庖丁解牛HashMap源代码解析(多图)
Posted 技术风向标
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了庖丁解牛HashMap源代码解析(多图)相关的知识,希望对你有一定的参考价值。
HashMap, 无需多介绍,几乎每个Java程序员都使用过,并且可以说几乎每天都差不多要与之接触,或直接使用或间接使用,其重要性可见一斑,让我们来看看这个不算注释不超过1000行的代码如何实现那么多神奇的功能。这里假设极客朋友们都非常熟悉HashMap本身用法,同时至少知道HashMap是由数组Bucket再加上链表构成,这样我们下面解牛的时候,至少可以区分大腿与小腿骨头了。:)

按照我们的习惯,由大局观开始俯视整体架构。当然,前提是我们假设所有人都已经非常清楚HashMap本身的用途,当然类的注释不可少。
包结构:
packagejava.util;
部分注释:
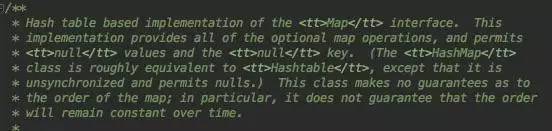
多么清晰直白啊,实现了Map接口;与Hashtable的核心差异是非同步并且支持null K/V; 经典的Java必备面试题有没有!
类结构总览:
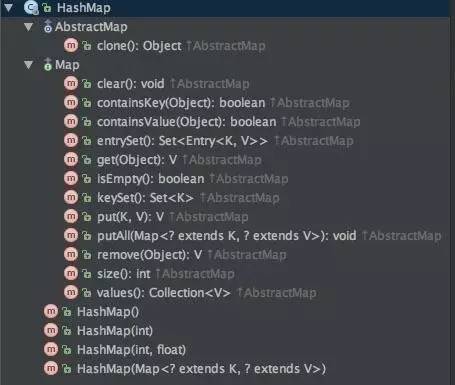
类的总结构比较清晰,继承自AbstractMap, 主要实现了Map接口,以及包含几个构造器。其中核心功能代码都是实现Map接口,包括put/get, entrySet。

作者及类定义:
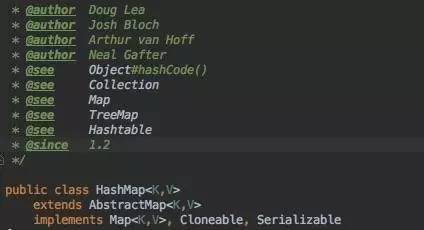
我们看到了熟悉的Doug Lea大教授,大名鼎鼎的Java Concurrent包的作者。
还有大名鼎鼎的Josh Bloch, 我们熟悉的整个Java Collection框架,math包都是打造于其手,可惜后来在Java 1.5 Tiger 2004时,加入了当时如日中天的Google, 并正值当年Google IPO, 想想也不需要可惜,应该说有慧眼,哈哈。
类的定义没有花头,继承AbstractMap, 实现Map, Cloneable, Serializable接口。
代码体:

啊哦,一上来就云里雾里。
// The default initial capacity - MUST be a power of two.
static final intDEFAULT_INITIAL_CAPACITY=1<<4;// aka 16
本来挺清楚,定义了默认HashMap的容量。可怎么一下就来个位运算?并且注释明确说“MUST be a power of two”。
这两个疑问如何解答?
1. 关于位运算
主要来自两个原因,其一当年的大神多来自Unix界,或者黑客家族,不使用一下位运算如何显示其身份?其二,位运算之高效,如下文在本来可以求模运算的时候,也换用位运算提高运算速度。
2. 为何要用2的幂次作为其容量,后文可以看到不单只默认容量?
