十三:朴素贝叶斯算法之检测webshell
Posted 司塔科信息安全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十三:朴素贝叶斯算法之检测webshell相关的知识,希望对你有一定的参考价值。
一:基于WebShell的文本特征进行WebShell的检测
我们基于WebShell的文本特征进行WebShell的检测。我们将互联网上搜集到的WebShell作为黑样本,当前最新的wordpress源码作为白样
本。将一个php文件作为一个字符串处理,以基于单词的2-gram切割,遍历全部文件形成基于2-gram的词汇表,如下图所示。然后,进一步
将每个PHP文件向量化。
1.数据搜集和数据清洗
定义函数,用于将PHP文件转换成一个字符串:
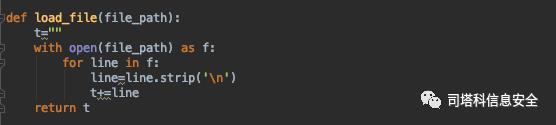
遍历样本集合,将全部PHP文件以字符串的形式加载:
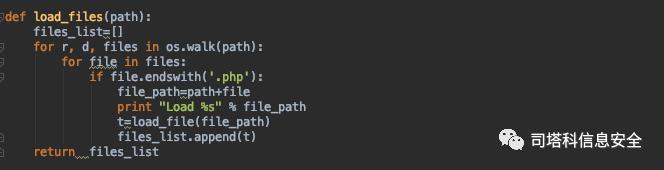
针对黑样本集合,以2-gram算法生成全局的词汇表,其中2-gram基
于单词切割,所以设置token的切割方法为:r'\b\w+\b’。

其中,需要特别说明以下3个参数。
·ngram_range:设置成(2,2),表明基于2-gram;
·decode_error:设置成ignore,表明忽略异常字符的影响;
·token_pattern:设置成r'\b\w+\b',表明按照单词切割。
2.特征化
使用黑样本生成的词汇表vocabulary,将白样本特征化,其中非常重要的是设置CountVectorizer函数的vocabulary,这样才能以黑样本生成
的词汇表来进行向量化:

3.训练样本
创建NB实例:

4.效果验证
我们使用三折交叉验证,所谓k折交叉验证,就是将数据集a分为训练集b和测试集c,在样本量不充足的情况下,为了充分利用数据集对算
法效果进行测试,将数据集a随机分为k个包,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练:

完整代码为:
import os
from sklearn.feature_extraction.text import CountVectorizer
import sys
import numpy as np
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
def load_file(file_path):
t=""
with open(file_path) as f:
for line in f:
line=line.strip('\n')
t+=line
return t
def load_files(path):
files_list=[]
for r, d, files in os.walk(path):
for file in files:
if file.endswith('.php'):
file_path=path+file
print "Load %s" % file_path
t=load_file(file_path)
files_list.append(t)
return files_list
if __name__ == '__main__':
#bigram_vectorizer = CountVectorizer(ngram_range=(2, 2),token_pattern = r'\b\w+\b', min_df = 1)
webshell_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern = r'\b\w+\b',min_df=1)
webshell_files_list=load_files("../data/PHP-WEBSHELL/xiaoma/")
x1=webshell_bigram_vectorizer.fit_transform(webshell_files_list).toarray()
y1=[1]*len(x1)
vocabulary=webshell_bigram_vectorizer.vocabulary_
wp_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern = r'\b\w+\b',min_df=1,vocabulary=vocabulary)
wp_files_list=load_files("../data/wordpress/")
x2=wp_bigram_vectorizer.fit_transform(wp_files_list).toarray()
y2=[0]*len(x2)
x=np.concatenate((x1,x2))
y=np.concatenate((y1, y2))
clf = GaussianNB()
print cross_validation.cross_val_score(clf, x, y, n_jobs=-1,cv=3)
二:针对函数调用建立特征
WebShell本质上就是一个远程管理工具,只不过被黑客利用了。一系列管理功能本质上是一系列函数调用,于是我们尝试针对函数调用建
立特征
1.数据搜集和数据清洗
针对黑样本集合,以1-gram算法生成全局的词汇表,其中1-gram基于函数和字符串常量进行切割,所以设置token的切割方法为:r'\b\w+\b\
(|\'\w+\’'。

2.特征化
使用黑样本生成的词汇表vocabulary,将白样本特征化:

3.训练样本
创建NB实例:
4.效果验证
我们继续使用三折交叉验证:
完整代码为:
import os
from sklearn.feature_extraction.text import CountVectorizer
import sys
import numpy as np
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
r_token_pattern=r'\b\w+\b\(|\'\w+\''
def load_file(file_path):
t=""
with open(file_path) as f:
for line in f:
line=line.strip('\n')
t+=line
return t
def load_files(path):
files_list=[]
for r, d, files in os.walk(path):
for file in files:
if file.endswith('.php'):
file_path=path+file
#print "Load %s" % file_path
t=load_file(file_path)
files_list.append(t)
return files_list
if __name__ == '__main__':
#bigram_vectorizer = CountVectorizer(ngram_range=(2, 2),token_pattern = r'\b\w+\b', min_df = 1)
webshell_bigram_vectorizer = CountVectorizer(ngram_range=(1, 1), decode_error="ignore",
token_pattern = r_token_pattern,min_df=1)
webshell_files_list=load_files("../data/PHP-WEBSHELL/xiaoma/")
x1=webshell_bigram_vectorizer.fit_transform(webshell_files_list).toarray()
y1=[1]*len(x1)
vocabulary=webshell_bigram_vectorizer.vocabulary_
wp_bigram_vectorizer = CountVectorizer(ngram_range=(1, 1), decode_error="ignore",
token_pattern = r_token_pattern,min_df=1,vocabulary=vocabulary)
wp_files_list=load_files("../data/wordpress/")
x2=wp_bigram_vectorizer.transform(wp_files_list).toarray()
#print x2
y2=[0]*len(x2)
x=np.concatenate((x1,x2))
y=np.concatenate((y1, y2))
clf = GaussianNB()
print vocabulary
print cross_validation.cross_val_score(clf, x, y, n_jobs=-1,cv=3)
以上是关于十三:朴素贝叶斯算法之检测webshell的主要内容,如果未能解决你的问题,请参考以下文章