机器学习笔记——朴素贝叶斯构建“饥饿站台”豆瓣短评情感分类器
Posted 奶糖猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记——朴素贝叶斯构建“饥饿站台”豆瓣短评情感分类器相关的知识,希望对你有一定的参考价值。
前文回顾
-
朴素贝叶斯算法的基本原理 -
公式推导贝叶斯准则(条件概率公式) -
构建训练、测试简易文本分类算法 -
拉普拉斯平滑修正
本文背景


文本预处理
#将评分划分成1-5五个等级
def rating(e):
if '50' in e:
return 5
elif '40' in e:
return 4
elif '30' in e:
return 3
elif '20' in e:
return 2
elif '10' in e:
return 1
else:
return 'none'
# 利用map方法依据rating函数创建新一列
data['new_rating'] = data['rating'].map(rating)
# 删去评分为3的短评,判定评分为3的情感持中性
data = data[data['new_rating'] != 3]
#将4、5评分标注成1,视为正面情绪;将1、2评分标注成0,视为负面情绪
data['sentiment'] = data['new_rating'].apply(lambda x: +1 if x > 3 else 0)
# 删去短评中的符号、英文字母
punc = '~`!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}'
def remove_fuhao(e):
return re.sub(r"[%s]+" % punc, " ", e)
def remove_letter(new_short):
return re.sub(r'[a-zA-Z]+', '', new_short)
# 利用jieba切割文本
def cut_word(text):
text = jieba.cut(str(text))
return ' '.join(text)
# 同apply方法依据以上三个自定义函数为依据创建新一列
data['new_short'] = data['short'].apply(remove_fuhao).apply(remove_letter).apply(cut_word)
文末提供中文停用词表获取方式
# 读取停用词表函数
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 将短评中的停用词删去
def sentence_div(text):
# 将短评按空格划分成单词并形成列表
sentence = text.strip().split()
# 加载停用词的路径
stopwords = stopwordslist(r'中文停用词表.txt')
#创建一个空字符串
outstr = ' '
# 遍历短评列表中每个单词
for word in sentence:
if word not in stopwords: # 判断词汇是否在停用词表里
if len(word) > 1: # 单词长度要大于1
if word != '\t': # 单词不能为tab
if word not in outstr: # 去重:如果单词在outstr中则不加入
outstr += ' ' # 分割
outstr += word # 将词汇加入outstr
#返回字符串
return outstr
data['the_short'] = data['new_short'].apply(sentence_div)
data['split'] = data['the_short'].apply(lambda x: 1 if len(x.split()) > 3 else 0)
data = data[~data['split'].isin(['0'])]
# 将需要的两列数据索引出,合并成一个新的DataFrame
new_data1 = data.iloc[:, 3]
new_data2 = data.iloc[:, 5]
new_data = pd.DataFrame({'short': new_data2, 'sentiment': new_data1})
上文提及过一个问题,短评正面情绪所占比例要远大于负面情绪,为了避免测试数据集中的样本全为正面情绪,所以这里采用随机选择的方式划分数据集。利用random库中的sample方法随机选择10%的数据的索引作为测试数据集的索引,剩下的部分作为训练数据集的索引;然后按照两类索引将数据集切割成两部分,并分别保存。
def splitDataSet(new_data):
# 获取数据集中随机的10%作为测试集,获取测试数据集的索引
test_index = random.sample(new_data.index.tolist(), int(len(new_data.index.tolist()) * 0.10))
# 剩下的部分作为训练集,获取训练数据集的索引
train_index = [i for i in new_data.index.tolist() if i not in test_index]
#分别索引出训练集和测试集
test_data = new_data.iloc[test_index]
train_data = new_data.iloc[train_index]
# 分别保存为csv文件
train_data.to_csv('bayes_train.csv', encoding='utf_8_sig', index=False)
test_data.to_csv('bayes_test.csv', encoding='utf_8_sig', index=False)
构建分类器
构建词向量
def loadDataSet(filename):
data = pd.read_csv(filename)
postingList = []