这个又要源自其黑客之出身,为了追求速度与效率,在下文计算key的bucket的时候把取模运算转换为位运算,而当容量一定是2^n时:
h & (length - 1) 等价与 h % length,但他们是等价(效果)不等效(效率)的,其效果是计算h与length的模,我们下文会出现。
继续:
static final intMAXIMUM_CAPACITY=1<<30;
int 是4个字节存储,去掉其符号位数为31位,再考虑到这里其实是定义HashMap Bukect数组的长度,考虑到Java堆存储空间的限制,定位30位,其大小为1073741824。
值得注意的是,这里的大小是指HashMap Bucket数组的长度,下文会提到,并不是HashMap的总容量,理论上无限,当然实际上受限与内存情况。
负载因子默认常量:
static final floatDEFAULT_LOAD_FACTOR=0.75f;
默认负载因子为0.75,暂时忽略,看下文如何使用再说。
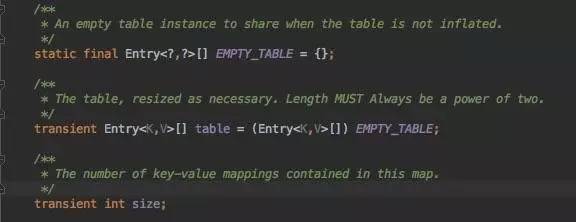
首先定义了以一个空的Entry的二维数组作为默认。接着定义了真正的HashMap底层Bucket数组,Entry table, 这个类下面会提到。注意其修饰符为transient, 什么含义?不要放过这些细节。
Transient:
1.transient 首先是表明该数据不参与序列化。假设HashMap 中的存储数据的数组还有很多的空间没有被使用,没有被使用到的空间被序列化没有意义。所以下文会有手动使用 writeObject() 方法,只序列化实际存储元素的数组。
2. 不同的虚拟机对于相同 hashCode 产生的 Code 值可能是不一样的,如果使用默认序列化,则反序列化后,元素的位置和之前的是保持一致的,可是由于 hashCode 的值不一样了,那么后续看到的定位函数 indexOf()返回的元素下标就会不同,其结果会出差错。
