朴素贝叶斯及案例实现
Posted ZacharyWorld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯及案例实现相关的知识,希望对你有一定的参考价值。
贝叶斯方法
贝叶斯方法是以贝叶斯定理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。
概率,亦称“或然率”,它是反映随机事件出现的
可能性(likelihood)大小。某事件A出现的概率,常用表示。
贝叶斯定理
贝叶斯定理源于英国数学贝叶斯(Thomas Bayes)生前为了解决逆向概率问题的一篇文章。
正向概率: 假设袋子里面有n个白球,m个黑球,随意拿一个出来,摸出黑球的概率是多少?这样的就是正向概率问题。
逆向概率: 还是有一个袋子,假设我们不知道袋子里黑白球的比例,当我们进行一定的随意的摸取后,根据摸出球的颜色,推测袋子里黑白球的比例。这样的就是逆向概率问题。
贝叶斯解决的问题
由于实际上的问题是不确定的,而自身的观察能力是有限的。所以有时我们需要通过观察的结果进行推测。贝叶斯方法基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据本身而得出的。其方法为,将关于未知参数的先验信息与样本信息综合,再根据贝叶斯公式,得出后验信息,然后根据后验信息去推断未知参数的方法。
先验概率: 是指根据以往经验和分析得到的概率。事情还没有发生,要求这件事情发生的可能性的大小,是先验概率。
贝叶斯公式
假设一个学校共有个学生,有60%男生和40%女生。女生穿裤子的人数和穿裙子的人数相等,所有男生穿裤子。我们想求解一个穿长裤的学生是女生的概率。记为: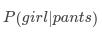
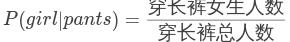

那么穿长裤女生人数为总人数乘以女生的概率再乘以女生中穿长裤的概率: ,所以:
,所以: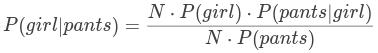
可以看出与总人数无关,于是: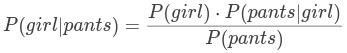
我们可以计算出后验概率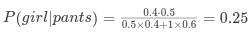
后验概率:指在得到“结果”的信息后重新修正的概率。事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是后验概率。
这样我们也得到了贝叶斯公式,即条件下的概率(记作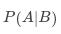 )和条件下的概率(记作
)和条件下的概率(记作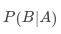 )的关系:
)的关系: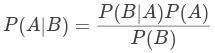
穿长裤的概率=是女生概率x女生穿长裤概率+是男生概率x男生穿长裤概率,于是: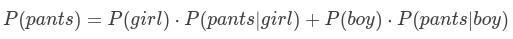
根据全概率公式: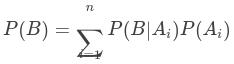
这样,必然事件被分为n个不相交的子事件,事件的条件概率为给定每一个子事件 下事件B的条件概率之和。那么,给定事件
下事件B的条件概率之和。那么,给定事件 ,事件的条件概率可以写为:
,事件的条件概率可以写为: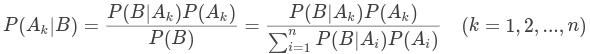
这就是贝叶斯定理。
朴素贝叶斯
朴素贝叶斯使用的就是贝叶斯方法,使用概率统计的知识对样本数据集进行分类,但是在条件上做了一定的限制。
分类方式:在给定的条件下,计算是各个类别的概率,根据最大似然估计,是哪个类别的概率最高,就分类为该类别
朴素贝叶斯假设特征之间(朴素)独立,即特征值相互之间是没有影响的。这是一个非常强的假设,现实中往往很难成立,但简化了问题的复杂度,使求解变得简单。
概率模型
输入特征向量为,,其中为维向量集合;
输出类类别为,,其中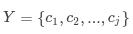 ;
;
得到训练数据集: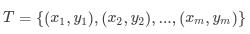
朴素贝叶斯算法通过训练集学习联合概率分布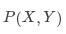 ,
, ,
,
其中先验概率为: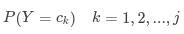
条件概率为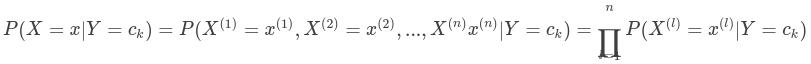
分类时,对给定输入,通过学习到的模型计算后验概率分布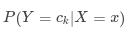 ,将后验概率最大的类作为输入的类输出.后验概率根据贝叶斯定理计算:
,将后验概率最大的类作为输入的类输出.后验概率根据贝叶斯定理计算: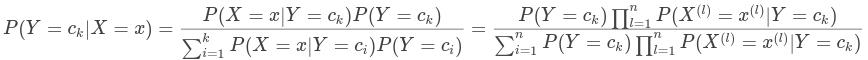
上面的公式是后验概率分布中的一项,对于相同输入下不同类别的后验概率的分母相同,所以我们可以简化为只比较分子的大小就可以确定最终的结果,最终类输出为概率最大对应的类别: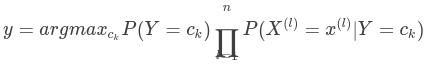
可以通过右式取对数的方式,将连乘化为求和,简化运算得: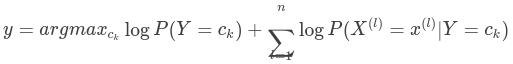
这就是,朴素贝叶斯概率模型。
拉普拉斯平滑
拉普拉斯平滑系数作用是解决零概率问题。就是在计算实例的概率时,如果某个量 ,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
所以假定训练样本很大时,每个分量 的计数加 1 造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
为指定的系数一般为 1, 为训练集中统计的特征值个数。
拼写检查案例
导入使用模块
import re
import collections
处理训练数据集
def words(text):
"""
将训练集转成小写,提取出所有单词
params: text 训练集文本
return: list 单词列表
"""
return re.findall('[a-z]+', text.lower())
def train(features):
"""
单词频率统计
params: list 单词列表
return: dict 词频字典
"""
