Node.js根本没有float:浮点反序列化错误背后的故事
Posted 前端之巅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Node.js根本没有float:浮点反序列化错误背后的故事相关的知识,希望对你有一定的参考价值。
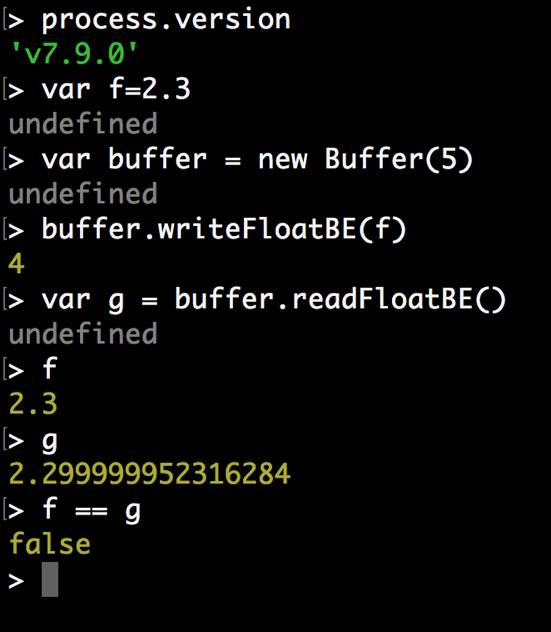
在 Node.js 中,当我们把一个浮点数序列化,再反序列化:
var f = 2.3;
var buffer = new Buffer(1024);
buffer.writeFloatBE(f);
var g = buffer.readFloatBE();
console.log(f == g);我们会发现,再也取不出之前的值了:
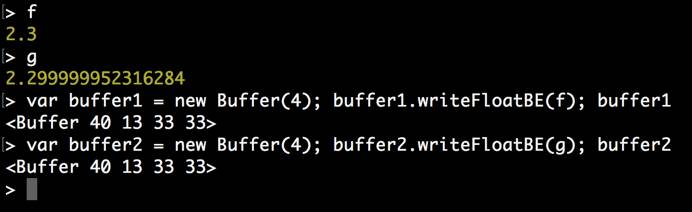
然而,如果再序列化回去,发现结果还是相同的:
这是为什么?
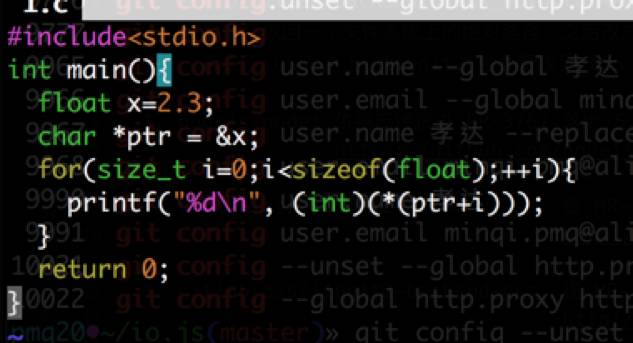
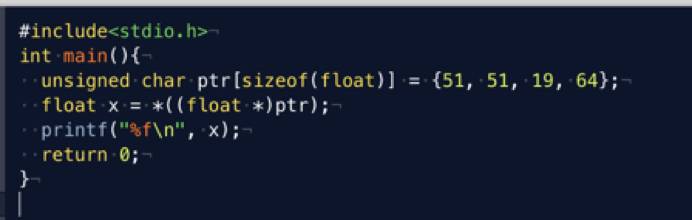
问题是不是出现在序列化的环节?为此,我们编写了一个 C 语言程序对同一个浮点数进行序列化:
注意到 51、51、19、64 等价于 0x33、0x33、0x13、0x40,运行后除了存在小端序与大端序的差异外,我们发现序列化结果完全一致:
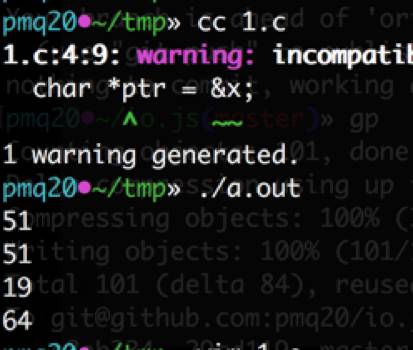
可见,序列化的环节 C、Node.js 两者完全相同,没有任何问题。接下来,让我们试验一下用 C 语言反序列化这个浮点数能得到怎样的结果:
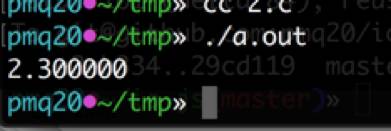
C 语言的将二进制浮点数转为十进制可以得到正确的结果,我们判定问题很可能出在 Node.js 的二进制浮点数转十进制的算法上。
我们找出 glibc 的源码,发现逻辑位于 printf_fp.c 的 ___printf_fp 函数内。该函数共一千多行,可见二进制浮点数转为十进制不是个简单的任务:
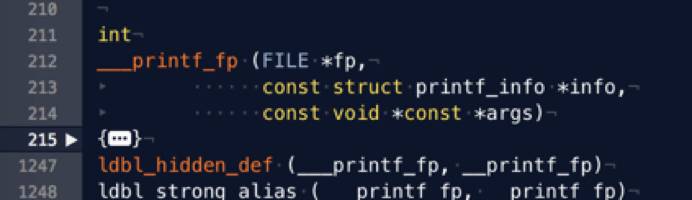
简单阅读源代码发现,它取出了系统当前的 locale(考虑 LC_ALL 环境变量),按照 locale 的不同先找到正确的小数点表示(例如德语里的小数点是逗号,英文里是句号)。随后取出浮点数的各部分,调用各种 mpn 高精度库函数进行各种高精度运算,最后算出浮点数的十进制的表示。
这么有名的标准库,一个函数写一千行,作者肯定是实现了一个著名算法,否则这么复杂的逻辑如何维护得起?果然,我们在 CHANGELOG 的 1992 年的一条记录中发现了所用的算法 —— Dragon4。