size:
接下来是真正的当前HashMap的已经包含的K/V数据的大小。
我们继续阅读:
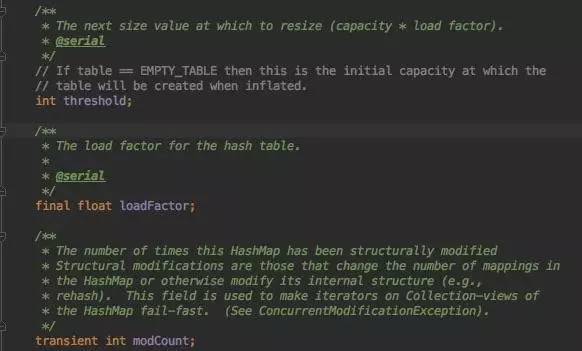
threshold顾名思义,阀值,当到达阀值会触发一些事,我们先记着,下面看到再分析。
loadFactor: 负载因子;
modCount: 注释解释为记录HashMap结构被修改次数,结构修改指改变了K/Vmapping, 如新增,删除一个元素;又或是改变了内部结构,如rehash。这个字段被用来当迭代器的fail-fast。什么意思?
Fail-Fast机制:
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
所以,下次看到HashMap使用中抛出ConcurrentModificationException, 就知道有多线程并发使用了。怎么处理?ConcurrentHashMap。
ALTERNATIVE_HASHING_THRESHOLD_DEFAULT:
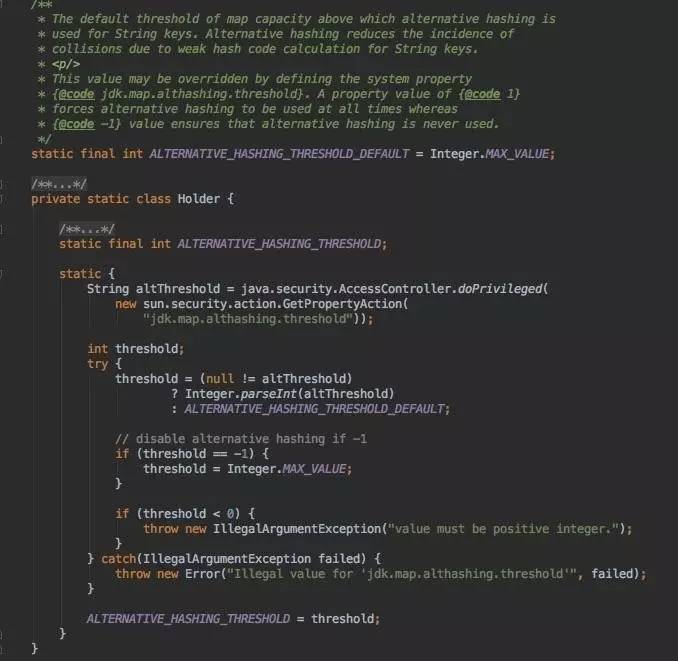
如果没有记错的话,这里是JDK 1.7新添加的,针对与字符串的key,提供一个新的hash算法会提供更好的hashcode分布减少冲突,如果想启用尝鲜这个特性,你需要设置jdk.map.althashing.threshold这个系统属性的值为一个非负数(默认是-1)这个值代表了一个集合大小的threshold,超过这个值,就会使用新的hash算法。需要注意的一点,只有当re-hash的时候,新的hash算法才会起作用。
而Holder本身只是加载获取这个配置参数而已。
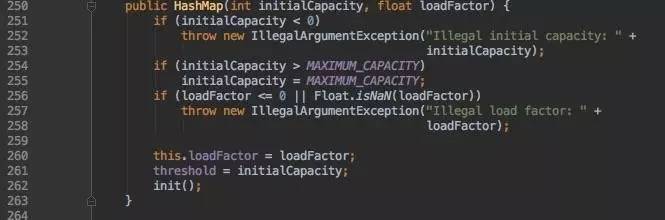
按照容量与负载因子作为参数的构造器。比较简单,没什么花哨。注意的是,这里的initalCapacity还是同上指Bucket及数组的长度, 同时把阀值threshold置成initalCapacity。