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
WORDS = train(words(open('words.txt').read()))
计算编辑距离
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edit_distance_1(word):
"""返回编辑距离为1的set"""
n = len(word)
return set([word[0:i]+word[i+1:] for i in range(n)] + # 删除一个字母
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # 交换两个字母位置
[word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # 改变一个字母
[word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # 插入一个字母
def edit_distance_2(word):
"""返回编辑距离为2的set"""
return set(e2 for e1 in edit_distance_1(word) for e2 in edit_distance_1(e1))
拼写检查
def known(words):
"""
返回正确单词的set,默认WORDS中存在的为正确
params: 单词集合
return: 正确单词集合
"""
return set(w for w in words if w in WORDS)
def correct(word):
"""拼写纠正"""
candidates = known([word]) or known(edit_distance_1(word)) or know(edit_distance_2(word)) or [word]
return max(candidates, key=lambda w: WORDS[w])
运行
correct('liko')
'like'
文本分类案例
导入使用模块
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from pprint import pprint
加载数据集
# 使用的是sklearn自带的数据 (18000篇新闻文章,一共涉及到20种话题)
news = fetch_20newsgroups(subset="all")
pprint(list(news.target_names))
['alt.atheism','comp.graphics','comp.os.ms-windows.misc','comp.sys.mac.hardware','comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian','talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
数据处理
# 进行数据分割,分成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集的列表进行重要行统计
x_train = tf.fit_transform(x_train)
print(x_train.shape)
(14134, 145231)
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法预测
mlt = MultinomialNB(alpha=1.0)
print(x_train)
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
# 得出准确率
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:\n", classification_report(y_test, y_predict, target_names=news.target_names))
预测的文章类别为:[ 2 10 3 ... 15 17 8]准确率为:0.8571731748726655
每个类别的精确率和召回率:
precision recall f1-score support
alt.atheism 0.84 0.84 0.84 173
comp.graphics 0.91 0.76 0.83 268
comp.os.ms-windows.misc 0.85 0.82 0.83 250
comp.sys.ibm.pc.hardware 0.70 0.85 0.77 232
comp.sys.mac.hardware 0.96 0.82 0.88 258
comp.windows.x 0.92 0.87 0.89 235
misc.forsale 0.91 0.69 0.78 229
rec.autos 0.93 0.91 0.92 266
rec.motorcycles 0.97 0.94 0.95 266
rec.sport.baseball 0.96 0.94 0.95 262
rec.sport.hockey 0.92 0.97 0.94 257
sci.crypt 0.77 0.99 0.86 245
sci.electronics 0.85 0.83 0.84 231
sci.med 0.96 0.88 0.92 247
sci.space 0.87 0.96 0.91 237
soc.religion.christian 0.60 0.99 0.75 255
talk.politics.guns 0.77 0.96 0.85 233
talk.politics.mideast 0.95 0.98 0.96 233
talk.politics.misc 0.99 0.66 0.79 171
talk.religion.misc 0.97 0.19 0.32 164
accuracy 0.86 4712
macro avg 0.88 0.84 0.84 4712
weighted avg 0.88 0.86 0.85 4712
总结
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快。
缺点:
需要知道先验概率,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
以上是关于朴素贝叶斯及案例实现的主要内容,如果未能解决你的问题,请参考以下文章
贝叶斯朴素贝叶斯及调用spark官网 mllib NavieBayes示例