朴素贝叶斯算法的案例实现
Posted R语言中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯算法的案例实现相关的知识,希望对你有一定的参考价值。
一、朴素贝叶斯分类的R函数介绍
1、朴素贝叶斯分类算法的实现函数
R中的e1071包中的naiveBayes函数可以实现朴素贝叶斯算法,具体的函数格式如下:
naiveBayes(x, y,laplace=0)
常用变量具体的参数解释如下:
naiveBayes(formula,data,laplace=0,subset)
常用变量具体的参数解释如下:

2、朴素贝叶斯分类算法的预测函数
predict(object, newdata, type=c("class", "raw"))常用变量具体的参数解释如下:

二、具体案例演示
用具体的一个实例来演示朴素贝叶斯算法,并用ROC曲线对模型性能进行评价,具体数据集来自R中mlbench包的自带数据集PimaIndiansDiabetes2,来基于朴素贝叶斯算法识别糖尿病患者。
1、数据解读
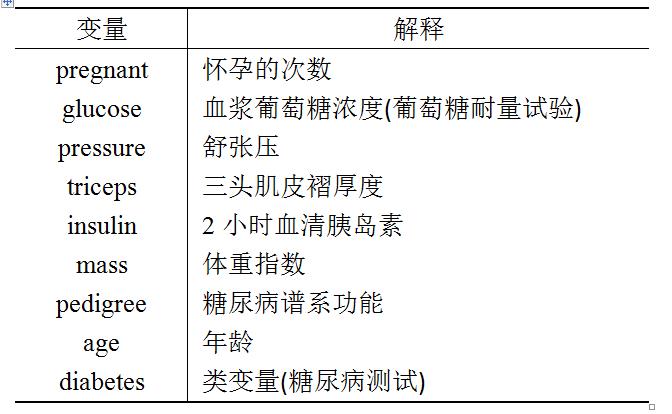
其中最后一个为分类变量,其余为自变量
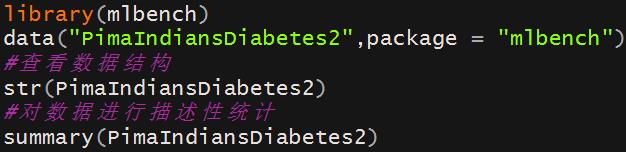
2、代码解释
注:
⑴str函数在查看数据结构时候,类变量必须为因子型变量,如果是其他类型的变量,则在后续分析的时候程序会报错。
(2)summary函数是对数据进行描述性统计,观察有无异常值的情况,如果出现异常值等情况,还可以通过boxplot ,boxplot.stats等函数来进行后续分析
