逻辑回归 vs 朴素贝叶斯
Posted 量信投资
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归 vs 朴素贝叶斯相关的知识,希望对你有一定的参考价值。
1
引言
上期的量化核武研究专题介绍了。趁热打铁,本期再来聊聊它。特别的,我们把朴素贝叶斯大类中的高斯朴素贝叶斯和逻辑回归比较比较。一文简单介绍了逻辑回归的原理(并且用中证 500 的成分股进行了一个非常简单的实证)。
逻辑回归 vs 高斯朴素贝叶斯,这其实代表这两类模型的 PK。逻辑回归是判别模型(discriminative model)的代表,而朴素贝叶斯是生成模型(generative model)的代表。更有意思的是,通过一定的数学推导可以看出,高斯朴素贝叶斯在求解 P(Y|X) —— 其中 X 为 n 维特征向量、Y 为类别标识 —— 时具有和逻辑回归一样的数学表达式(当然仅仅是解析表达式一致,而它们背后对模型参数的求解方法完全不同)。
下文首先简要回顾一下逻辑回归,其次会推导高斯朴素贝叶斯的表达式。之后,通过对比这二者来解释判别模型和生成模型的区别。从评价一个分类器在样本外准确性的 generalization error 来说,判别模型和生成模型各有千秋。虽然学术界和业界普遍认为判别模型的精度更高,但 Ng and Jordan (2002) 通过理论和实证表明,在训练集样本数量很少的情况下,生成模型的效果往往优于判别模型。
2
逻辑回归
本节以二元分类为例简要介绍逻辑回归。
在二元逻辑回归中,每个样本点都属于 0 或者 1 这两类中的某一类。回归模型根据样本点的特征计算该样本点属于每一类的条件概率,即 P(Y|X)。与朴素贝叶斯不同,逻辑回归直接对 P(Y|X) 建模求解,而不需要先求出 P(X|Y) 和 P(Y)、再应用贝叶斯定理。
在求解 P(Y|X) 时,逻辑回归假定了如下的参数化形式:
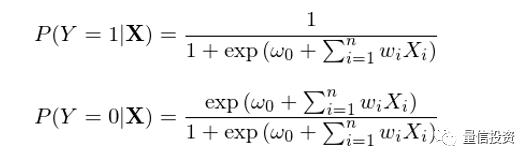
其中,函数 h(z) ≡ 1 / (1 + exp(-z)) 被称为逻辑函数(logistic function)或 sigmoid 函数(因为 h(z) 形如 S 曲线);它的取值范围在 0 和 1 之间。逻辑回归的目的是通过训练集数据找到最优的参数 w 使得分类结果尽量同时满足如下目标:
当一个样本点的真实分类是 1 时,P(Y=1|X) 尽可能大;
当一个样本点的真实分类是 0 时,P(Y=0|X) 尽可能大。