那么 javascript 又是什么算法呢?我们在 ECMA 的 9.8.1 章节中找到了解释。原来,JS 多年来遵循的了一套复杂的对数字进行展示的算法。标准该章节的末尾还提示 JS 的实现者参考 David M. Gay 在 1990 年发表的论文《Correctly Rounded Binary-Decimal and Decimal-Binary Conversions》。

首先,阅读 V8 的源码发现,它并没有使用 David M. Gay 的朴素算法。2010 年 Florian Loitsch 发表了论文《Printing floating-point numbers quickly and accurately with integers》,取得了该问题近 30 年来最大的进展,提出了新算法 —— Grisu3,这使得 V8 不用高精度运算库便可以求得二进制浮点数的十进制表示,几乎完胜 dragon4 算法。唯一的缺点是有 0.5% 的浮点数会转换失败,这时 V8 可以聪明地 fallback 到了高精度运算来搞定他们。

其次,输出 2.3 并不是数学上正确的结果。运用一些数学知识进行分析就会发现,有些二进制的浮点数是永远不会转换成漂亮的有限位的十进制小数的。在十进制数系中,只要一个有理数的分母含有 10 的素因子之外的因子,那么他就是一个无限小数。例如 1/15 等于 0.066666 循环,因为 15 含因子 3。这一结论可以使用费马小定理,取 a=10,p=2 或 5 :

同理,在二进制数系中,只要一个有理数的分母含有 2 的素因子(只有 2)之外的因子,那么他就是一个无限小数。所以,本例中的有理数 2.3 = 23/10 的分母的素因子有 2 和 5,含有 2 之外的因子,因此在二进制下的表示是无限的。
然而计算机是有限的,因此在浮点被序列化成 4 个字节的一瞬间,精度就损失了。当反序列化回来的时候,那个输出 2.3 的程序反而在数学上不正确,输出 2.299999952316284 的程序在数学上才是更正确的。现实很残酷。
原来,C 语言的 printf 默认进行了一定有效数字位数的取整,如果我们不断扩大有效数字的位数:
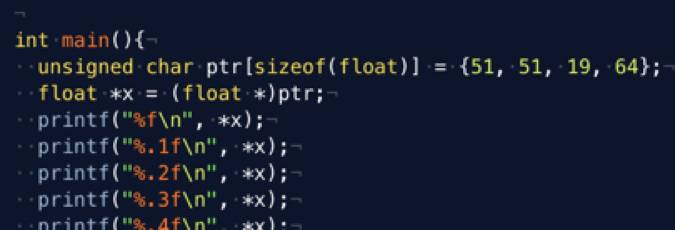
就可以发现,当小数后的有效数字位数设定为 1~7 时,刚好取整到我们想要的十进制结果,其他情况下并无卵:

但是我们回过头来想一想,即便现实世界中的浮点数是残酷的,但 Node.js 也有它做的不对的地方。为什么有同等二进制表示的两个数字,可以被 toString() 成两种结果?而且关于认为它们相等这件事,Node.js 也是拒绝的呢?
原因就是 Node.js 根本没有头发!哦不对,是根本没有 float!V8 引擎中 js 的 Number 对象的内部实现只有两种,一是 smi(也就是小整数),二是 double。Grisu3 算法的实现也只被封装在 DoubleToCString 等函数中,从来没有 FloatToCString 这种处理 float 的函数。
更为坑爹的是,在 readFloatBE 得到 float 值而传入 V8 的一瞬,float 被 C++ 编译器悄无声息地 cast 成 double 了。
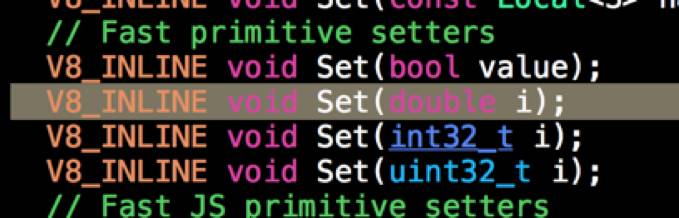
因此,他们的二进制其实是不一致的,因为我们先前只看了前四个字节,没看后四个字节:

首先,如果实在想要像 C 那样得到 2.3,那么需要人工指定取整的位数,用 Number.prototype.toPrecision 函数四舍五入后重新实例化 Number 对象:
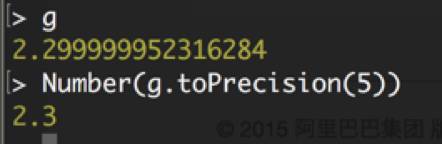
其次,应尽量避免使用 float,如今 double 已经得到服务器的广泛支持,没有必要为了节省内存或带宽弃 64 位不用而使用 32 位。尤其是在没有 float 的 Node.js 的世界里,使用 float 作为数据存储或数据交换格式必然会引入各种与直觉不符的问题。最后,在精度要求高的场合,应牺牲性能,放弃机器原生的浮点数,转而使用 BigDecimal 等无限精度的运算库。
潘旻琦,供职于阿里巴巴集团。Ruby 与 C++ 重度用户。国际技术会议讲师。Node.js 的六位国内 Collaborator 之一。长期关注 Ruby、Node.js 与 V8 等开源项目的社区动态。
今日荐文
Facebook 开源 JavaScript 代码优化工具 Prepack
InfoQ 主办的移动和前端开发领域的精品大会【GMTC 2017】将于 6 月 9~10 日在北京举行,作为首届以“大前端”为主题的大会,GMTC 涉及移动、前端、跨平台、AI 应用等多个技术领域,帮助你方方面面提高技术水平。扫描下图二维码或戳阅读原文,前往官网了解详细信息!

以上是关于Node.js根本没有float:浮点反序列化错误背后的故事的主要内容,如果未能解决你的问题,请参考以下文章
漏洞公告Node.js反序列化远程代码执行漏洞通告CVE-2017-5941
反序列化从 node.js (azure sdk) 发送的 Azure ServiceBus 队列消息时出错
正确生成浮点型的方法,解决sqlachemy Float浮点型的坑,生成float类型时,长度和精度均为0,导致查询不到结果!