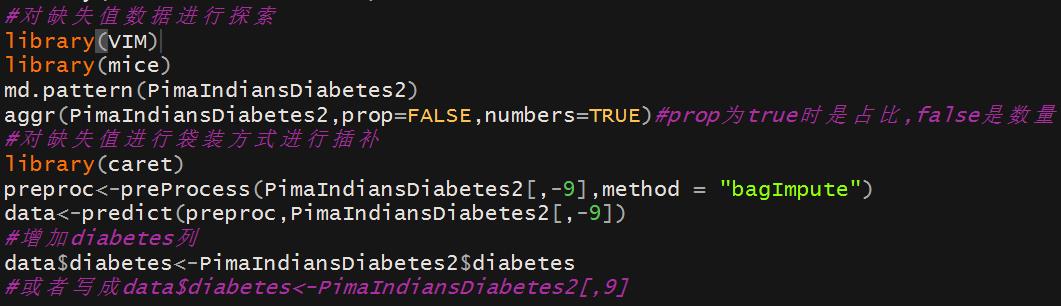
注:
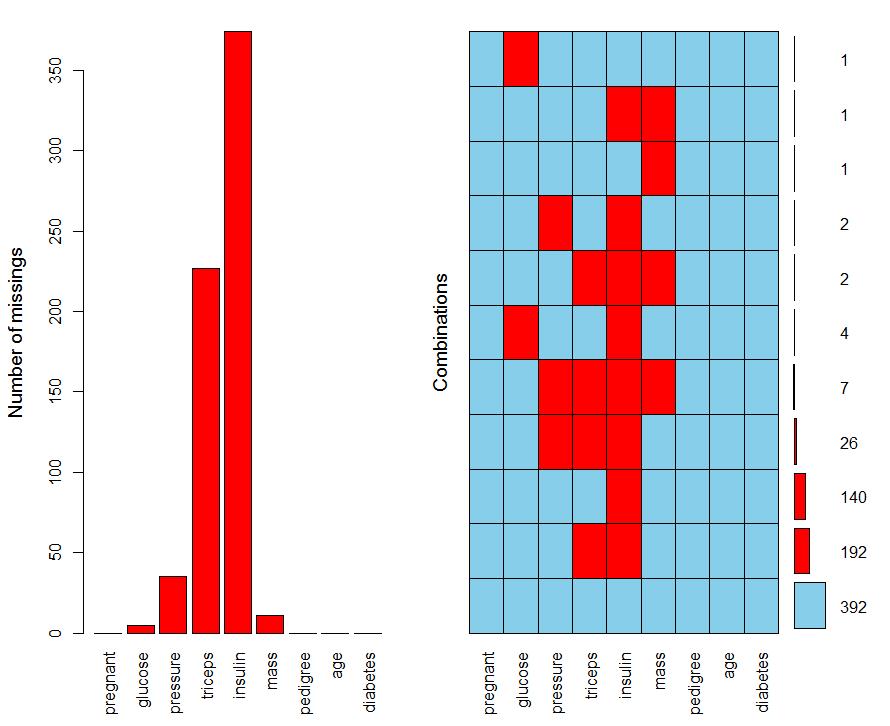
⑴VIM包和mice包可用来对缺失值进行探索,具体的函数有md.pattern,aggr,na.omit,
complete.cases等,以前两个函数居多。aggr对缺失值的可视化探索结果如下:
(2)caret包中的preProcess函数可以进行缺失值的插补工作,由于preProcess函数的用处大大滴,这里重点写一下。
preProcess函数可以进行数据的标准/归一化处理,还可以进行数据缺失值的插补工作,具体的函数格式如下:
preProcess(x, method, na.remove = TRUE, k = 5)常用变量具体的参数解释如下:

注:
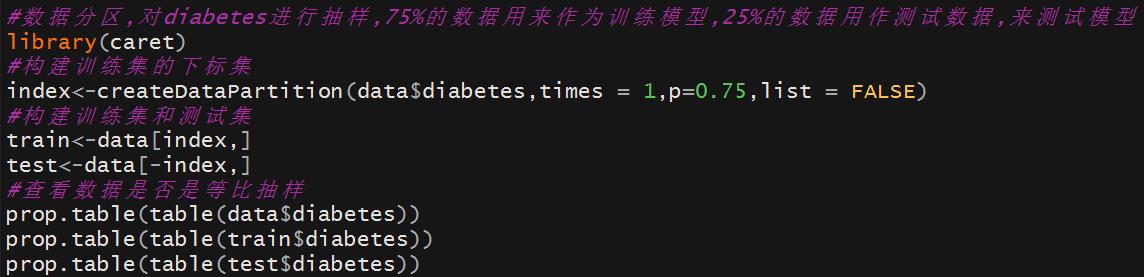
⑴caret包中的createDataPartition函数可以对数据进行等比抽样,具体的函数格式如下:
createDataPartition(x, times=1, p,list=FALSE)
其中times是抽取的次数,1就好;p是抽取的概率,即数据量;list是是否以列表的形式输出,用FALSE,用TRUE后续程序会报错哦
(2)提到抽样,大家会想到sample函数,sample函数是随机抽样(当然具体代码也可以实现等比,但是很麻烦),caret包中的createDataPartition函数是实现等比抽样的好方法。