在样本外分类时,逻辑回归将新样本点的特征向量 X 按照 w 进行线性组合得到标量 z,再将 z 放入逻辑函数 h(z) 最终求出该样本点属于类别 1 以及 0 的概率,如果 P(Y=1|X) > P(Y=0|X),则该样本点被分为类别 1,反之为类别 0。
在决定最优参数 w 时,一个合理的目标是在训练模型时最大化条件似然性。假设训练集共有 m 对儿样本 {(X_i, Y_i), i = 1, 2, …, m},则最优的 w* 应满足:
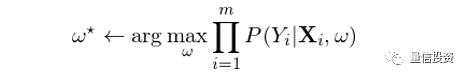
两边取对数(目的是将右侧求积变成求和)、利用 Y_i 仅能取 0 或者 1 这个事实、并将 P(Y|X) 写成逻辑回归的逻辑函数,就可以得到求解 w 时的目标函数 f(w):
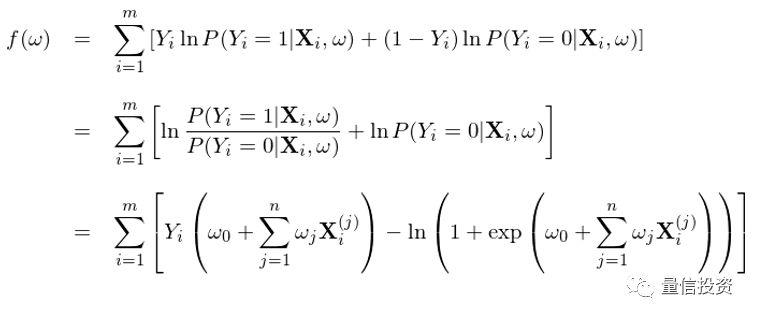
其中 X_i^(j) 为第 i 个样本的第 j 个特征的取值。该目标函数同时考虑了 1 和 0 两类分类的准确性。使用训练集对该模型训练,找到最优的 w*,使得该目标函数 f(w*) 最大,这就是逻辑回归模型的学习过程。最优化 f(w) 可以采用梯度上升(gradient ascent),为此只需要计算出 f 的梯度 ∇f(w)。由于 f(w) 是 w 的凹函数,该方法一定能保证找到全局最优解。
3
高斯朴素贝叶斯分类器
朴素贝叶斯分类器是一类分类器的总称,它们均利用了贝叶斯定理并假设特征之间的条件独立性(详见)。高斯朴素贝叶斯(Gaussian Naïve Bayes,GNB)分类器是其中常见的一种。考虑满足如下假设的 GNB:
1. Y 是二元的,取值 0 或者 1,P(Y) 满足 Bernoulli 分布:P(Y=1) = π,P(Y=0) = 1 - π;
2. X = {X_1, X_2, …, X_n} 为 n 维特征向量,每个 X_i 是一个连续随机变量;
3. P(X_i|Y=y_k) 满足正态分布 N(μ_ik, σ_i),注意我们假设 σ_i 与类别 k 无关;
4. 特征之间满足条件独立性。
与逻辑回归直接对 P(Y|X) 建模不同,高斯朴素贝叶斯对 P(X|Y) 和 P(Y) 建模,然后利用贝叶斯定理反推 P(Y|X)。以 Y = 1 为例有:
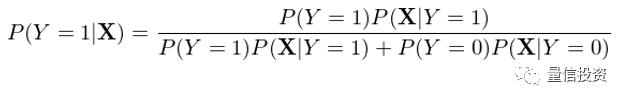
在上式右侧的分母中,我们将 P(X) 使用全概率公式(law of total probability)写成了分解的形式,这是为了下面进一步的推导。将上式右侧分子分母同时除以分子,并利用经典的 exp 和 ln 配对变化可得:
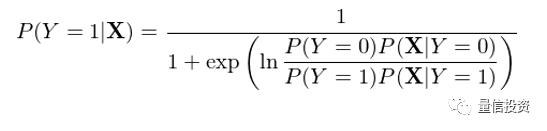
通过特征之间的条件独立性(即“朴素”),上式可以进一步变化得到:
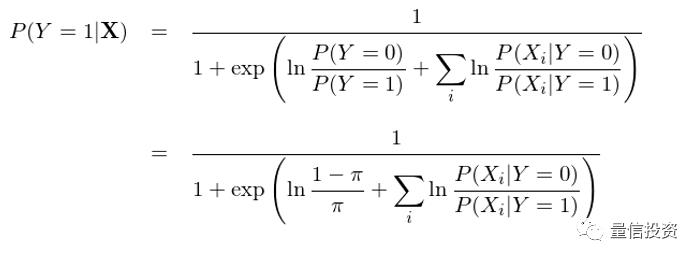
现在,P(Y=1|X) 的表达式已经看着和逻辑回归的表达式类似了,当然还有一些差异,这个差异就是分母上的那一坨求和项是概率的形式而不是 X_i 的线性组合的形式。好消息是利用条件正态分布的分布函数,这一坨求和可以轻松的转变成 X_i 的线性组合(推导略):
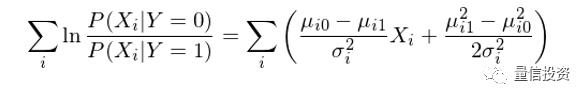
将变换后的求和项带入到 P(Y=1|X) 的表达式中,终于我们得到了想要的结果:
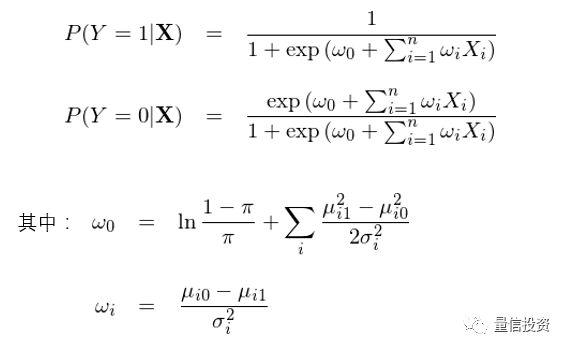
我们看到,通过上面这一大串数学变换,高斯朴素贝叶斯下的 P(Y=1|X) 和 P(Y=0|X) 的解析式和逻辑回归完全一致。
但是,千万不要误解,虽然表达式一致,这二者求解最优参数向量 w 的逻辑却不同。在逻辑回归中,通过最大化目标函数 f(w) 直接求解最优的参数 w;而在 GNB 中,w 的形式是给定的,它由条件正态分布的均值和方差决定,而训练集的作用是估计这些均值和方差,而非直接估计 w。这事实上引出了判别模型和生成模型的区别。
4
判别模型 vs 生成模型
在逻辑回归中,我们根据样本数据直接估计 P(Y|X)。利用给定的函数形式 —— 这里指的是逻辑函数 1 / (1 + exp(-z)) —— 找到最优的参数 w。而在高斯朴素贝叶斯中,我们有点“多此一举”:首先估计 P(X|Y) 和 P(Y),然后再利用贝叶斯定理反推 P(Y|X)。换句话说,虽然再这两种方法中,P(Y|X) 的解析式一样,但是朴素贝叶斯无疑比逻辑回归多了中间一层,而且这层还使用了一个非常强的假设 —— 特征间的条件独立性。因此,从直觉上来说,朴素贝叶斯确实“多此一举”,我们倾向于认为它的分类效果不如纯粹针对 P(Y|X) 建模的逻辑回归。
先别急着下结论。
在朴素贝叶斯中,对 P(X|Y) 和 P(Y) 进行估计实际上是计算 X 和 Y 的联合概率分布 P(X, Y)。有了这个联合分布,我们就可以用它生成(generate)新的数据,解决更广泛数据挖掘问题(当然就包括了推导出 P(Y|X)),特别是无监督学习问题。这就是为什么这一类模型称为生成模型(generative)。它对特征空间 X 和类别 Y 的联合分类建模,从而利用 P(X, Y) 发现 X 和 Y 之间更复杂的关系。典型的生成模型包括朴素贝叶斯、隐马尔可夫等。