其它构造器:
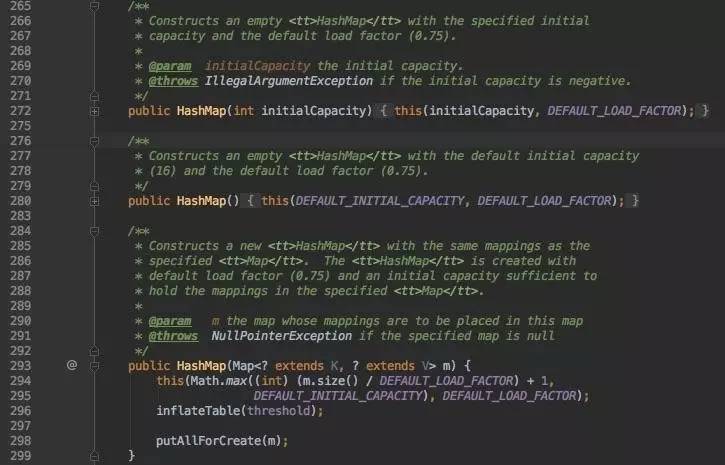
前两个没花头,最后一个需要深入看一下,功能很好理解,从一个已有的Map创建一个新的HashMap。
中间inflateTable是JDK 1.7新加入的,其它无需多讲。
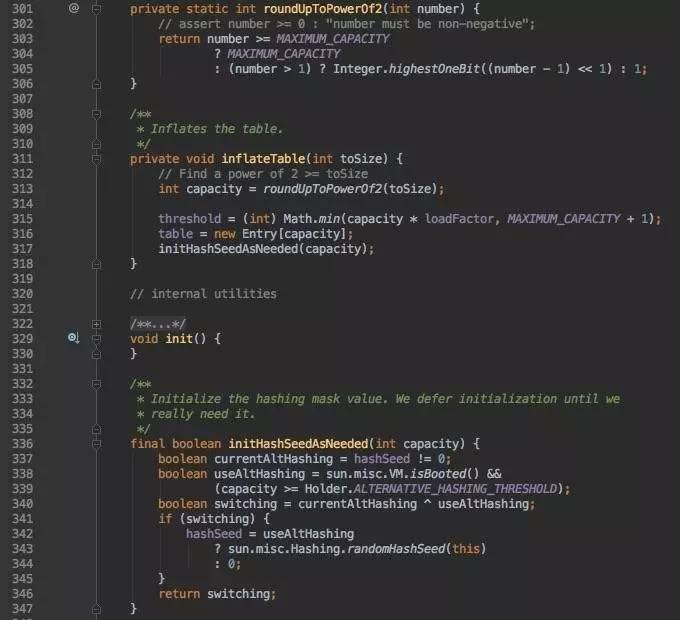
我们先看roundUpToPowerOf2方法返回一个比入参初始容量大的最小的2的幂数。至于为什么要2的幂次方,我们上文一开始就提及了;之后根据计算好的数组长度,创建Entry数组,并针对Bucket数组容量巨大的采用新的Hash算法。
init()
init函数提及一下,注释讲其作可作为一个钩子来被子类使用,它已经作为模版模式被所有的构造器,clone等调用。
为了接下来代码的理解,不得不先跳到HashMap的核心数据结构,真的是数据结构,数组,链表。
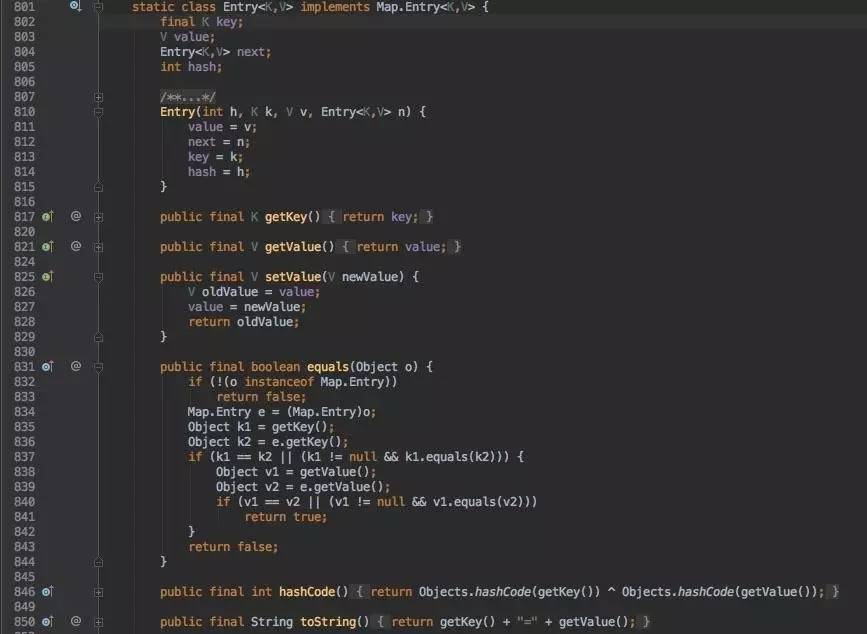
典型的链表数据结构;外边再套上数组new Entry[capacity], 就变成了数组Bucket, 每一个节点再挂一个链表的结构,即HashMap的数据结构。
如下图:
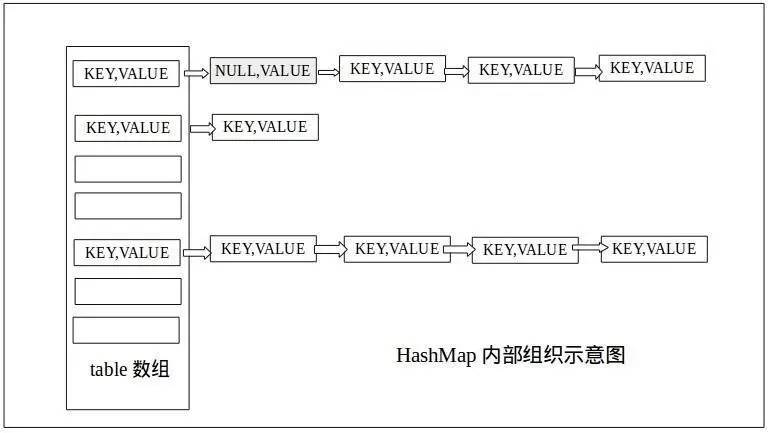
这个图再熟悉不过,数组+链表的基本数据结构构成了HashMap,相同的hash的对象存储在相同buket数组的下标,并用链表来连接起来。
hash()
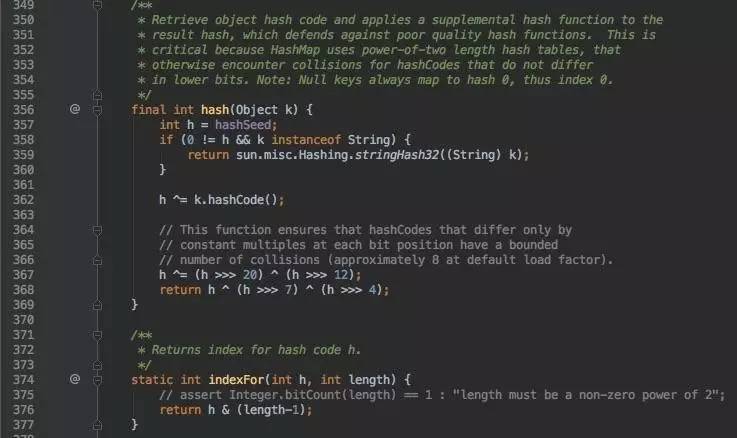
看到了一些神奇的位运算,云里雾里。为什么需要hash与indexFor这两个方法?注释中提到,hash是用来计算对象的hash值,indexFor是用来返回hash code对应的length中的下标。
如何自己实现get/put?
