大数据分析利器ElasticSearch入门
Posted 码农进阶之路2020
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据分析利器ElasticSearch入门相关的知识,希望对你有一定的参考价值。
1 为什么要学习ElasticSearch?
最著名的公司就是github,它采用ES作为搜素引擎对代码进行搜索,虽然它是一款分布式搜索引擎,但是它强大的查询、分析和聚合能力使他与数据库的边界越来越模糊。因此很多大公司都喜欢用ES来存储日志或其他业务数据。最常见的结合就是通过kafka、redis来作数据源,logstash进行转化,ES对数据进行存储、kibana对数据进行展示,ES+logstash+kibana(ELK)一体化的日志分析、业务指标分析。
越来越多的公司使用ES,这门技术已不再是大数据工程师必须要掌握的了,ES还提供了Java、Python等API,因此ES将会成为Java和Python工程师必不可少的工具,灵活应用ES将会成为你在未来的一项非常具有竞争力的能力!
ES是分布式的,并且在数据量超大的情况下其查询速度也非常快;
ES是一个近实时的搜索引擎(平台),代表着从添加数据到能被搜索到只有很少的延迟。(大约是1s)
对象中无论多么复杂的关系都可以用JSON格式表达出来,可读性非常高,ES就是以JSON格式存储存储数据的;
支持在线分析、实时分析,ES是基于存储、查询、聚合分析和可视化于一体的解决方案
从数据获取、存储计算到可视化,ES开发了一整套解决方案,Logstash、Beat负责抓取数据,ES负责存储计算,kibana对数据进行展示分析;
收费的X-Pack可以实现安全告警、告警、监控和ML等丰富的功能;
ES在搜索、日志分析、指标分析和安全分析等领域应用广泛,从前端到后端,从云服务器到最流行的及其学习,ES都提供了一整套解决方案
2 ElasticSearch基本概念
2.1 文档
索引是具有某种相似特性的文档集合。例如,您可以拥有客户数据的索引、产品目录的另一个索引以及订单数据的另一个索引。索引由一个名称(必须全部是小写)标识。在单个集群中,您可以定义任意多个索引。Index体现了逻辑空间的概念,每个索引都有自己的mapping定义,用于定义包含文档的字段名和字段类型。Index体现了物理空间的概念,索引中的数据分散在shard上。可以将其暂时理解为 mysql中的 database。
索引的mapping和setting
-
mapping:定义文档字段的类型 -
setting:定义不同数据的分布
2.3 类型
从6.0开始,type已经被逐渐废弃。在7.0之前,一个index可以设置多个types。7.0开始一个索引只能创建一个type(_doc)
2.4 节点
节点是一个Elasticsearch实例,本质上就是一个java进程,节点也有一个名称(默认是随机分配的),当然也可以通过配置文件配置,或者在启动的时候,-E node.name=node1指定。此名称对于管理目的很重要,因为您希望确定网络中的哪些服务器对应于ElasticSearch集群中的哪些节点。
在Elasticsearch中,节点的类型主要分为如下几种:
master eligible节点
当第一个节点启动后,它会将自己选为master节点
每个节点都保存了集群的状态,只有master节点才能修改集群的状态
data节点
可以保存数据的节点。负责保存分片数据,在数据扩展上起到了至关重要的作用
Coordinating 节点
负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
每个节点默认都起到了Coordinating node的职责
2.5 分片
索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。例如,占用1TB磁盘空间的10亿个文档的单个索引可能不适合单个节点的磁盘,或者速度太慢,无法单独满足单个节点的搜索请求。
为了解决这个问题,ElasticSearch提供了将索引细分为多个片段(称为碎片)的能力。创建索引时,只需定义所需的碎片数量。每个分片(shard)本身就是一个完全功能性和独立的“索引”,可以托管在集群中的任何节点上。
为什么要分片?
-
它允许您水平拆分/缩放内容量 -
它允许您跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量
2.6 分片副本
-
当分片/节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始/主分片所在的节点上。 -
允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。
可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您还可以随时动态更改副本的数量。您可以使用收缩和拆分API更改现有索引的分片数量,建议在创建索引时就考虑好分片和副本的数量。
默认情况下,ES中的每个索引都分配一个主分片和一个副本,这意味着如果集群中至少有两个节点,则索引将有一个主分片和另一个副本分片(一个完整副本),每个索引总共有两个分片。
2.7 倒排索引