而在逻辑回归(以及其他判别模型)中,我们仅仅关心条件概率 P(Y|X),即在给定样本点特征下 Y 的条件概率是什么样,而非 P(X, Y)。因此它也就无法回答任何需要利用 P(X, Y) 来计算的问题。但是在分类和回归这些通常不需要联合分布 P(X, Y) 的领域,判别模型往往会取得更好的效果。大多数判别模型都是解决有监督学习的问题,难以支持无监督学习。常见的判别模型包括逻辑回归、支持向量机、随机森林等。
下面两幅示意图很好的说明了判别模型和生成模型的区别和联系。假设红色和蓝色圆点表示属于不同两类的训练集样本。判别模型的目标是找到一个最能够区分它们的边界,而不在乎每一类中的样本点是如何分布的;而生成模型首先对各类中样本的分布建模,即求解 P(X|Y)。
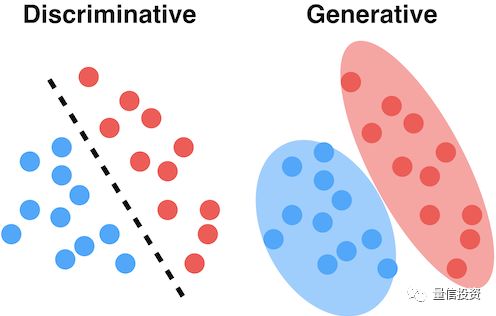
有了 P(X|Y) 以及 P(Y),生成模型利用贝叶斯定理,反推出 P(Y|X),从而找到分类的边界,正如下图中的绿色虚线。为了得到这个分类边界,首先是求出了不同两类的分布 P(X|Y),如图中的绿色实线和绿色空心线所示。反观判别模型,它更直接、更纯粹;直接根据样本数据找到一条分类边界,如图中的红色实线所示。
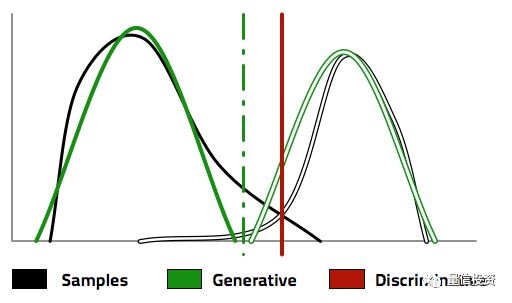
再回到本文的对象 —— 高斯朴素贝叶斯和逻辑回归。可以证明,当特征之间确实满足条件独立性时,随着训练集样本个数的增多,在极限情况下,高斯朴素贝叶斯和逻辑回归求出的最优参数 w 是一致的。然而,当这个假设不成立时,朴素贝叶斯的这个假设就会对分类的准确性造成负面的影响。而逻辑回归的最大化条件似然性求解则可以根据数据中非独立性来调节最优参数 w。从这个角度来说,逻辑回归优于(高斯)朴素贝叶斯也就不足为奇。
关于判别模型和生成模型的比较,著名的人工智能专家 Andrew Ng(吴恩达)和比吴还要著名的 Michael I. Jordan(也叫乔丹,但不是打篮球的那位,那个是 Michael J. Jordan)写过一篇影响深远的文章(Ng and Jordan 2002)。该文以逻辑回归和朴素贝叶斯为例对比了这两种模型,并指出:
1. 两种模型的收敛速度不同:逻辑回归的收敛速度是 O(n);而朴素贝叶斯的收敛速度是 O(logn)。
2. 在极限情况下(即当二者都收敛后),逻辑回归的误差小于朴素贝叶斯的误差。
