一篇文章让你了解Hadoop和MongoDB的联系与区别
Posted 大数据人才基地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇文章让你了解Hadoop和MongoDB的联系与区别相关的知识,希望对你有一定的参考价值。
近些年来,随着“大数据”理念的深入人心,越来越多的大数据工具被开发出来,就目前广为人知的大数据工具大大小小就有数十种,这些大数据工具都在各自的领域中有着举足轻重的地位,但随着科技的发展,不同的大数据工具之间的边际越来越模糊,例如
MongoDB
可以存储JSON文档,而一堆JSON文档也可存放在一个Hadoop集群的HDFS中,使用者可以使用这两种配置完成很多相同的事情。那么我们是否就可以说它们完全一样呢?答案自然是否定的,那么
Hadoop和MongoDB之间又有怎样的联系与区别呢?
Hadoop
是一个分布式并行系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的高速运算和海量存储。
MongoDB
是一个面向文档的NoSQL数据库,它拥有高可扩展及自动分片功能的特性,以JSON的形式进行数据的存储。MongoDB提供了一个文本索引类型来支持全文检索,基本的关键词搜索对应于文档的集合。
通过对MongoDB的介绍以及前几期对Hadoop的了解,我们可以知道,
如果使用者需要查询文档,并且包含更加复杂的分析过程,那么MongoDB相当适合;但如果有一个海量的数据,需要大量不同的复杂处理和分析,那么提供最为广泛的工具和灵活性的Hadoop无疑是最合适的。由此可见,每个工具都有自身最为适用的场景,寻找它们的区别,使用于不同的场景中,才是最正确的选择。
MongoDB和
Hadoop在功能重叠的存取性能上的区别到底有哪些呢?
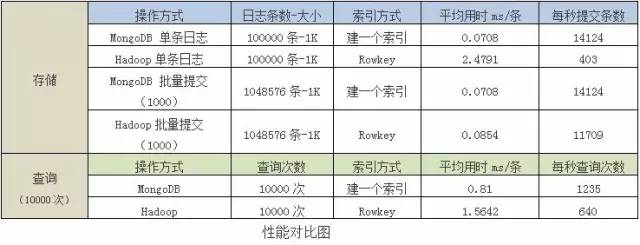
从测试结果看,
MongoDB
的存储、查询速度都非常快,不管是逐条存储还是批量存储,都能达到每秒存储14000条1k的日志。而Hadoop逐条存储性能较低,批量存储时性能却很好。两者都很适合来存海量日志,它们技术成熟,文档也非常丰富,在互联网行业应用很广泛。 但
Hadoop
适合存储无结构化的数据,而MongoDB存储的则是文档类型数据,类似Json结构,处理结构化的数据会更方便。
MongoDB还有一个极其强大的特性称之为“
Capped collections”。使用这个特性,用户可以
定义一个collection的最大size——然后这个collection可以被盲写,并且会roll-over必须的数据来获取log和其他供分析的流数据。但
MongoDB对大量数据的处理却是它的短板,在这一方面上,
Hadoop就更为合适了,它是老
MapReduce了,
可以提供最为灵活和强大的环境来进行大量数据的处理。
对大多数的用户来说,能否选择到最合适的工具来做事,关乎他们工作结果的成功与失败。在大数据这样的背景下,技术层出不穷,技术工具间的界限也是相当的模糊,只有在特定的场景选择最合适的工具,才能够真正的帮助我们解决问题。Mongodb与Hadoop便是其中最明显的例子,虽然二者在某些功能上有着重叠,但若是
正确区分它们之间的差异,选择最为合适的工具,对使用者来说才是最为受益的。
“大数据人才基地”立足于产业发展,研究与应用结合,学术与商业融合,理论与实战结合,服务体系及标准课程与国际同步,通过人才培养、师资培训、实习实训、项目孵化、加速器、投融资等形式,提供成熟的大数据人才一体化创新创业平台,开展大数据技术创新、市场创新、人才创新、产品创新方面的研究和合作,为大数据产业发展提供人才智力服务,形成大数据人才学历与非学历培训中心、大数据人才职业技能认证与培训中心、大数据研发与成果转化中心、大数据周边产品研发中心。
以上是关于一篇文章让你了解Hadoop和MongoDB的联系与区别的主要内容,如果未能解决你的问题,请参考以下文章
一篇文章让你搞懂Mysql InnoDB内存结构
一篇文章让你了解Git操作
使用hadoop mapreduce分析mongodb数据
科普一篇文章让你了解大数据采集平台Logstash
一篇文章让你了解DNS
一篇文章让你了解GC垃圾回收器