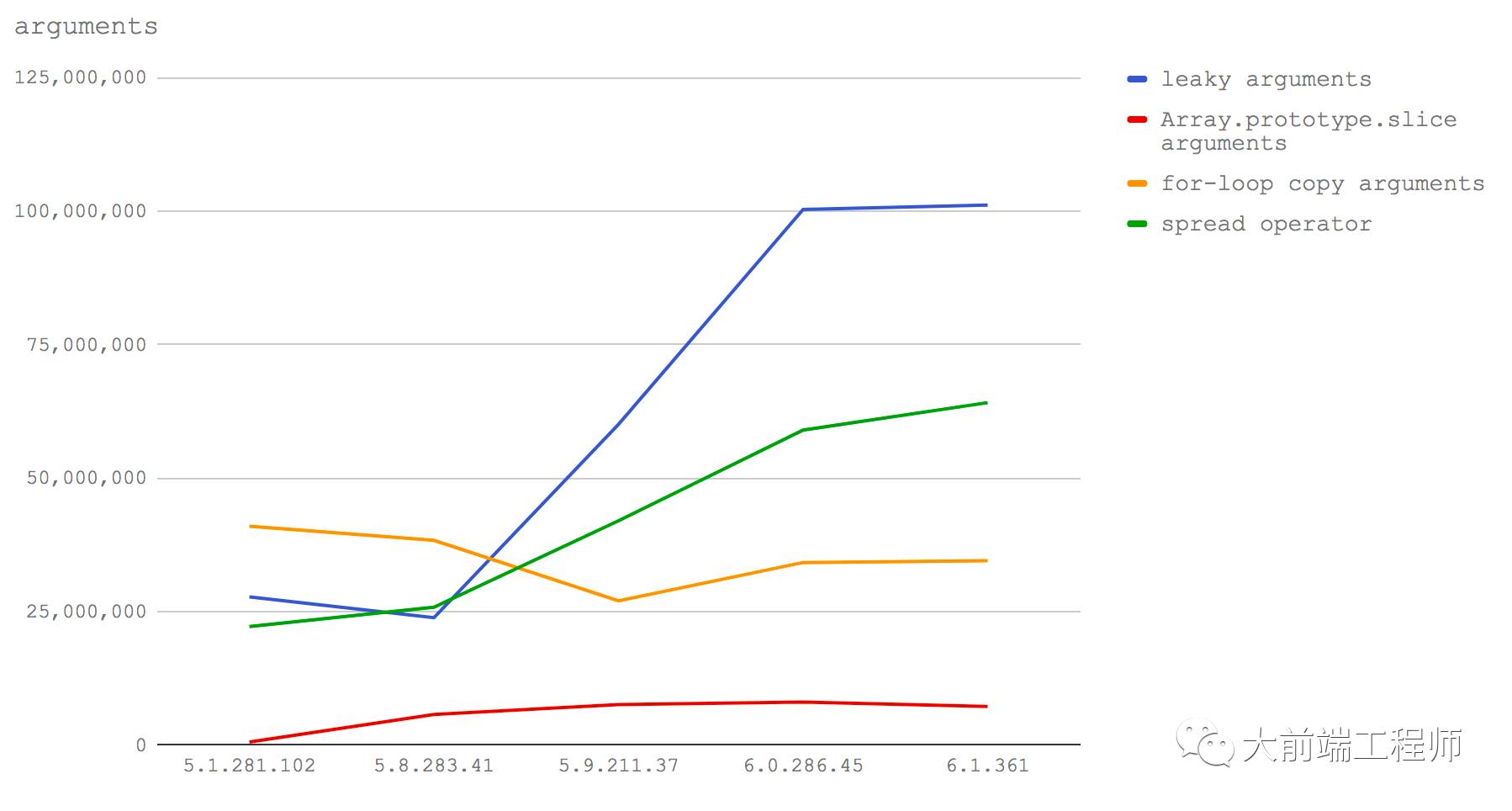
总结来说,就是假如我们想写出高性能的代码来把函数输入处理成数组(以我的经验这种需求非常常见),在 Node 8.3 或者更高版本我们应该使用 spread 操作符。而在 Node 8.2 和更低版本上,我们应该使用 for 循环来把 arguments中的值复制到一个新的(已经预分配了空间的)数组中去(你可以去看一下我们的测试代码就知道具体该怎么做)。
同时,在 Node 8.3+ 版本上,把 arguments对象暴露给其它函数不再会导致性能下降,所以如果我们并不需要一个完整的数组,如果直接操作这个类数组结构也可以满足需要的话,那么我们完全可以直接把 arguments对象传递出去,这样做的性能反而更好。
柯里化与函数绑定
柯里化是一种让我们可以在嵌套的闭包里存储状态的方式。
例如:
function add (a, b) {
return a + b
}
const add10 = function (n) {
return add(10, n)
}
console.log(add10(20))
在这个例子中,函数 add的参数 a在函数 add10中被固定设置为 10。
运用 EcmaScript 5 中提供的 bind方法,可以把上面这个例子简化为:
function add (a, b) {
return a + b
}
const add10 = add.bind(null, 10)
console.log(add10(20))
但是由于 bind的性能明显慢于闭包,一般情况下我们不会使用 bind。
下面这个测试比较了 bind和闭包在我们测试的几个 V8 版本上的表现。
我们比较了下面四种情况:
一个函数,它调用另外一个函数,且调用时将第一个参数给定,形成一个柯里化函数(curry)
用箭头形式写一个函数,它调用另外一个函数,且调用时将第一个参数给定(fat arrow curry)
通过
bind方式来生成的一个柯里化函数(bind)直接调用一个函数,不要使用柯里化(direct call)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/currying.js
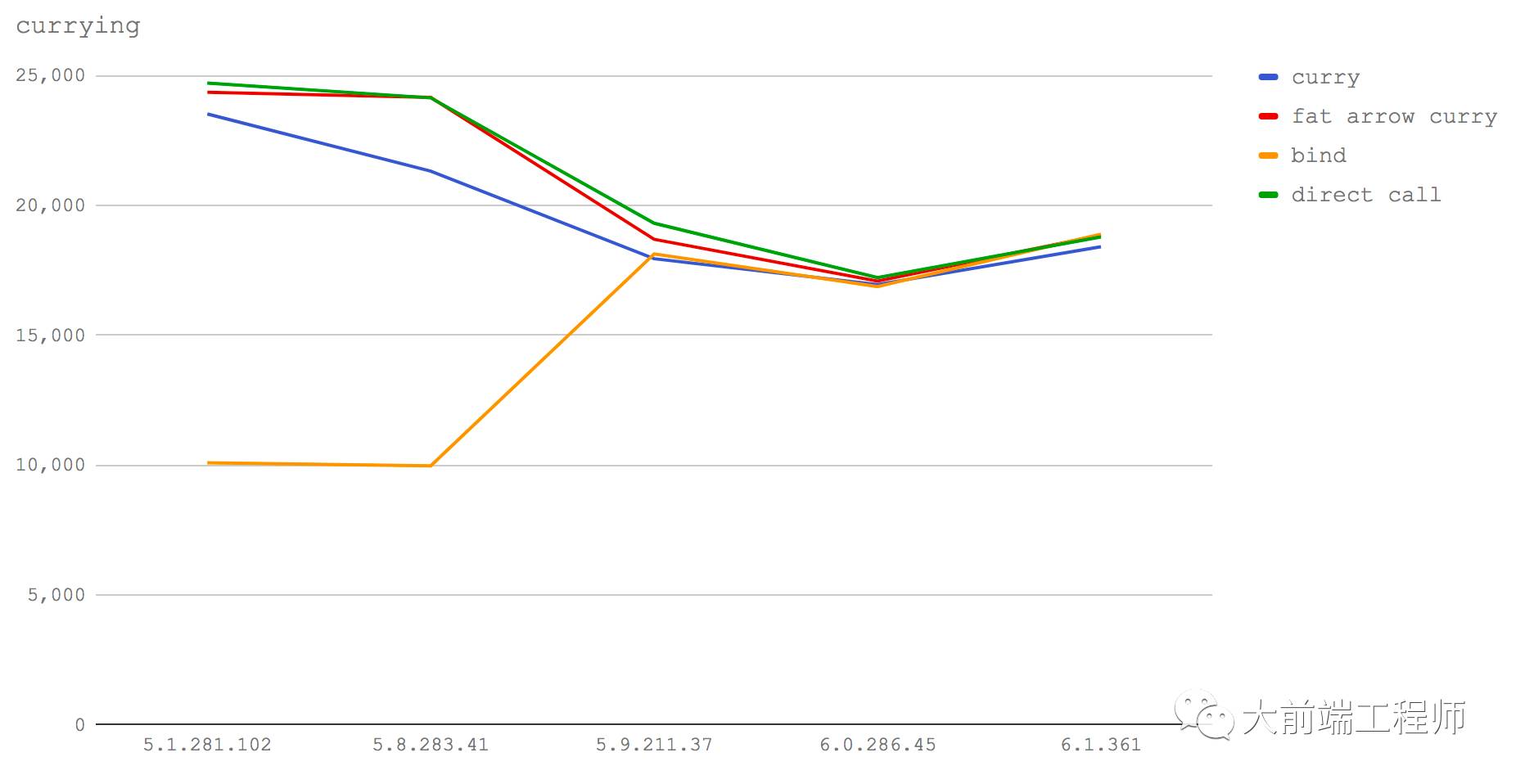
这张线状图清晰地反映出随着 V8 的版本演进这几种不同的代码形式是如何在性能上逐步趋于一致的。有趣的是,使用箭头函数形成的柯里化函数居然明显比普通函数快(至少在我们的测试用例中是如此),性能甚至接近了直接调用方式。在 V8 5.1(Node 6)和 5.8(Node 8.0-8.2)上,相比之下 bind性能最差,而箭头函数则是最快的方式。但从 V8 5.9(Node 8.3+)开始, bind的速度提升了一个数量级,并在 V8 6.1(未来的 Node) 上变成了最快的一种方式(尽管这种领先优势很小,可以忽略不计)。
