十四:朴素贝叶斯算法之检测DGA域名&检测针对Apache的DDoS攻击
Posted 司塔科信息安全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十四:朴素贝叶斯算法之检测DGA域名&检测针对Apache的DDoS攻击相关的知识,希望对你有一定的参考价值。
一:检测DGA域名
域名生成算法(Domain Generation Algorithm,DGA)是一项古老但一直活跃的技术,是中心结构僵尸网络赖以生存的关键武器,该技术给打击和关闭该类型僵尸网络造成了不小的麻烦。研究人员需要快速掌握域名生成算法和输入,以便对生成的域名及时进行处置。我们尝试使
用NB算法来区分正常域名以及DGA域名.
1.数据搜集和数据清洗
加载alexa前1000的域名作为白样本,标记为0;分别加载
cryptolocker和post-tovar-goz家族的DGA域名,分别标记为2和3:
2.特征化
以2-gram处理DGA域名,如图所示。

以2-gram分隔域名,切割单元为字符,以整个数据集合的2-gram结
果作为词汇表并进行映射,得到特征化的向量:

3.训练样本
实例化NB算法:

4.效果验证
我们继续使用三折交叉验证:

完成代码为:
# -*- coding:utf-8 -*-
import sys
import urllib
import urlparse
import re
from hmmlearn import hmm
import numpy as np
from sklearn.externals import joblib
import htmlParser
import nltk
import csv
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn.naive_bayes import GaussianNB
#处理域名的最小长度
MIN_LEN=10
#状态个数
N=8
#最大似然概率阈值
T=-50
#模型文件名
FILE_MODEL="9-2.m"
def load_alexa(filename):
domain_list=[]
csv_reader = csv.reader(open(filename))
for row in csv_reader:
domain=row[1]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
def domain2ver(domain):
ver=[]
for i in range(0,len(domain)):
ver.append([ord(domain[i])])
return ver
def train_hmm(domain_list):
X = [[0]]
X_lens = [1]
for domain in domain_list:
ver=domain2ver(domain)
np_ver = np.array(ver)
X=np.concatenate([X,np_ver])
X_lens.append(len(np_ver))
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, FILE_MODEL)
return remodel
def load_dga(filename):
domain_list=[]
#xsxqeadsbgvpdke.co.uk,Domain used by Cryptolocker - Flashback DGA for 13 Apr 2017,2017-04-13,
# http://osint.bambenekconsulting.com/manual/cl.txt
with open(filename) as f:
for line in f:
domain=line.split(",")[0]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
def test_dga(remodel,filename):
x=[]
y=[]
dga_cryptolocke_list = load_dga(filename)
for domain in dga_cryptolocke_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x,y
def test_alexa(remodel,filename):
x=[]
y=[]
alexa_list = load_alexa(filename)
for domain in alexa_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x, y
def show_hmm():
domain_list = load_alexa("../data/top-1000.csv")
if not os.path.exists(FILE_MODEL):
remodel=train_hmm(domain_list)
remodel=joblib.load(FILE_MODEL)
x_3,y_3=test_dga(remodel, "../data/dga-post-tovar-goz-1000.txt")
x_2,y_2=test_dga(remodel,"../data/dga-cryptolocke-1000.txt")
x_1,y_1=test_alexa(remodel, "../data/test-top-1000.csv")
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('HMM Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
def get_aeiou(domain_list):
x=[]
y=[]
for domain in domain_list:
x.append(len(domain))
count=len(re.findall(r'[aeiou]',domain.lower()))
count=(0.0+count)/len(domain)
y.append(count)
return x,y
def show_aeiou():
x1_domain_list = load_alexa("../data/top-1000.csv")
x_1,y_1=get_aeiou(x1_domain_list)
x2_domain_list = load_dga("../data/dga-cryptolocke-1000.txt")
x_2,y_2=get_aeiou(x2_domain_list)
x3_domain_list = load_dga("../data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_aeiou(x3_domain_list)
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('AEIOU Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
def get_uniq_char_num(domain_list):
x=[]
y=[]
for domain in domain_list:
x.append(len(domain))
count=len(set(domain))
count=(0.0+count)/len(domain)
y.append(count)
return x,y
def show_uniq_char_num():
x1_domain_list = load_alexa("../data/top-1000.csv")
x_1,y_1=get_uniq_char_num(x1_domain_list)
x2_domain_list = load_dga("../data/dga-cryptolocke-1000.txt")
x_2,y_2=get_uniq_char_num(x2_domain_list)
x3_domain_list = load_dga("../data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_uniq_char_num(x3_domain_list)
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('UNIQ CHAR NUMBER')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='best')
plt.show()
def count2string_jarccard_index(a,b):
x=set(' '+a[0])
y=set(' '+b[0])
for i in range(0,len(a)-1):
x.add(a[i]+a[i+1])
x.add(a[len(a)-1]+' ')
for i in range(0,len(b)-1):
y.add(b[i]+b[i+1])
y.add(b[len(b)-1]+' ')
return (0.0+len(x-y))/len(x|y)
def get_jarccard_index(a_list,b_list):
x=[]
y=[]
for a in a_list:
j=0.0
for b in b_list:
j+=count2string_jarccard_index(a,b)
x.append(len(a))
y.append(j/len(b_list))
return x,y
def show_jarccard_index():
x1_domain_list = load_alexa("../data/top-1000.csv")
x_1,y_1=get_jarccard_index(x1_domain_list,x1_domain_list)
x2_domain_list = load_dga("../data/dga-cryptolocke-1000.txt")
x_2,y_2=get_jarccard_index(x2_domain_list,x1_domain_list)
x3_domain_list = load_dga("../data/dga-post-tovar-goz-1000.txt")
x_3,y_3=get_jarccard_index(x3_domain_list,x1_domain_list)
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('JARCCARD INDEX')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz",marker='o')
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock",marker='v')
ax.scatter(x_1, y_1, color='r', label="alexa",marker='*')
ax.legend(loc='lower right')
plt.show()
def nb_dga():
x1_domain_list = load_alexa("../data/top-1000.csv")
x2_domain_list = load_dga("../data/dga-cryptolocke-1000.txt")
x3_domain_list = load_dga("../data/dga-post-tovar-goz-1000.txt")
x_domain_list=np.concatenate((x1_domain_list, x2_domain_list,x3_domain_list))
y1=[0]*len(x1_domain_list)
y2=[1]*len(x2_domain_list)
y3=[2]*len(x3_domain_list)
y=np.concatenate((y1, y2,y3))
cv = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern=r"w", min_df=1)
x= cv.fit_transform(x_domain_list).toarray()
clf = GaussianNB()
print cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=3)
if __name__ == '__main__':
nb_dga()
二 :检测针对Apache的DDoS攻击
DDoS攻击通常会使企业的互联网业务造成巨大损失——业务中断几个小时甚至几天。这次我们基于KDD 99的样本数据,尝试使用NB算
法识别针对Apache的DDoS攻击(见图)
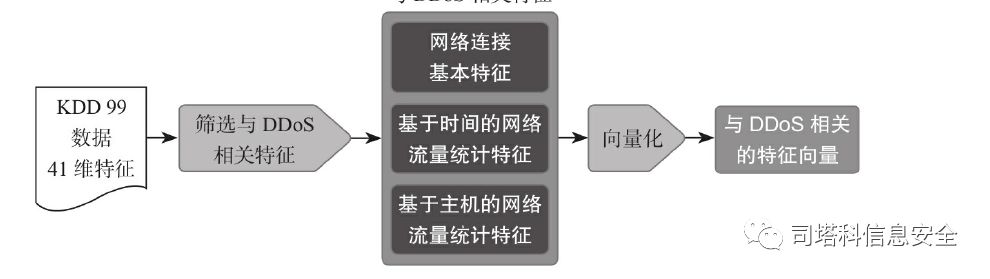
1.数据搜集和数据清洗
KDD 99数据已经完成了大部分的数据清洗工作,KDD99数据集中每个连接用41个特征来描述:

加载KDD 99数据集中的数据:

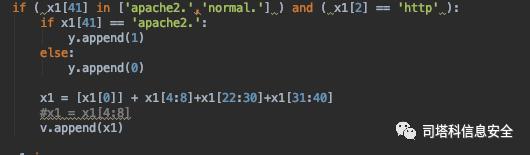
筛选标记为apache2和normal且是http协议的数据:
2.特征化
挑选与DDoS相关的特征作为样本特征:

3.训练样本
实例化NB算法:
4.效果验证
我们使用十折交叉验证:
完整代码:
# -*- coding:utf-8 -*-
import re
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn.naive_bayes import GaussianNB
def load_kdd99(filename):
x=[]
with open(filename) as f:
for line in f:
line=line.strip(' ')
line=line.split(',')
x.append(line)
return x
def get_apache2andNormal(x):
v=[]
w=[]
y=[]
for x1 in x:
if ( x1[41] in ['apache2.','normal.'] ) and ( x1[2] == 'http' ):
if x1[41] == 'apache2.':
y.append(1)
else:
y.append(0)
x1 = [x1[0]] + x1[4:8]+x1[22:30]+x1[31:40]
#x1 = x1[4:8]
v.append(x1)
for x1 in v :
v1=[]
for x2 in x1:
v1.append(float(x2))
w.append(v1)
return w,y
if __name__ == '__main__':
v=load_kdd99("../data/kddcup99/corrected")
x,y=get_apache2andNormal(v)
clf = GaussianNB()
print cross_validation.cross_val_score(clf, x, y, n_jobs=-1, cv=10)
以上是关于十四:朴素贝叶斯算法之检测DGA域名&检测针对Apache的DDoS攻击的主要内容,如果未能解决你的问题,请参考以下文章