换一种思路,如果我们自己来实现HashMap的get/put核心方法如何做呢?
我们再回到HashMap的数据结构,数组+链表;而当我们put一个K,V时,需要把一个对象按照一定固定顺序(还需要能取出来)放到一个数组呢?首先我们想到一个对象的hash code可以一定程度上代表这个对象,虽然可能会多对一,会hash冲突,之后就可以把这个代表对象的hash code与数组长度进行取模运算,从而获得这个对象需要放到数组的下标;同理,当取get的时候,做类似的,计算hashcode,计算index下标。嗯,听起来不错。
恭喜,在早期版本的JDK中Hashtable就是这么类似实现的。

所以,至少我们总体思路是对了,下面就是如何优化了。
我们再回过头来看HashMap黑客同学如何黑。总体来说,HashMap做了一个自己的hash函数,用来1> 进一步离散 2> 针对低质量的hash函数,如字符串,进行特殊处理。据说在JDK 1.8中又删除了,没有确认。其中又分为二次散列,
第一次散列,调用k的hashCode方法,与hashSeed做异或操作;第二次散列,自己看吧,。。。。吃力。
至于indexFor, 这个我们上文提过,源自其特殊设计。当数组容量一定是2^n时:
h & (length - 1) 等价于 h % length,但他们是等价(效果)不等效(效率)的,位运算结果与取模一致,但效率更高;
get:
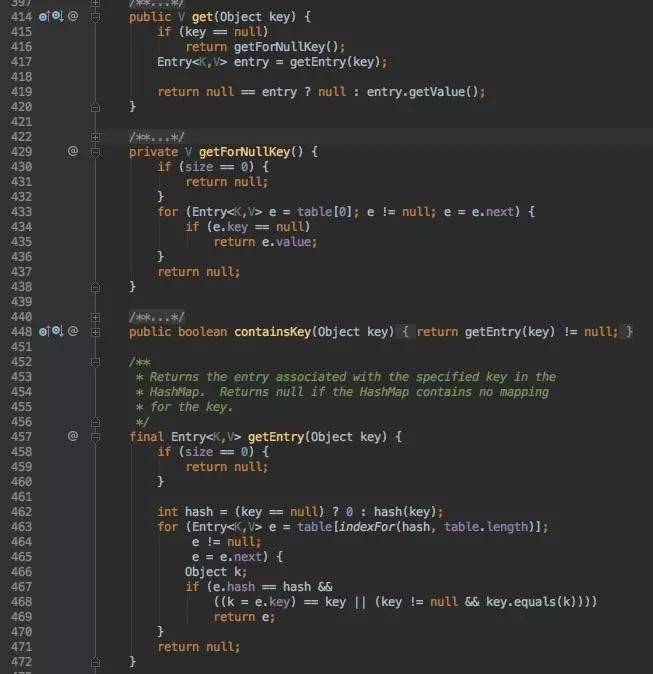
get写的很清晰,如果是null的key,则调用getForNullKey(); 否则调用getEntry。
getForNullKey中,因为nullkey对应的index为0,所以直接写table[0];