综合考虑我们所测试的各个 V8 版本,箭头函数是最快的选项。在后续版本上其性能也与 bind相差无几,而目前它比一般函数形式还要快。但这里我们也要注意,可能还需要研究其它更多类型的柯里化方式,结合不同大小的数据结构,才能对这个问题有更全面的认识。
函数长度
函数的长度,包括它的签名、空格、甚至内部的注释都会影响这个函数是否会被 V8 内联优化。可能你不太相信,但在你的函数中添加一段注释,确实有可能会导致 10% 以内的性能下降。在 Turbofan 上这一点会有所变化吗?让我们来看一看。
在这个测试中,我们考察三种情况:
调用一个简短无注释的函数(sum small function)
把上面这个简短函数所做的操作直接以内联方式在测试中执行,同时在其前面添加一大段注释(long all together)
向那个简短函数中添加一大段注释,然后调用它(sum long function)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/function-size.js
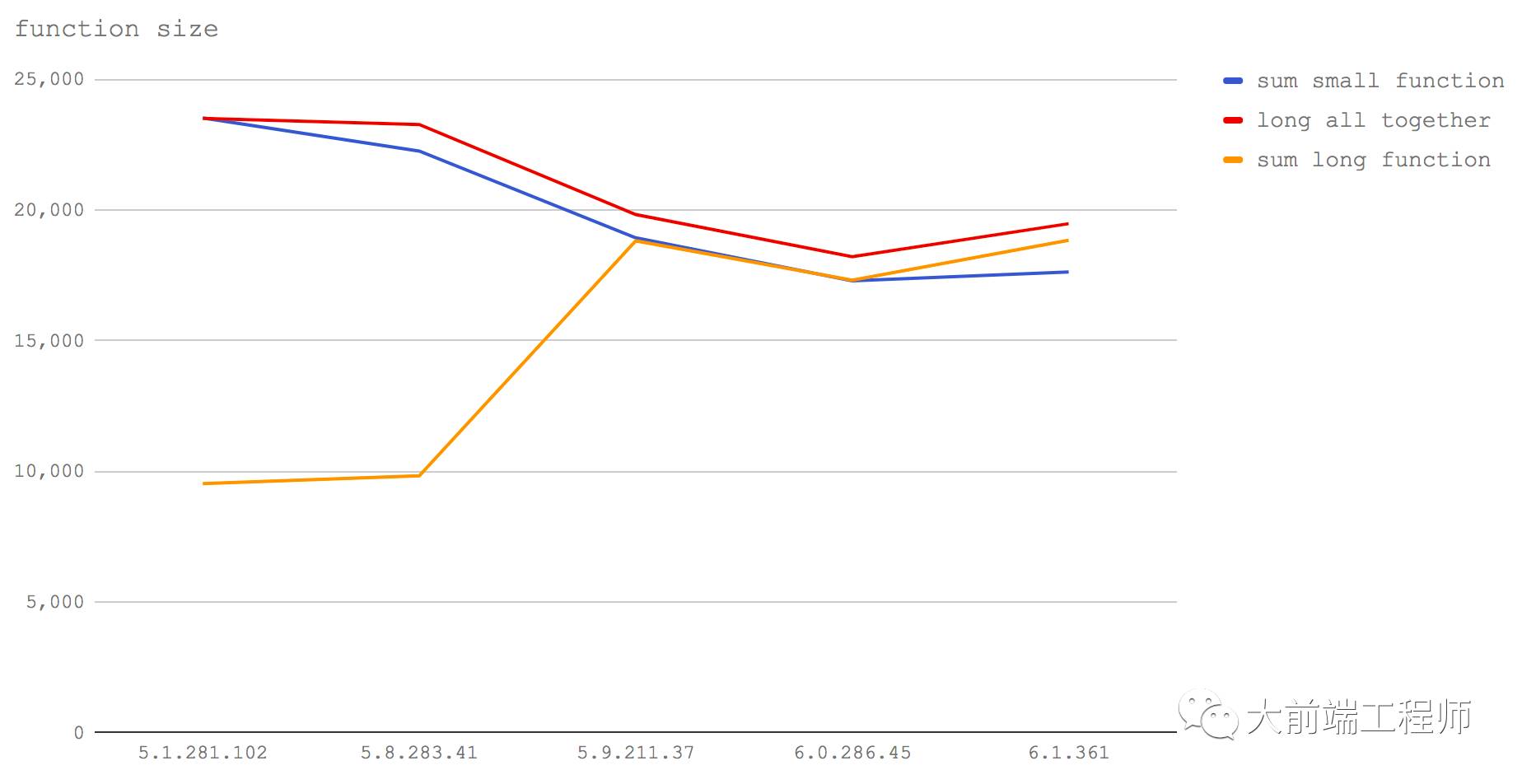
在 V8 5.1(Node 6)中,“sum small function” 和 “long all together” 的性能一致。这其实反映出简短函数被内联化了。当我们调用一个小的函数时,其行为就像是 V8 把这个函数的内容直接写到了调用它的地方。所以第二个测试用例其实就相当于我们人为做了函数的内联,因此性能表现完全一致。同时我们也可以看到,在 V8 5.1(Node 6)中,当一个函数里包含了大段注释,它的运行效率将会严重下降。
在 Node 8.0-8.2(V8 5.8)中,情况也差不多,除了小函数调用的开销有所增加。这个问题可能是由于 Crankshaft 和 Turbofan 同时存在所导致的。一个函数可能在 Crankshaft 中而其它函数可能在 Turbofan 中,从而导致函数无法进行连续的内联(也就是说不得不在两个内联函数簇之间跳转)。
在 5.9 和之后的版本中(Node 8.3+),由空格、注释这样的无关内容导致的函数长度变化不再对性能产生影响。这是由于 Turbofan 不再像 Crankshaft 那样用字符数来计算函数长度,而是基于函数内实际包含的操作指令数量,把函数的 AST(Abstract Syntax Tree,抽象语法树)节点数量来作为判断依据。这样,从 V8 5.9(Node 8.3)开始,空格、变量名字符数、函数签名和注释都不再会影响一个函数是否会被内联优化。
