网络爬虫:你懂搜索引擎是怎么运作的吗?
Posted 雷课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫:你懂搜索引擎是怎么运作的吗?相关的知识,希望对你有一定的参考价值。
搜索引擎
搜索和标识数据库中与用户指定的关键字或字符相对应的项的程序,用于查找万维网上的特定站点。
例如:谷歌搜索引擎,360,百度等。

搜索引擎索引
搜索引擎索引是将关键字与网站相关联的数据库,因此搜索引擎可以显示与用户的搜索查询相匹配的网站。
例如,如果用户搜索猎豹的运行速度,那么软件蜘蛛将在搜索引擎索引中搜索这些术语。
网络爬虫
您首先需要了解的是Web Crawler或Spider是什么以及它是如何工作的。搜索引擎蜘蛛(也被称为爬虫、机器人、搜索机器人或简单的机器人)是大多数搜索引擎用来查找互联网上新事物的程序。谷歌的网络爬虫被称为Googlebot。该程序从一个网站开始,并跟踪每个页面上的每一个超链接。
所以可以说,网络上的所有东西最终都会被发现和爬行,就像所谓的“蜘蛛”从一个网站爬到另一个网站。当网络爬虫访问您的一个页面时,它会将站点的内容加载到数据库中。一旦获取了一个页面,页面的文本就会被加载到搜索引擎的索引中,这是一个海量的单词数据库,它们出现在不同的网页上。
Robots.txt文件
网络爬虫在少数几个未经批准的网站上爬行。因此,每个网站都包含一个robots.txt文件,其中包含蜘蛛(网络爬虫)的指令,在网站的哪些部分要索引,哪些部分要忽略。
PageRank通过计算链接到页面的数量和质量来确定网页的重要程度。当一个网络爬虫通过每个网站,它跟踪网站中的所有链接,并检查有多少链接连接到每个网站。然后利用页面排名算法对每个网页分配百分比,以代表网页的重要性。例如,如果有三个名为A、B和C的网页,那么假设连接到B的链接数来自5个百分比较低的网页,而连接到C的链接的链接来自A,其百分比较高,因为到C的链接来自一个重要的页面,因此C的值高于B。
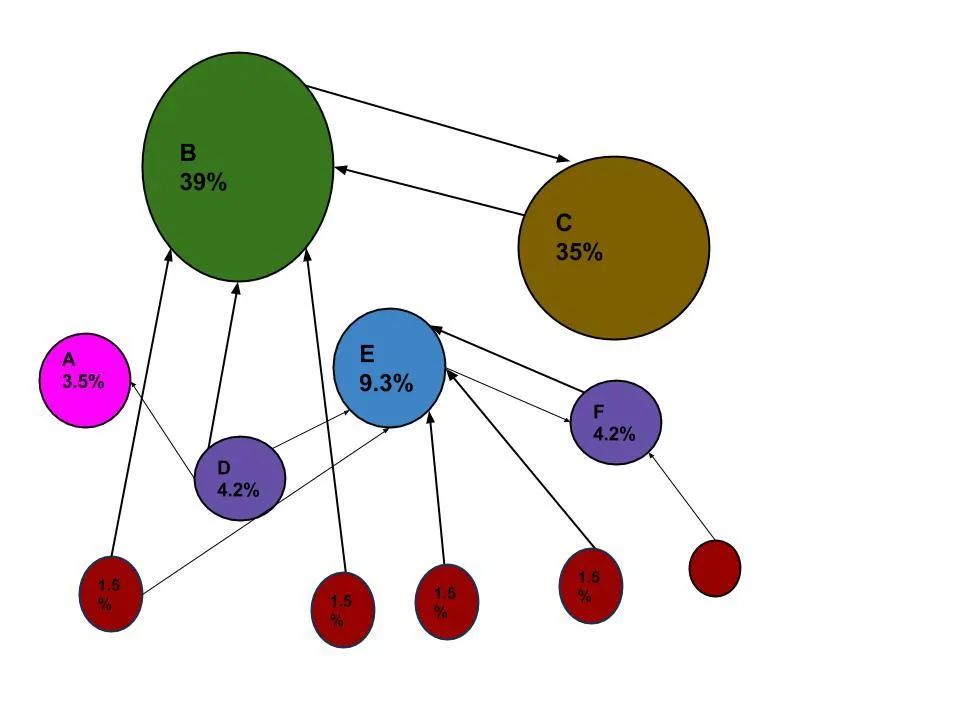
URL图中的PageRank是一种概率分布,用来表示随机点击链接的人到达任何特定页面的可能性。
因此,在网络爬行过程中,基本上有三个步骤。
第一步:搜索机器人从爬行站点的页面开始;
第二步:继续索引网站的单词和内容;
robots.txt”的重要性
当蜘蛛访问你的网站时,它应该做的第一件事就是查找一个名为“robots.txt”的文件。此文件包含关于网站哪些部分要索引和哪些部分要忽略的说明。控制蜘蛛在站点上看到什么的唯一方法是使用robots.txt文件。所有的蜘蛛都应该遵循一些规则,而主要的搜索引擎在大多数情况下都会遵循这些规则。幸运的是,谷歌(Google)和必应(Bing)等主要搜索引擎终于在标准方面展开了合作。
搜索时,蜘蛛搜索索引以查找包含这些搜索词的每一页。在这种情况下,它找到了数百或数千页,Google通过提出200多个这样的问题来决定哪些文档是真正想要的:
这个页面包含这个关键字多少次?
单词是否出现在标题中,URL中,直接相邻?
页面中是否包含这些单词的同义词?
这个网页是一个高质量的网站还是低质量的?
然后使用PageRank算法获取数百个网页,并对这些网页的重要性进行排序,该算法可以查看有多少外部链接指向它,以及这些链接有多重要?最后,它将所有这些因素结合在一起,生成每个页面的总体得分,并在提交搜索后大约半秒钟内将搜索结果发回。
每个页面包括标题、URL、文本片段,以确定我们要寻找的特定页面。如果不相关,它也会在页面底部显示相关搜索。
转载|腾讯内容平台
END

往期精选
关注雷课
学习干货
以上是关于网络爬虫:你懂搜索引擎是怎么运作的吗?的主要内容,如果未能解决你的问题,请参考以下文章