这两点说明,随着训练集样本数目的变化,逻辑回归和朴素贝叶斯之间的孰优孰劣会发生改变。当训练集很小时(在很多问题中,训练集数据非常稀缺),朴素贝叶斯因为收敛的较快,它在样本外的分类精度会高于逻辑回归;而随着训练集样本数的增多,由于逻辑回归的极限误差更小,因此它最终会战胜朴素贝叶斯,取得更高的分类精度。
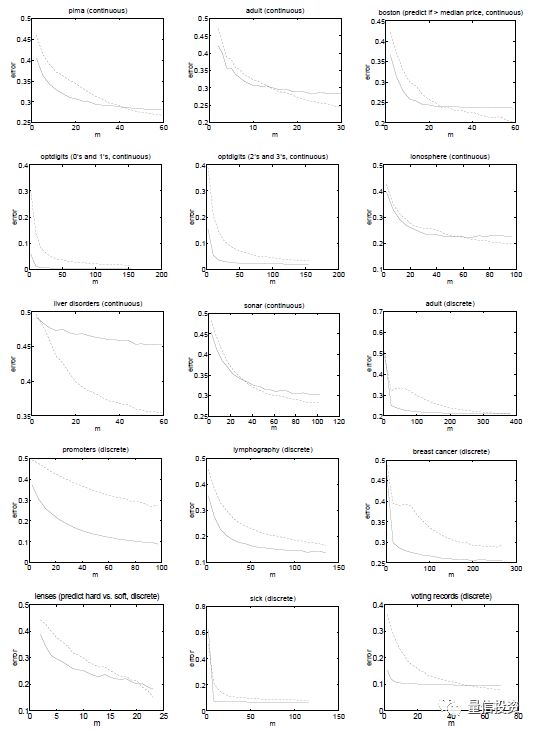
Ng and Jordan 2002 使用 15 个公开数据集对上述结论进行了验证。下面每一幅图代表了一个实验,其横坐标是训练集样本个数,纵坐标为样本外的分类误差;虚线表示逻辑回归的结果、实线表示朴素贝叶斯的结果。从大部分实验中可以观察到,当训练集样本数较少时,实线处于虚线下方,说明朴素贝叶斯优于逻辑回归(它的极限误差虽然高,但是它收敛的更快);而随着样本个数的增加,虚线最终会下穿实线,意味着逻辑回归最终战胜了朴素贝叶斯。
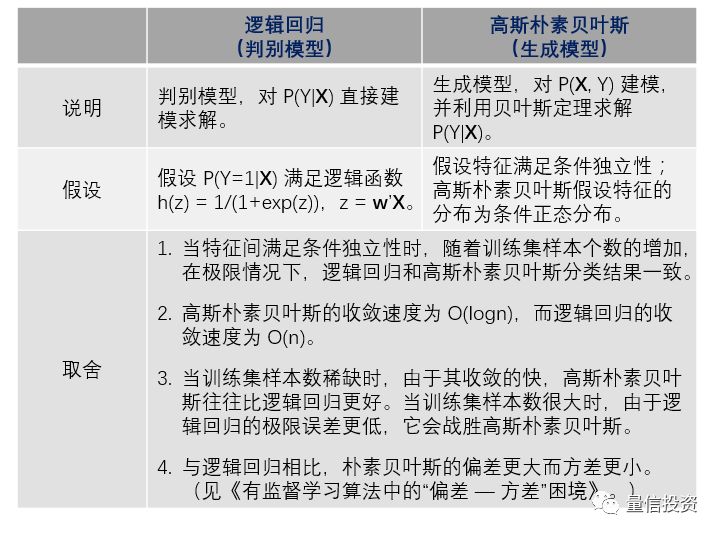
最后,我们把逻辑回归和朴素贝叶斯的区别汇总于下表。
5
结语
判别模型和生成模型各有千秋。对于判别模型,由于参数个数较少,所需的样本个数也要少一些。但是生成模型可以让我们回答更复杂的问题,更深入的挖掘 X 和 Y 之间的关系。
“纸上得来终觉浅,绝知此事要躬行”。为了比较高斯朴素贝叶斯和逻辑回归在选股上的效果,我们将在接下来用中证 500 的成分股做一些简单的实证,并把结果汇总于今后的文章中。
最后,下面这张图来自麻省理工学院的数据发掘课(不过要注意是 2003 年的)。它从不同的维度比较了一些常见的数据挖掘算法,这其中也包括今天的主角逻辑回归和朴素贝叶斯。这些结果是针对大数据集的,但仍然可以作为一个选择的参考,不过也仅仅是个参考。在实际问题中,只有充分了解了待分析的数据,才有可能选择最适当的模型。
参考文献
Ng, A. Y. and M. I. Jordan (2002). On Discriminative vs. Generative Classifiers: A comparison of logistic regression and naive Bayes. In T. G. Dietterich, S. Becker and Z. Ghahramani (Eds), Advances in Neural Information Processing Systems, Vol. 14, MIT Press, 841 – 848.
以上是关于逻辑回归 vs 朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章