同时值得注意的是,可以看到函数执行的整体性能有所下降。
在这个问题上,我们给出的结论是,我们应该继续让函数保持简短。在眼下这个阶段,我们还是必须要避免在函数内部存在过多的注释(甚至还有空格)。假如你对速度有极致追求,那么自己手工内联这些函数(也就是去除函数调用)才是最快的方式。当然,这里我们还要注意要找到一个平衡点,复制粘贴其它函数到你的函数里也会导致你的函数本体尺寸变得过大,有可能不再会被内联优化。所以手工内联反而有可能会伤及自身,在大多数情况下最好还是把这件事交给编译器去做。
32位整数 VS 双精度浮点数
众所周知,JavaScript 只有一个数值类型: Number。
而 V8 是用 C++ 实现的,所以 V8 需要选择一个底层类型来表达 JavaScript 中的数值。
对于整数(也就是我们在 JS 中声明了一个没有小数的十进制数字)而言,V8 首先假设所有的数字都能以 32 位整数形式描述。这个选择看上去非常合理,因为在大多数情况下,数字都会在 -2147483648 - 2147483647 范围内。如果一个 JavaScript 数字超过了 2147483647,JIT 编译器就会动态地把数值的底层类型变为双精度浮点数。这时,就有可能会对其它一些优化机制产生负面影响。
接下来这个测试考察如下三种情况:
一个函数,它只处理在32位范围内的整数(sum small)
一个函数,它处理的数值既有在32位范围内的整数,也有超出此范围而需要使用双精度浮点数表达的整数(from small to big)
一个函数,他只处理需由双精度浮点数表达的整数(all big)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/numbers.js
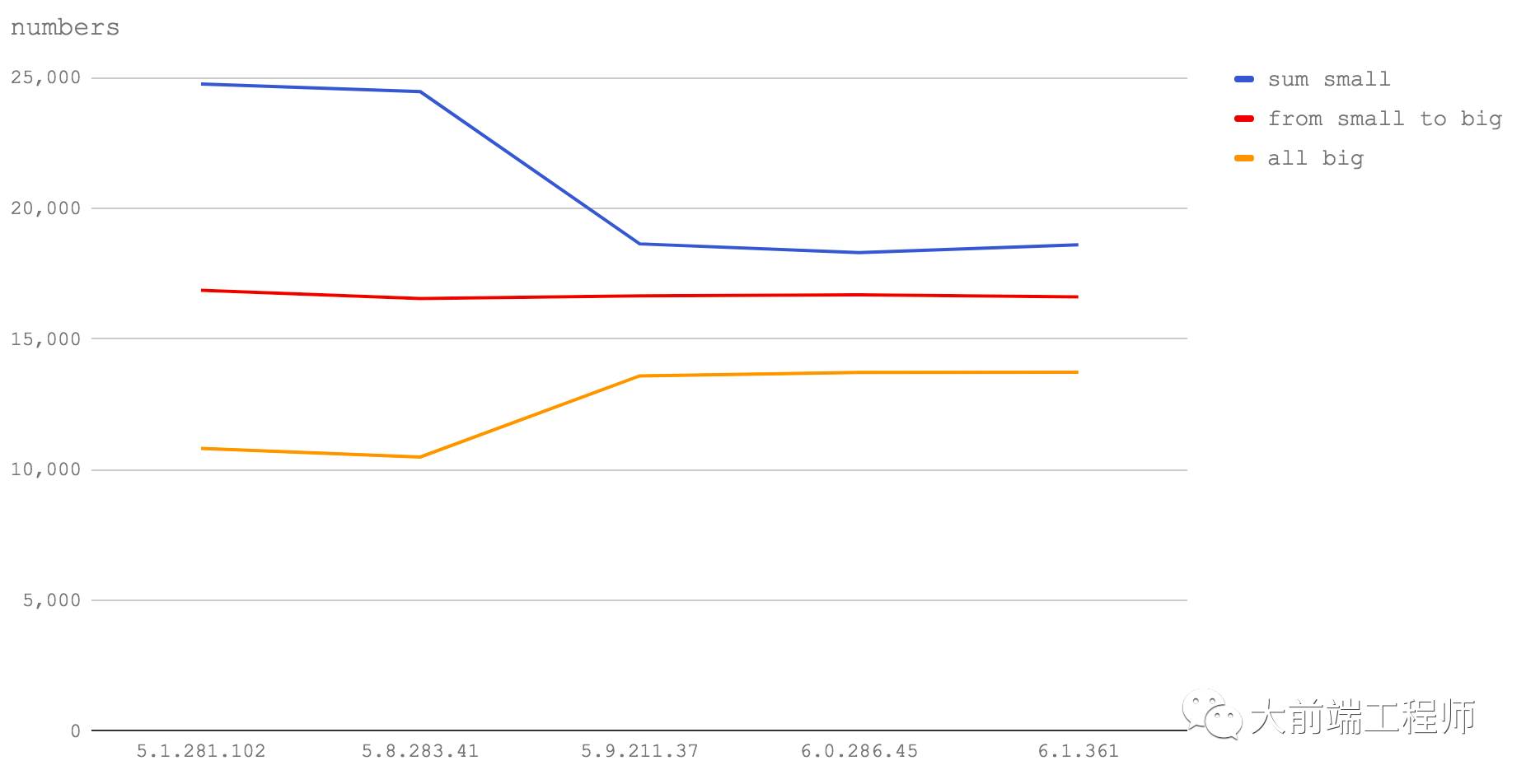
从这幅图我们可以看出无论是 Node 6(V8 5.1)还是 Node 8(V8 5.8)甚至包括 Node 的未来版本,我们在上文中的讨论都是正确的。操作大于 2147483647 的整数会导致函数的运行速度降低三分之一到一半。因此如果你在使用长整数来存储 ID,不妨用字符串来代替它们。
另外值得注意的是,从 Node 6(V8 5.1)到 Node 8.1/8.2(V8 5.8),32 位范围内的整数操作的速度略有下降,但到 Node 8.3+(V8 5.9+),下降就非常明显了。而对大整数操作的速度则从 Node 8.3+(V8 5.9+)开始有了明显的提升。这也恰恰说明,32 位范围内的整数操作可能确实变慢了,并且并非是由函数调用以及 for循环(在测试代码中使用的)方面的性能变化所致。