#文本语句切分
for sentence in data['short']:
word = sentence.strip().split()# split方法返回一个列表
postingList.append(word)# 将每个词汇列表添至一个列表中
#类别标签的向量
classVec = data['sentiment'].values.tolist()
return postingList,classVec
#创建词汇表
def createVocabList(dataSet):
#创建一个空的不重复列表
vocabSet = set([])
for document in dataSet:
#取两者并集
vocabSet = vocabSet | set(document)
return list(vocabSet)
#词条向量化函数
def setOfWords2Vec(vocabList, inputSet):
#创建一个元素都为0的向量
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
#若词汇表包含该词汇,则将该位置的0变为1
returnVec[vocabList.index(word)] = 1
return returnVec
#词条向量汇总
def getMat(inputSet):
trainMat = []
vocabList = createVocabList(inputSet)
for Set in inputSet:
returnVec = setOfWords2Vec(vocabList,Set)
trainMat.append(returnVec)
return trainMat
训练算法
def trainNB(trainMatrix,trainCategory):
#训练文本数量
numTrainDocs = len(trainMatrix)
#每篇文本的词条数
numWords = len(trainMatrix[0])
#文档属于正面情绪(1)的概率
pAbusive = sum(trainCategory)/float(numTrainDocs)
#创建两个长度为numWords的零数组
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
#分母初始化
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
#统计正面情绪的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
#print(p1Num)
p1Denom += sum(trainMatrix[i])
#print(p1Denom)
else:
#统计负面情绪的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#计算词条出现的概率
p1Vect = np.log(p1Num/p1Denom)
p0Vect = np.log(p0Num/p0Denom)
#print("\n",p0Vect,"\n\n",p1Vect,"\n\n",pAbusive)
return p1Vect,p0Vect,pAbusive
测试算法
def classifyNB(ClassifyVec, p1V,p0V,pAb):
#将对应元素相乘
print(pAb)
p1 = sum(ClassifyVec * p1V) + np.log(pAb)
p0 = sum(ClassifyVec * p0V) + np.log(1.0 - pAb)
print('p1:',p1)
print('p0:',p0)
if p1 > p0:
return 1
else:
return 0
def testNB():
#加载训练集数据
train_postingList,train_classVec = loadDataSet('bayes_train4.csv')
#创建词汇表
vocabSet = createVocabList(train_postingList)
#将训练样本词条向量汇总
trainMat = getMat(train_postingList)
#训练算法
p1V,P0V,PAb = trainNB(trainMat,train_classVec)
#加载测试集数据
test_postingList,test_classVec = loadDataSet('bayes_test4.csv')
# 将测试文本向量化
predict = []
for each_test in test_postingList:
testVec = setOfWords2Vec(vocabSet,each_test)
#判断类别
if classifyNB(testVec,p1V,P0V,PAb):
print(each_test,"正面情绪")
predict.append(1)
else:
print(each_test,"负面情绪")
predict.append(0)
corr = 0.0
for i in range(len(predict)):
if predict[i] == test_classVec[i]:
corr += 1
print("朴素贝叶斯分类器准确率为:" + str(round((corr/len(predict)*100),2)) + "%")
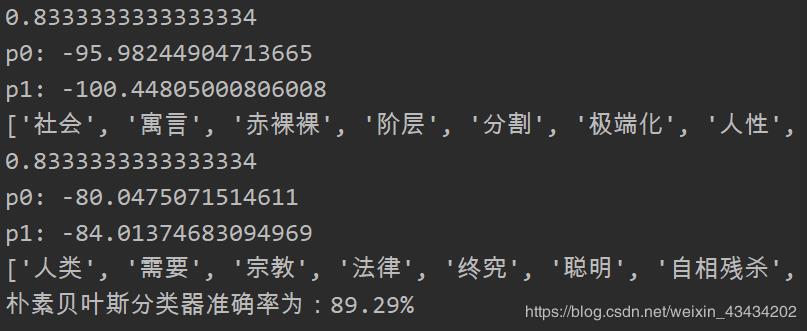
因为我们是利用随机选择的方法划分训练集与测试集,所以每次运行程序,朴素贝叶斯分类器的准确率都会改变,可以多运行几次取其平均值作为该分类器的准确率。最后附上依据该数据集绘制的词云图,不知道这部电影的体裁能不能引起你的兴趣的呢?

总结


看到这点个“在看”吧 谢谢大爷鸭 后台回复“饥饿站台”可获取源码和数据
End
往期推荐:
1.
2.
3.
以上是关于机器学习笔记——朴素贝叶斯构建“饥饿站台”豆瓣短评情感分类器的主要内容,如果未能解决你的问题,请参考以下文章