⑶补充:当要处理不平衡分类的情况,记得想起DMwR包中的SMOTE函数哈!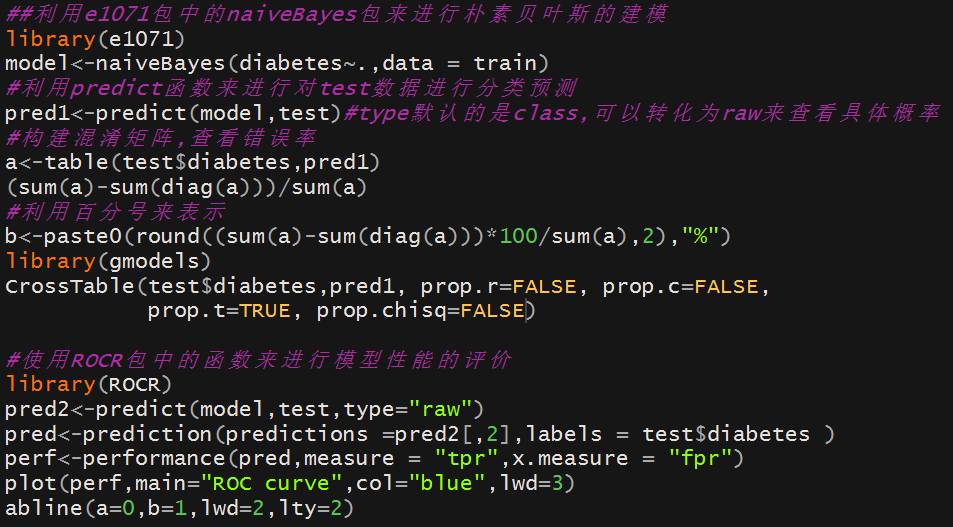
注:
⑴ gmodels包中的CrossTable函数可以来进行模型评估,得到的结果如下:
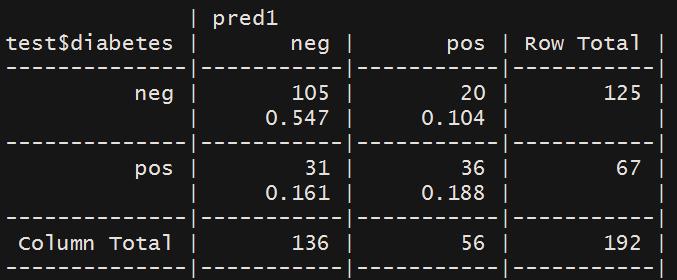
上面这个图可以得到很多模型性能的指标,比如:灵敏性、特异性、精度、假正率等等,下面叙述的ROC曲线就是基于假正率和灵敏性这两个指标绘制的。
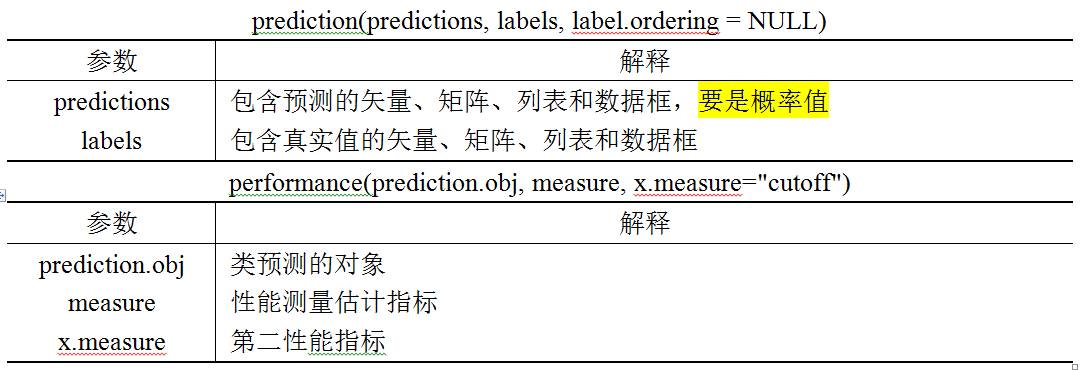
(2) ROCR包中的prediction和performance函数可以联袂绘制ROC曲线,先看一下这两个函数的函数格式如下和常用变量具体的参数解释如下:
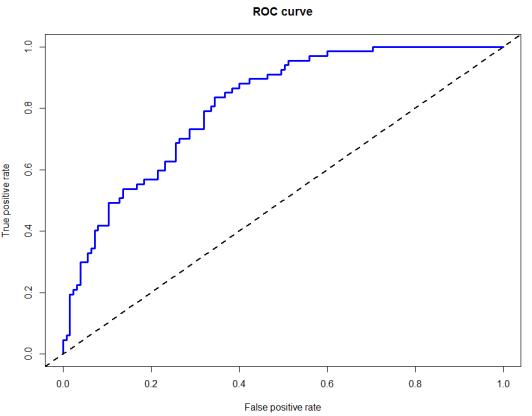
(3)pROC包也可以完成ROC曲线,具体代码如下:
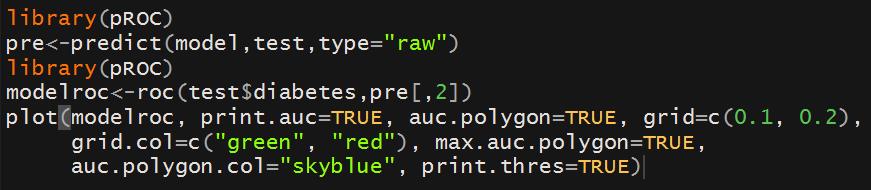
⑷建议用pROC包,AUC值也给出。AUC值的范围是0.5-1,越大说明模型效果越好。
三、总结
模型的预测正确率为73.44%,但是通过gmodels包中的CrossTable函数得到的结果,有31个是阳性却预测为阴性(假阴性),这是很可怕的,说明模型拟合的不好。
本文的目的是为了让大家了解朴素贝叶斯算法的建模流程以及回忆相关函数。
Blog:https://ask.hellobi.com/blog/sunshine0503
以上是关于朴素贝叶斯算法的案例实现的主要内容,如果未能解决你的问题,请参考以下文章