感谢 Jakob Kummerow 和 Yang Guo 以及 V8 团队在这一测试结果的精确性方面给予的帮助。
遍历对象
从一个对象中提取所有的属性值然后进行处理,这是一个在开发中很常见的任务。有很多方式可以实现这个功能。下面我们来看一下在被测试的几个 V8/Node 版本上哪种方式是最快的。
我们比较了下面四种方式:
使用
for-in循环和hasOwnProperty来取得一个对象的所有值(for in)使用
Object.keys获得一个包含对象所有 key 的数组,然后使用数组的reduce方法遍历此数组,在遍历函数中获取对象的值(Object.keys functional)使用
Object.keys获得一个包含对象所有 key 的数组,然后使用数组的reduce方法遍历此数组,在遍历函数中获取对象的值。同时,这个遍历函数写成箭头函数形式(Object.keys functional with arrow)使用
Object.keys获得一个包含对象所有 key 的数组,然后用for循环遍及这一数组并获取对象的值(Object.keys with for loop)
对于 V8 5.8、5.9、6.0和6.1,我们还测试了额外三种情况:
使用
Object.values获得对象的值数组,并用数组的reduce方法遍历它(Object.values functional)使用
Object.values获得对象的值数组,并用数组的reduce方法遍历它。同时,这个遍历函数写成箭头函数形式(Object.values functional with arrow)用
for循环遍历Object.values返回的数组(Object.values with for loop)
因为 V8 5.1(Node 6)不支持 EcmaScript 2017 原生的 Object.values方法,我们没有对其进行上述这三种额外测试。
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-iteration.js
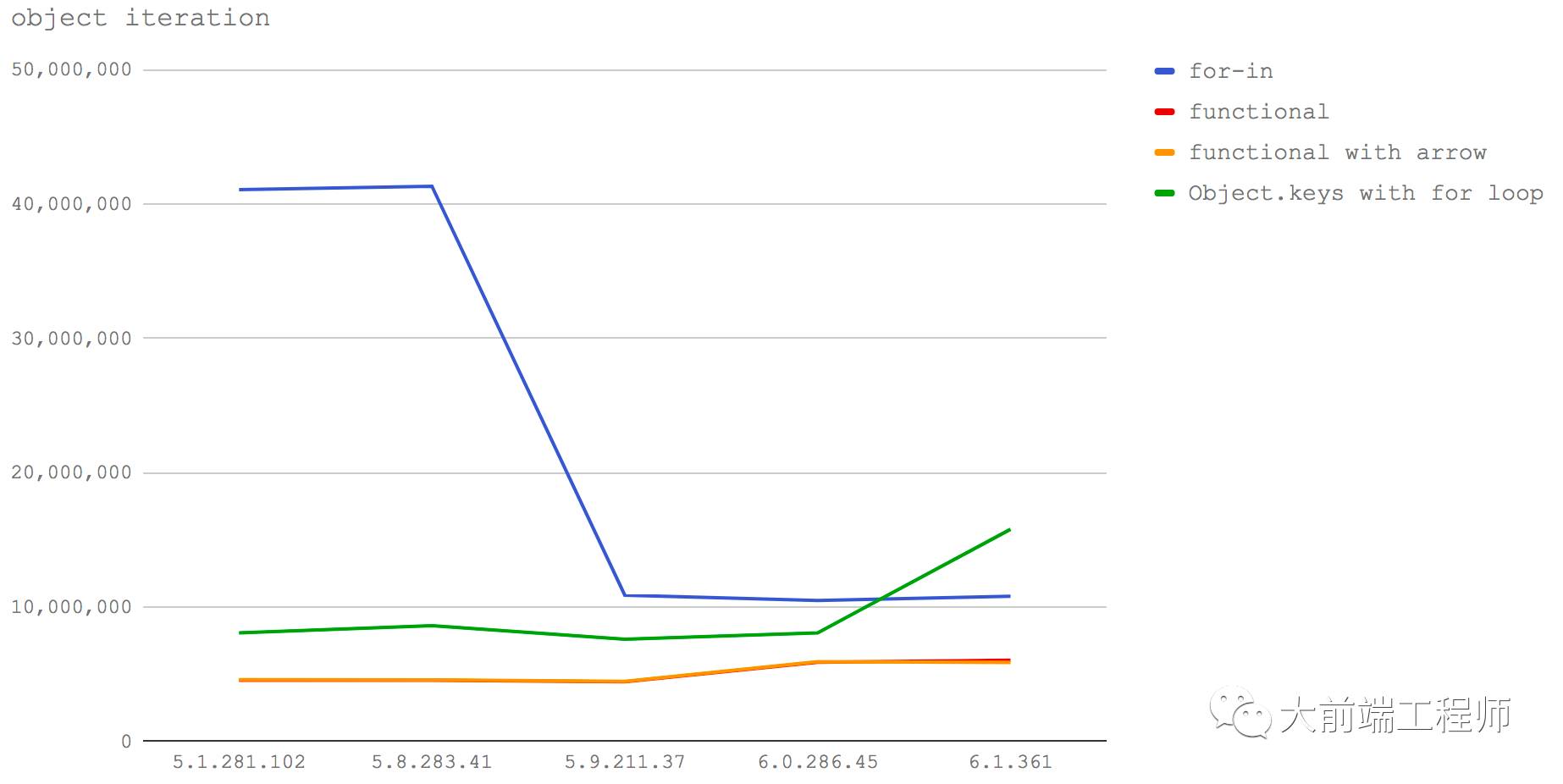
在 Node 6(V8 5.1)和 Node 8.0-8.2(V8 5.8)中,速度最快的方式是通过 for- in来遍历获得对象的 key 进而取得对应的值,大约每秒可以进行 4000 万次操作。而后面几种基于 Object.keys的方式最快的也只有每秒 800 万次的速度,仅为前者的五分之一。
而在 V8 6.0(Node 8.3)上, for- in的速度直线下降到了之前的四分之一,但即使这样它也还是比其它方式更快。