getEntry中,首先调用我们上文提到的hash函数进行进一步离散,然后定位到数组下标indexFor,随后一个循环来遍历链表;对于每一个node节点,再次比较其离散之后的hash值,key(活着引用相同,或者equals);够严谨高效,其原因是因为当bucket数组超过一定阀值后,会rehash,所以要再次确认一下是同一个buket下面的。
put:
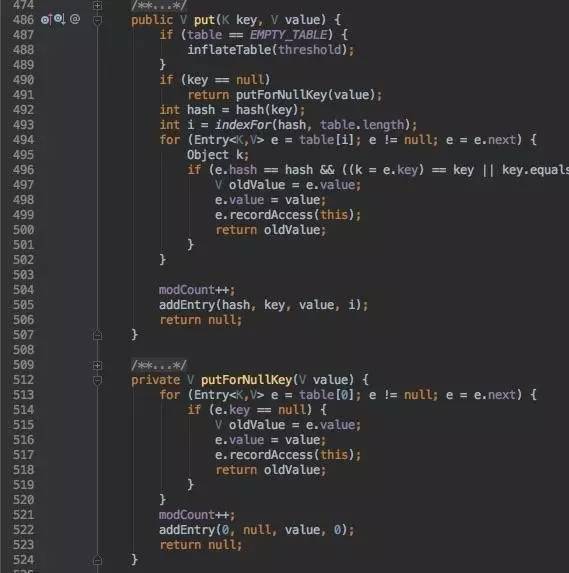
有了get的逻辑,put相对好理解一些了。
首先如果buket的table为null,调用我们上文提到的inflateTable来构造一个初始的数组。
如果为null的key,特殊处理一下,直接放到table[0]位置。
之后具体的put,
第一步也是调用hash进行进一步的离散key
第二步indexFor获取要放置数组的index
第三步找到index下标对应的链表,遍历并找到key相同的node节点,如果找到用新的值替换,并返回老的值;否则调用addEntry创建一个node节点。
addEntry:
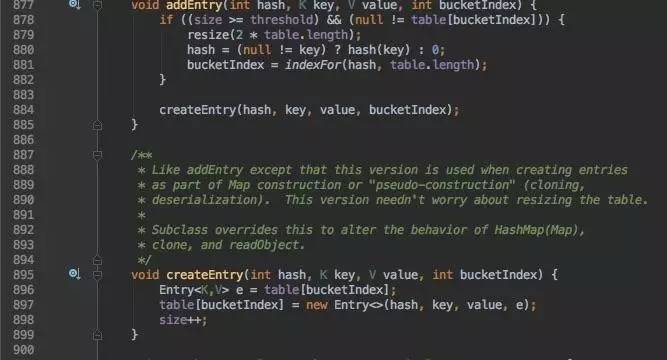
addEntry要注意一下,首先会先检测当前size是否超过阀值,超过的话,会resize,直接把bucket数组扩容2倍。
resize:
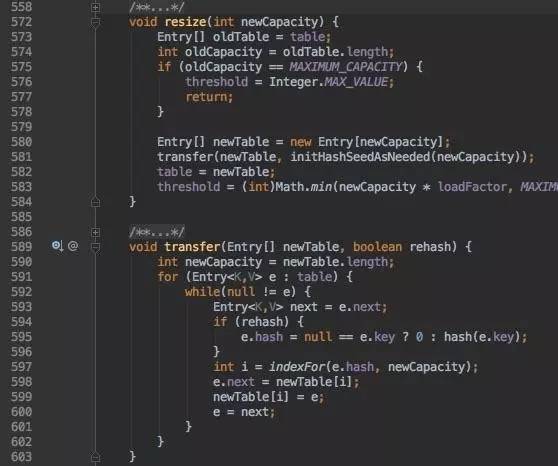
resize比较简单,根据新的capacity新建Entry数组,然后调用transfer复制目前HashMap。
transfer里面,直接遍历老的HashMap数组,如果需要rehash则调用hash方法,否则直接计算index并且放入新的Entry数组,结束。
再回到addEntry, 下一步createEntry,调用构造函数。
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
这句回到了数据结构课堂,它把新建的Entry节点node作为头部,然后挂上之前的链表,小伙伴有看出来么?