DocID:出现某单词的文档ID
TF(词频):单词在该文档中出现的次数
POS:单词在文档中的位置

3 Linux系统下elasticsearch-7.3.2的安装
https://www.elastic.co/cn/downloads/elasticsearch
tar -zxvf esticsearch-7.3.2-linux-x86_64.tar.gz
groupadd elasticsearchuseradd elasticsearch -g elasticsearch:elasticsearch
在6.xx之前,可以通过root用户启动。但是发现黑客可以透过elasticsearch获取root用户密码,所以为了安全性,在6版本之后就不能通过root启动elasticsearch。所以这里专门创建了elasticsearch用户用于启动ES服务
3.2 修改配置
1) 调整JVM大小(内存大也可不要调整)
执行 vim ./elasticsearch-7.3.2/config/jvm.options
-Xms512m-Xmx512m## 将原来的1g改小为512m,然后按住esc+:后输入wq!保存退出
2) 修改network配置,支持通过ip访问
执行 vim ./elasticsearch-7.3.2/config/elasticsearch.yml
cluster.name=lubannode.name=node-1network.host: 0.0.0.0http.port: 9200cluster.initial_master_nodes: ["node-1"]max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]vm最大虚拟内存,max_map_count[65530]太低,至少增加到[262144]
执行 vim /etc/sysctl.conf
=655360sysctl -p 使配置生效descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]最大文件描述符[4096]对于elasticsearch进程可能太低,至少增加到[65536]# 按住esc+:后输入wq!保存退出
执行 vim /etc/security/limits.conf
* soft nofile 65536* hard nofile 131072* soft nproc 2048* hard nproc 4096* 所有用户nofile - 打开文件的最大数目noproc - 进程的最大数目soft 指的是当前系统生效的设置值hard 表明系统中所能设定的最大值
用户的最大线程数[2048]过低,增加到至少[4096]
由于ES7.0以上版本依赖JDK11以上版本,ES7.3.2版本安装包中自带了JDK12,但是如果你下系统环境变量中指定了之前安装的JDK8路径,那么启动时会报错。为了解决ES7.3.2启动报错的问题,我们可以先在系统中安装JDK11并配置环境变量。
1) 使用ftp将jdk-11.0.7_linux-x64_bin.tar.gz文件上传到CentOS7服务器上的/opt/jdk11_linux目录下(读者可自定义目标目录)
tar -zxvf jdk-11.0.7_linux-x64_bin.tar.gz解压后为jdk-11.0.7目录

jdk_11.0.7为笔者之前通过ZIP包安装的JDK11
export JAVA_HOME=/opt/jdk11_linux/jdk-11.0.7export CLASSPATH=$JAVA_HOME/lib:$CLASSPATHexport PATH=$JAVA_HOME/bin:$PATH# 按住"esc"+":"后输入wq!保存退出

#开发9200端口firewall-cmd --permanent --zone=public --add-port=tcp/9200#重启防火墙firewall-cmd --reload
因为笔者使用的是腾讯云服务器,所以还需要等六腾讯云控制台,在安全组中添加9200端口的入站规则,如下所示:
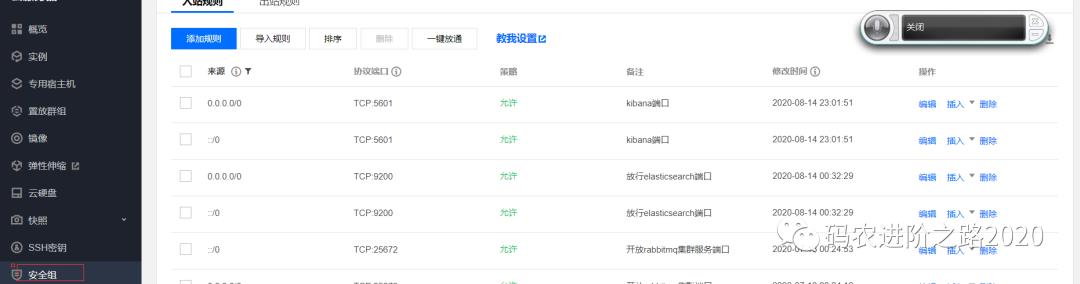
3.5 启动ES服务
{"name" : "node-1","cluster_name" : "luban","cluster_uuid" : "X5ohaHE0QVae03k7lGJHlg","version" : {"number" : "7.3.2","build_flavor" : "default","build_type" : "tar","build_hash" : "1c1faf1","build_date" : "2019-09-06T14:40:30.409026Z","build_snapshot" : false,"lucene_version" : "8.1.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
{"name" : "HESHENGFU1211","cluster_name" : "elasticsearch","cluster_uuid" : "yPgXhV3CS9eh1zGmBti0HQ","version" : {"number" : "7.3.2","build_flavor" : "default","build_type" : "zip","build_hash" : "1c1faf1","build_date" : "2019-09-06T14:40:30.409026Z","build_snapshot" : false,"lucene_version" : "8.1.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}