再到 V8 6.1(Node未来版本), Object.keys的速度得到了提升并超过了 for- in,但仍然远远不及 V8 5.1 和 5.8(Node 6 和 Node 8.0-8.2)时的 for- in。
Turbofan 背后似乎有着这样一个设计原则,就是它是为符合直觉的编码形式进行性能调优的。也就是说,那些对开发者来说感觉最自然的编码形式应该会得到引擎的优化。
但使用 Object.values来直接取值的做法要慢于先 Object.keys然后循环取值的方式。这说明过程式的循环模式仍然要比函数式的编程模式要快。所以当我们对对象进行遍历操作时,恐怕还是不能用 Object.values这么简单的方式。
而过去由于 for- in的速度优势,很多人都喜欢使用它,但现在就比较痛苦了:新的 V8 里这种方式的速度将会急剧下降,并且也暂时没有可以达到之前那么快速度的替代手段。
对象创建
在我们的代码中,新对象的创建无处不在,因此这也是一个非常有意义的测试点。
我们将看一下下面三种情况:
使用对象字面值创建对象(literal)
用一个 EcmaScript 2015 类来创建对象(class)
使用构造函数来创建对象(constructor)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-creation.js
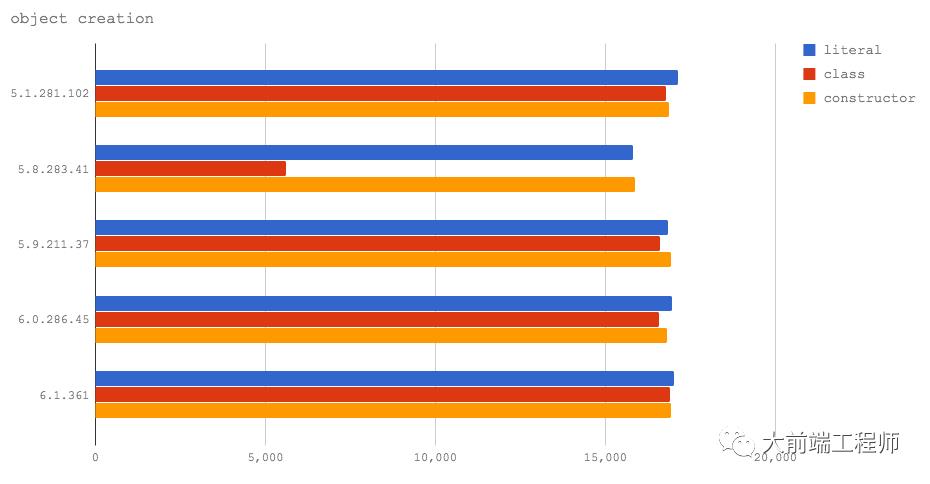
在所有被测试的 V8 版本上,创建对象的时间消耗都差不多,除了在 Node 8.2(V8 5.8)上使用类的方式明显慢于其它方式。这是由于在 V8 5.8 上混合使用 Crankshaft 和 Turbofan 所致,这个问题在 Node 8.3(V8 6.0)中已经被解决了。
“消除”对象创建
在准备这篇文章的过程中,我们曾发现 Turbofan 对某种特定的对象创建方式做了相当不错的优化。本来我们误以为这种优化对所有的对象创建方式都有效,但感谢来自 V8 团队的帮助,让我们理解了什么样的条件下才会触发这种优化。
在前面“对象创建”一节中的测试里,我们把新创建的对象赋给一个变量,再把它设为 null,然后再重新为它赋值。这样才避免了触发下面我们将要看到的这种特殊的优化模式。
接下来这个测试中我们仍然考察与上面的测试相同的三种情况:
使用对象字面值创建对象(literal)
用一个 EcmaScript 2015 类来创建对象(class)
使用构造函数来创建对象(constructor)
不同的是,持有对象引用的变量不会再被下一次新创建的对象所覆盖,这个对象会被传递给另外一个函数来执行一些别的操作。
让我们来看一下这次的结果!
