科普一篇文章让你了解大数据采集平台Logstash
Posted 大数据人才基地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了科普一篇文章让你了解大数据采集平台Logstash相关的知识,希望对你有一定的参考价值。
在大数据领域,
开源数据栈ELK可谓是声名赫赫,ELK是什么呢?其实它就是
ElasticSearch、Logstash和Kibana的合称。本期酝馥君要为大家介绍的大数据采集平台其实就是ELK中的一员,它便是——
“ L”的 Logstash。
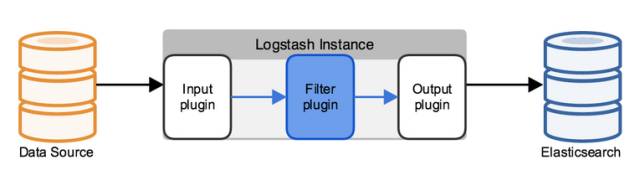
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
在一个典型的使用场景下(ELK):
用Elasticsearch作为后台数据的存储,kibana用来前端的报表展示。Logstash在其过程中担任搬运工的角色,它为数据存储,报表查询和日志解析创建了一个功能强大的管道链。Logstash提供了多种多样的 input,filters,codecs和output组件,让使用者轻松实现强大的功能。
官网:https://github.com/elastic/logstash
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
输入input --> 处理filter --> 输出output
每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
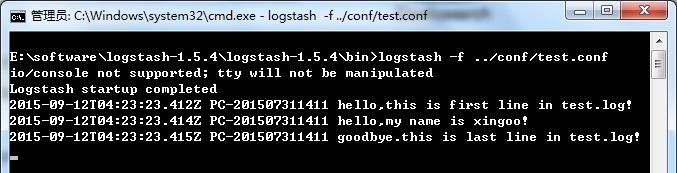
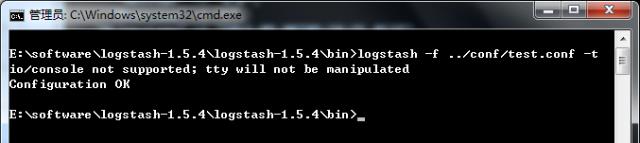
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
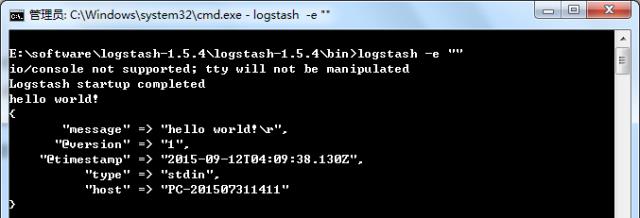
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
-l:日志输出的地址(默认就是stdout直接在控制台中输出)
别看它只做3件事,但通过组合输入和输出,可以变幻出多种架构实现多种需求。这里只抛出用以解决日志汇总需求的
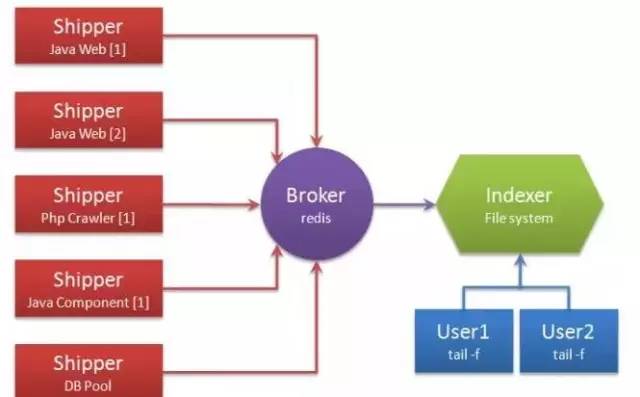
部署架构图:
·
Shipper:日志收集者。负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,输出到Redis暂存。
·
Indexer:日志存储者。负责从Redis接收日志,写入到本地文件。
·
Broker:日志Hub,用来连接多个Shipper和多个Indexer。
一个Logstash进程可以有多个输入源,所以一个Logstash进程可以同时读取一台服务器上的多个日志文件。Redis是Logstash官方推荐的Broker角色“人选”,支持订阅发布和队列两种数据传输模式,推荐使用。输入输出支持过滤,改写。Logstash支持多种输出源,可以配置多个输出实现数据的多份复制,也可以输出到Email,File,Tcp,或者作为其它程序的输入,又或者安装插件实现和其他系统的对接,比如搜索引擎Elasticsearch。
在开头酝馥君提起了ELK,但后来有人和酝馥君说不知道ELK的大名,所以在最后,酝馥君就为大家简单介绍下
ELK。
一个完整的日志分析技术栈需要实时收集,实时索引和展示三部分组成,Logstash只是这其中的第一个环节。Logstash所属的Elastic公司,已经开发了完整的日志分析技术栈,
它们是Elasticsearch,Logstash,和Kibana,也就是大名鼎鼎的ELK。
Elasticsearch是搜索引擎,而Kibana是Web展示界面。下面这张图就能够说明ELK三者的关系了。
“大数据人才基地”立足于产业发展,研究与应用结合,学术与商业融合,理论与实战结合,服务体系及标准课程与国际同步,通过人才培养、师资培训、实习实训、项目孵化、加速器、投融资等形式,提供成熟的大数据人才一体化创新创业平台,开展大数据技术创新、市场创新、人才创新、产品创新方面的研究和合作,为大数据产业发展提供人才智力服务,形成大数据人才学历与非学历培训中心、大数据人才职业技能认证与培训中心、大数据研发与成果转化中心、大数据周边产品研发中心。
以上是关于科普一篇文章让你了解大数据采集平台Logstash的主要内容,如果未能解决你的问题,请参考以下文章
让你全面了解TDengine
让你全面了解TDengine
让你全面了解TDengine
一篇文章让你了解Hadoop和MongoDB的联系与区别
开发者一定要了解的六款大数据采集平台
一文科普读懂机器学习,大数据/自然语言处理/算法全有了……