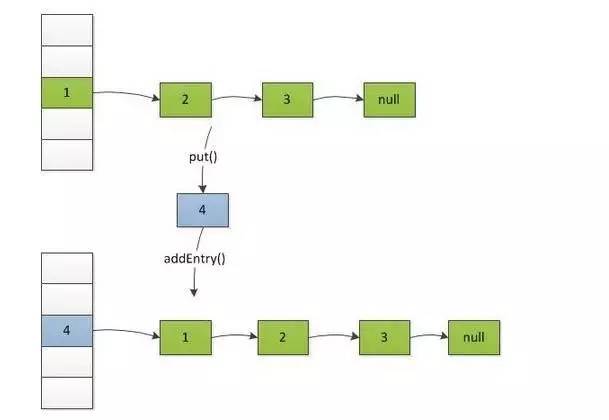
remove:
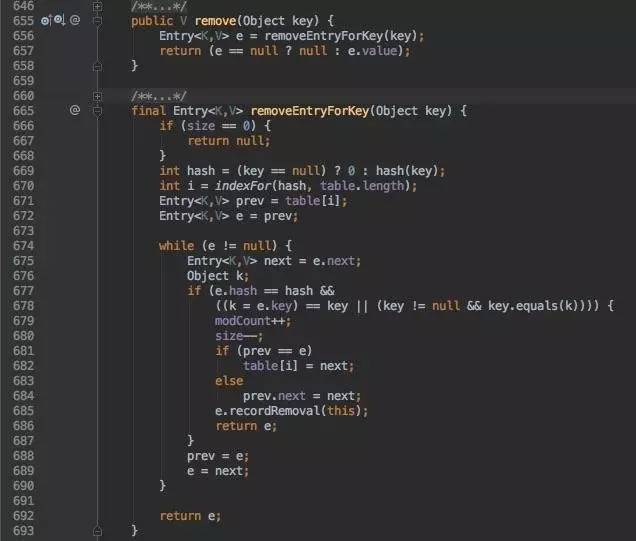
remove中调用removeEntryForKey, 这里没什么花头,标准的链表删除算法。
clear:
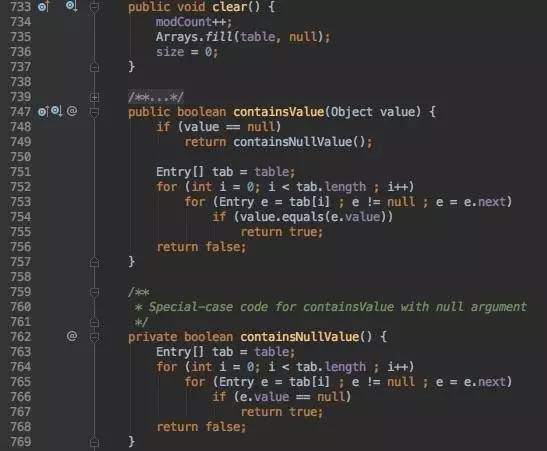
clear比较简单,Arrays.fill(table,null); 神笔,简单高效,暴力。
containsValue, 二重循环,查找算法。
clone:
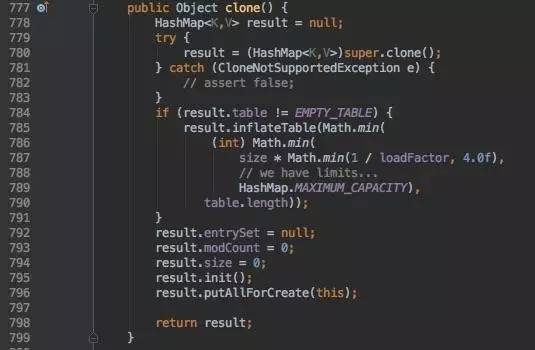
iterator:
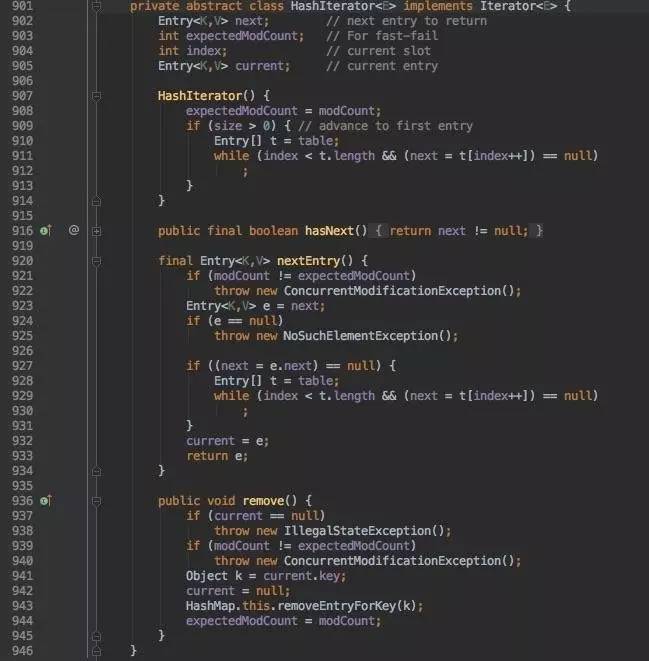
nextEntry()函数中,next的更新策略如下:首先查看当前“链表”是否已到结尾,若还没到,则next直接指向它的下一个”结点“;若已到”链表“结尾,则需要找到table数组中下一个不是指向空”链表“的那个元素,使next更新为”链表“首结点,同时更新index。