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/object-creation-inlining.js
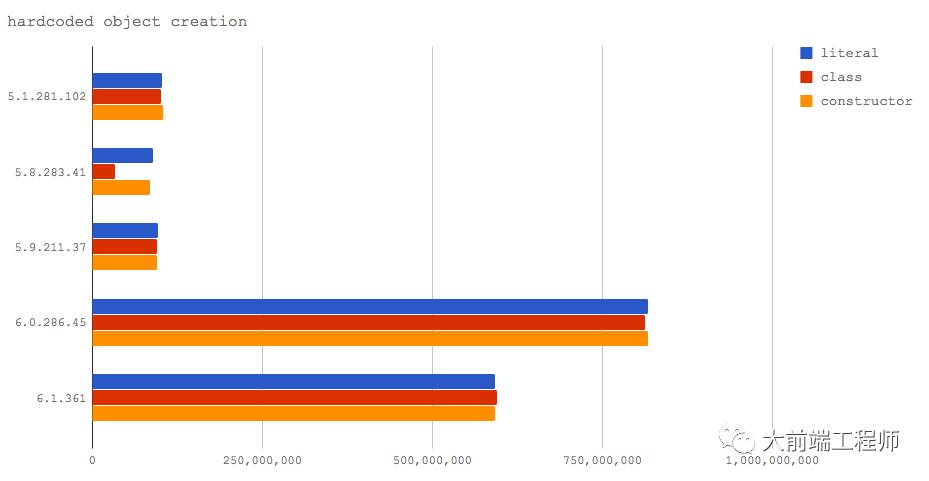
你会发现,对于这种情况,V8 6.0(Node 8.3)和 6.1(Node 9)的速度有了一个飞跃式的提升,每秒操作次数超过了 5 亿次。这主要是因为一旦你的代码触发了 Tubofan 的这种优化,实际上引擎在整个过程中并没有真正地创建对象,相当于它没做什么事情。在这种场景下,Turbofan 能够判断出后续代码逻辑的执行实际上并不需要创建一个真正的对象,所以它启动优化跳过了对象创建。
上述的测试代码并未完全表现出触发这一优化的可能条件,其触发条件其实是非常复杂的。
但现在我们可以确定的是有一种情况必然不会触发 Turbofan 的这种优化:
对象的生命周期一定不能长于创建它的那个函数。也就是说,在创建对象的函数结束执行后,就不能再存在指向这一对象的引用了。这个对象可以被传递给其它函数,但如果我们把它添加到 this上,或者把它赋给在函数作用域之外的一个外部变量,或者把它添加到其它对象中而这些对象的生命周期又长于创建那个对象的函数时,这一优化必然不会发生。
上面这个测试结果固然非常漂亮,可我们又很难预测出所有可以触发优化的条件。但只要你的代码满足了它所需要的条件,它就会为你带来巨大的速度提升。
感谢 Jakob Kummerow 以及 V8 团队的其他成员帮助我们弄清楚了这一代码行为背后的原因。在研究过程中,我们还发现了 V8 新的 GC 引擎 Orinoco 中的一个性能退化问题。如果你有兴趣,可以查看 https://v8project.blogspot.it/2016/04/jank-busters-part-two-orinoco.html 和 https://bugs.chromium.org/p/v8/issues/detail?id=6663。
多态 VS 单态
当我们总是向一个函数传入同一类型的参数时(比如说总是传入一个字符串),就是在以单态的方式使用这个函数。
有的函数则被写成了可以支持多态的形式。我们可以想象得出这样一个函数,在同一个参数位置上它可以接受不同类型的输入。例如一个函数可以接受一个字符串或者一个对象作为它的第一个参数。但是在这里,我们所说的“类型”,并非是指字符串、数值或者对象这种类型概念,我们说的是对象的结构(实际上在 JavaScript 中,不同数据类型的对象也可以被认为是具有不同结构的对象)。
对象通过它的属性和值来定义其结构。例如下面这段代码, obj1和 obj2具有相同的结构,但 obj3和 obj4的结构则与其它对象不同:
const obj1 = { a: 1 }
const obj2 = { a: 5 }
const obj3 = { a: 1, b: 2 }
const obj4 = { b: 2 }
出于良好的接口设计目的,我们有时候会用同样一段代码来处理不同结构的对象,但是这样会对性能带来负面影响。
