机器学习中分类算法之朴素贝叶斯分类
Posted 学海拾贝之统计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中分类算法之朴素贝叶斯分类相关的知识,希望对你有一定的参考价值。
正是图中这个伟人,18世纪数学家托马斯.贝叶斯发明了用于描述事件的概率以及如何根据附加信息修正概率的基本数学原理,即贝叶斯方法。学习本期内容你可能要先具备一些基本的概率统计知识,鉴于篇幅,不再从概率、独立事件、相关事件这些基本概念讲起。
朴素贝叶斯(Naïve Bayes,NB)算法是应用贝叶斯定理进行分类的一个简单应用,尽管这不是唯一应用贝叶斯方法的机器学习方法,但它是最常见的。有研究者称,在分类学习任务中,朴素贝叶斯算法功能强大,应排在候选算法的第一位。
那么,如何基于贝叶斯定理,根据已知事件的发生概率推导出相关事件发生的条件概率?举个例子!假设你的任务是估算来体检的人乙肝表面抗原阳性的概率,在没有任何附加证据的条件下,最合理的猜测就是既往研究中体检人群的HBsAg阳检率,如6/100,这个估计称为先验概率。现在,假设你获得了一条额外的证据,你被告知该名体检者有乙肝家族史,在体检人群HBsAg阳性者中有乙肝家族史的概率,如3/7,称为似然概率(likelihood),而普通体检人群具有乙肝家族史的概率,如4/100,称为边际似然概率(marginal likelihood),下面的公式就是应用贝叶斯定理基于已知的额外证据推算后验概率(posterior):
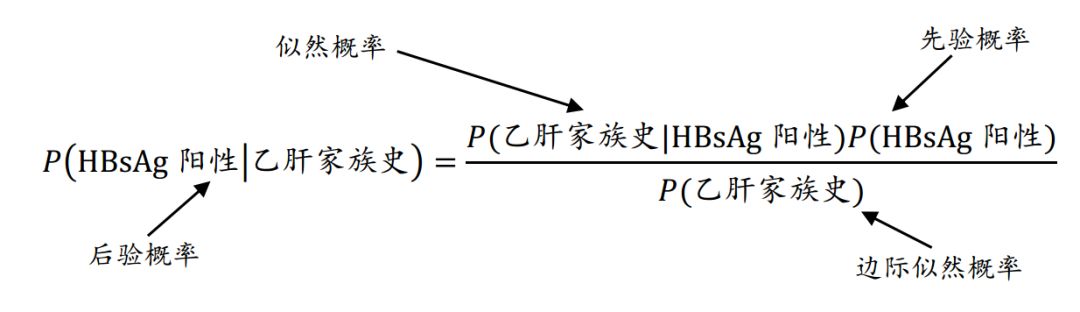
估算得后验概率为(3/7)*(6/100)/(4/100)=64.3%,大于50%,则该体检者更可能是HBsAg阳性。现实中,我们可能通过询问查体等,知道该体检者更多的信息,这个时候则是根据一系列 “先验”信息来推断其HBsAg阳性与否,即推断:

那么,为什么命名为“朴素”的呢?因为朴素贝叶斯假设数据集所有的特征都具有相同的重要性(即不同先验信息对于后验概率的推测贡献一样)和类条件独立性(即事件在相同类取值的条件下彼此间相互独立),这两个假设在大多数实际应用中是鲜有成立的,但这使得计算后验概率的公式大大简化,无需考虑复杂的交叉事件的概率。对于类条件独立性,举个例子可能有助于理解,在似然概率的求解中,该假设使得:
据小编仅有的经验,TAN扩展树朴素贝叶斯网络学习算法可考虑特征之间不完全独立的情况,但相较于NB应该需要更大的训练集来建模。事实证明,尽管这些假设被违背,甚至特征之间具有很强的依赖性时NB的表现仍然较好。
目前,贝叶斯分类器主要用于以下几个方面:
n 文本分类,比如垃圾邮件过滤、作者识别和主题分类等;
n 在计算机网络中进行入侵检测或者异常检测;
n 根据一组观察到的症状,诊断身体状况。
作为医学统计学人,更多地关注于该方法在第三类情形中的应用。需要注意的是,NB是基于学习特征数据的频率表,而数值型特征没有类别值,则需要根据经验或者分位数事先将其离散化,这将损失原始信息量,可以认为这是NB的一个不足之处。
实例演练
数据来自1000名体检者的人口学信息及血常规、尿常规等检查值,数值型变量已依据医学参考值范围划为分类变量(正常,异常低,异常高),共18个特征,并有一列标注HBsAg血清检测结果(阴性,阳性)。
#设置工作目录
setwd("D:\\学海拾贝之统计\\数据源")
#读取数据
data=read.csv("NB.csv")
#将各特征转化为因子形式
for (i in 1:ncol(data)){data[,i]=as.factor(data[,i])}
#选取前800行案例作为训练集,后200例作为测试集,实际操作应随机选取
train=data [1:800, ]
test=data [801:1000, ]
#训练模型并预测
library(e1071)
m=naiveBayes(train[,1:18],train$HBsAg)
p=predict(m,test[,1:18],type="class")
library(gmodels)
CrossTable(p,test$HBsAg,prop.chisq = F,prop.t =F,dnn=("predicted","actual"))
结果如下:
准确度达175/200*100%=87.5%,我们几乎没做什么工作的情况下具有这种水平的表现可以说是相当好了,后期模型性能的提升可以通过拉普拉斯估计或者改良数值型变量的分类来探索,这里不再延伸。
参考文献: BrettLantz, 兰兹, 李洪成,等. 机器学习与R语言[M]. 机械工业出版社, 2015.
以上是关于机器学习中分类算法之朴素贝叶斯分类的主要内容,如果未能解决你的问题,请参考以下文章