Serializable
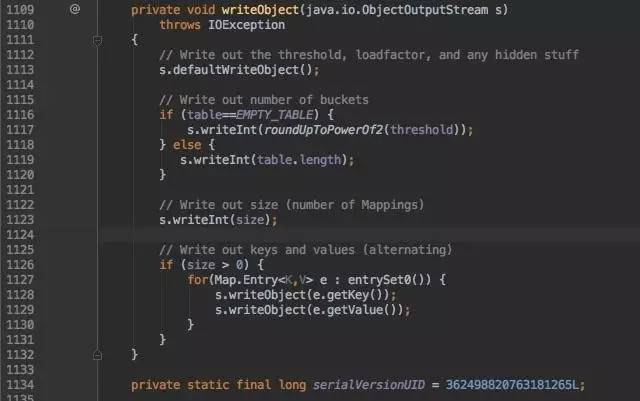
再看一个重要的功能,序列化HashMap。
上文我们提到,保存Entry的table数组为transient的,也就是说在进行序列化时,并不会包含该成员,但是如何解决呢,就用到了我们的自定义序列化了。
具体内容不说了,有同学看到是private,并且类内部无人调用过,一头雾水。
其实这个是自定义序列化做法,看参考Java序列化,序列化引擎会调用。
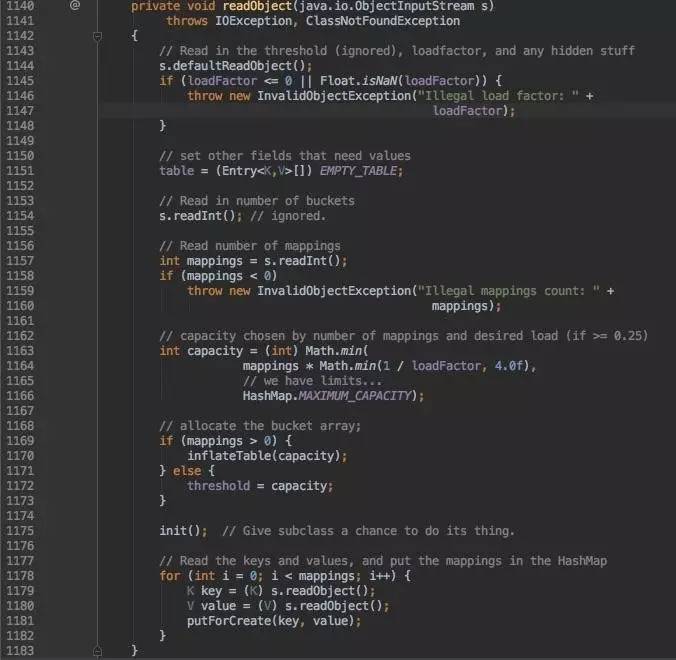
还有自定义读取了。
好了,1183行了,终于全部过了一遍,不容易啊。麻雀虽小,可是其功力很深啊。建议大家精读几次,这样也不旺大师神作,以后可以做到知己知彼,并且可以扩展至其他Java Collection框架源代码。
推荐阅读
.
以上是关于庖丁解牛HashMap源代码解析(多图)的主要内容,如果未能解决你的问题,请参考以下文章