下面让我们来看一下单态和多态代码在我们测试中表现。
我们考察了两种情况:
在一个函数中我们让它处理不同结构的对象(polymorphic)
在一个函数中我们只让它处理相同结构的对象(monomorphic)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/polymorphic.js
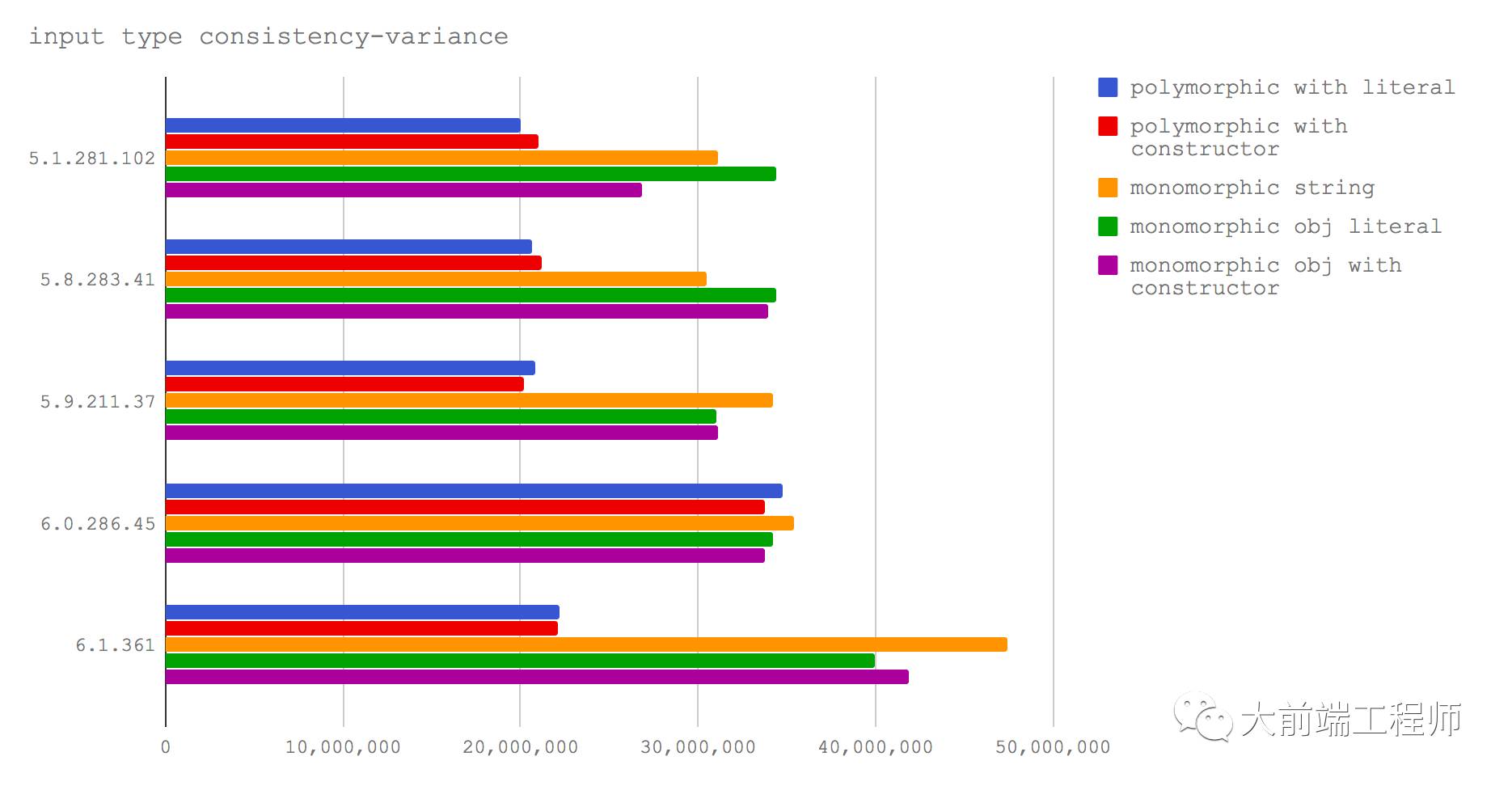
这幅图毋庸置疑地反映出无论在被测试的哪个 V8 版本上,单态函数的性能都要优于多态函数。可是,多态函数的性能在 V8 5.9 之后开始有所改善(也就是从 Node 8.3 开始,它使用的是 V8 6.0)。
在 Node.js 的代码中多态函数是非常常见的,它们为 API 带来了巨大的灵活性。感谢这个关于多态函数的性能提升,那些比我们的测试代码更为复杂的 真实的 Node.js 应用将因此而受益。
如果我们正在写一些需要特别优化的代码,比如一个会被调用很多次的函数,那么我们应该保证传给这个函数的参数对象的结构保持一致。反之,如果一个函数只可能被调用一两次,例如一些初始化函数,那么把它设计成多态形式也是可以接受的。
感谢 Jakob Kummerow 为这个测试提供了一个更为可靠的代码版本。
debugger关键字
最后,我们来谈一下 debugger关键字。
一定要彻底去除你代码中的 debugger语句。零星遗留在代码里的的 debugger会降低性能。
我们来看两个例子:
一个包含
debugger关键字的函数(with debugger)一个不包含
debugger关键字的函数(without debugger)
代码:https://github.com/davidmarkclements/v8-perf/blob/master/bench/debugger.js
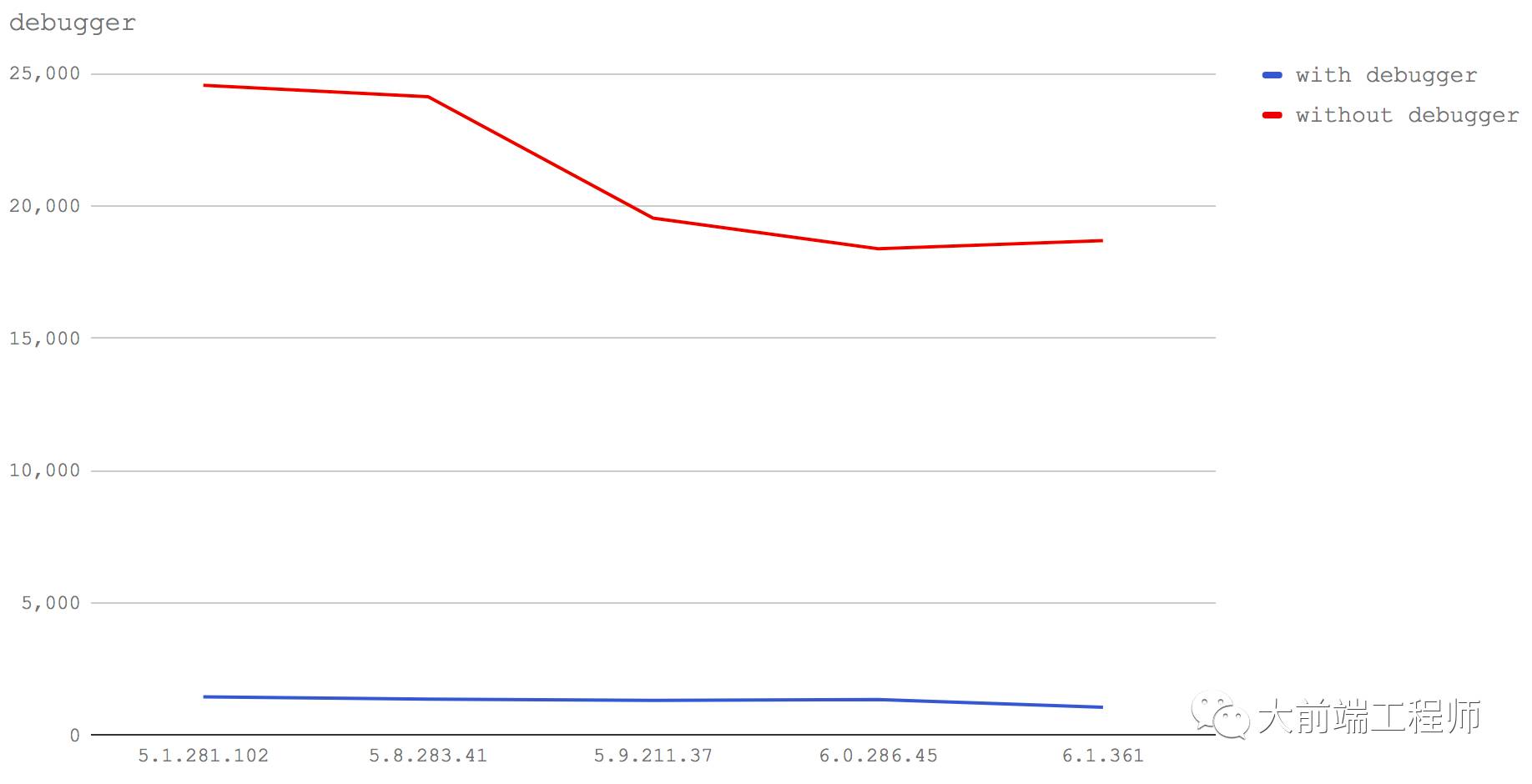
非常明显,仅仅是出现了一个 debugger,在所有的测试的 V8 版本上都带来了巨大的性能下降。
另外,对于后续的几个 V8 版本,without debugger 那个测试用例也出现了一些性能下降,关于这个问题我们留到最后总结的部分再讨论。
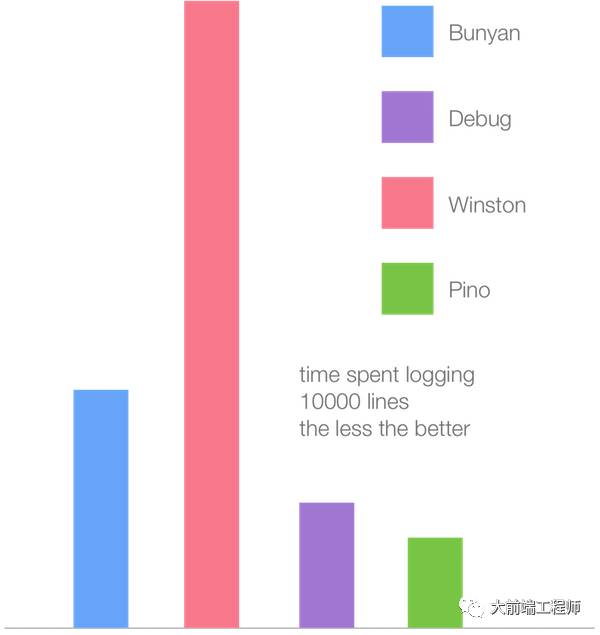
一个真实世界中的测试:日志工具的性能比较
除了上面这些小规模的性能测试之外,我们还可以通过一个真实世界中的实例来看一下 V8 版本变化带来的整体性能影响。我和 Matteo 在开发 Pino 的过程中,搜集并对最常用的几个 Node.js 日志工具进行了性能测试。
下面这幅柱状图反映的是在 Node 6.11(Crankshaft)中,这些最常见的日志工具记录 1 万行日志所消耗的时间(越少越好):
而接下来这幅图是在 V8 6.1(Turbofan)上进行相同测试的结果:
虽然在新的 JIT 编译器 Turbofan 上所有日志工具的速度都有所提升(大约是之前的两倍),但其中 Winston 的改善幅度是最大的。似乎这正反映了我们在上述多个测试中所观察到的所谓性能趋同现象:在 Crankshaft 中速度比较慢的代码形式在 Turbofan 中获得改善明显更多,而在 Crankshaft 中执行比较快的代码则在 Trubofan 中会有一些速度上的降低。在上面这个测试中,Winston 本来是最慢的,它可能使用了一些在 Crankshaft 中执行较慢但在 Tubofan 中快得多的代码写法;而 Pino 则曾经针对 Crankshaft 进行过专门优化,所以虽然在 Tubofan 上其速度也有提高,但幅度要小得多。
总结
上面的一些测试表明,随着 V8 6.0 和 6.1 中 Turbofan 的全面应用,一些在 V8 5.1、5.8 和 5.9 中的较慢的做法会变得更快,但同时一些原先较快的代码也会变慢,其增减幅度往往是一致的。
这种现象很大程度上源于 Turbofan(V8 6.0 及以上)中进行函数调用的开销。Turbofan 在性能改善方面的思路就是对最常见的用法进行优化,消除那些明显为人所知的性能痛点。这样它一方面为运行于浏览器(Chrome)和服务器端(Node)的应用带来了在性能上总体的改善,但另一方面也伴随着妥协,对于原本经过专门优化的最高性能代码,显然会带来速度上的降低(可能将来还会再改善)。我们对日志工具的测试也表明,Turbofan 为我们带来的是全面的性能改善,即便是完全不同的代码库(比如 Winston 和 Pino)也都会得到速度上的提高。
如果你长期以来一直关注 JavaScript 性能问题,并且为了适应底层引擎的“怪癖”而改写代码来获得高性能,那么现在你应该去忘记一些过去常用的技巧了;如果你一直以来都致力于按照最佳实践来编写一般意义上的“好”代码,那么感谢 V8 团队的辛勤努力,你将会迎来一份性能改善的大礼包。
这篇文章由 David Mark Clements 和 Matteo Collina 共同撰写, 并由来自 V8 团队的 Franziska Hinkelmann 和 Benedikt Meurer 审阅。
所有的源代码及文章拷贝:https://github.com/davidmarkclements/v8-perf。
测试得出的原始数据:https://docs.google.com/spreadsheets/d/1mDt4jDpN_Am7uckBbnxltjROI9hSu6crf9tOa2YnSog/edit?usp=sharing
大多数测试都是在一台 Macbook Pro 2016 上进行,搭配 3.3 GHz Intel Core i7 CPU 和 16GB 2133 MHz LPDDR3 内存。其它测试(包括数值、属性删除、多态、对象创建)则是在一台 MacBook Pro 2014 上进行的。每台测试机器上都部署了所有被测试的 Node.js 版本。我们也尽力确保了测试过程中没有其它程序来干扰测试结果。
我的文章回顾:
以上是关于新 V8 为 NODE.JS 带来的性能变化的主要内容,如果未能解决你的问题,请参考以下文章