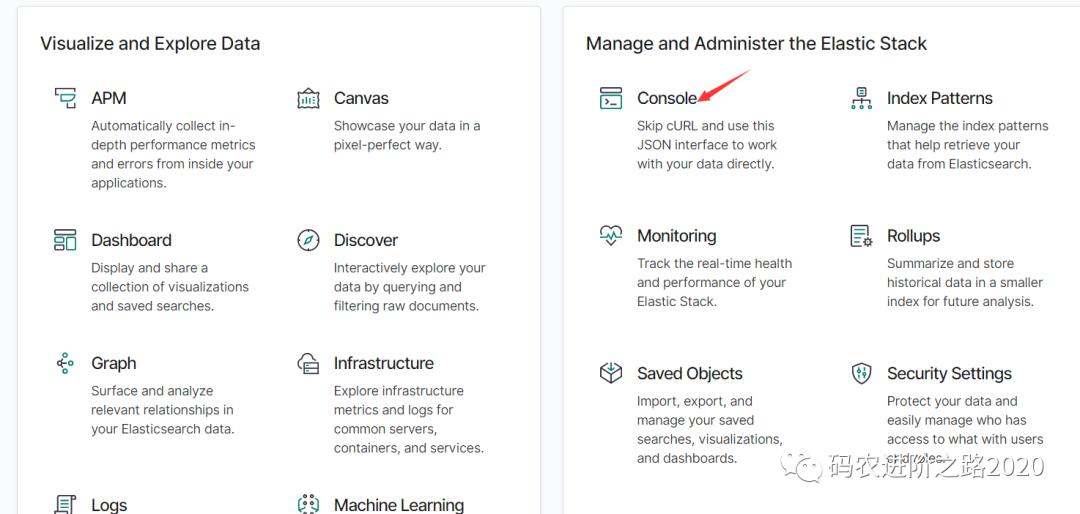
点击界面上的Console菜单可进入控制台,使用Rest API对ES数据进行CRUD操作
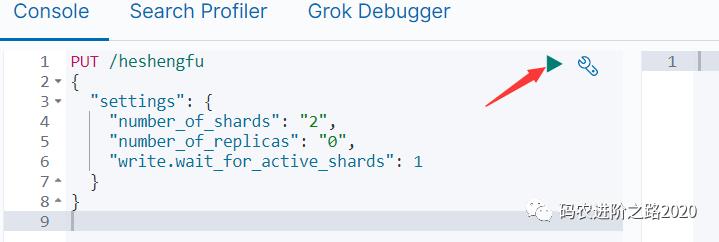
点击右边的按钮执行更改操作后,再执行查询操作 GET /heshengfu
可看到右边出现json格式的查询结果
GET /heshengfu{"heshengfu" : {"aliases" : { },"mappings" : { },"settings" : {"index" : {"number_of_shards" : "2","provided_name" : "heshengfu","creation_date" : "1597542252650","number_of_replicas" : "0","uuid" : "shjcXhALTnuDed9I9sfFJA","version" : {"created" : "7030299"},"write" : {"wait_for_active_shards" : "1"}}}}}

【腾讯云】云产品限时秒杀,爆款1核2G云服务器,首年99元
https://cloud.tencent.com/act/cps/redirect?redirect=1062&cps_key=8f10246034787fddf87d59a8f400c9bd&from=console
【腾讯云】ElasticSearch新用户特惠,快速实现日志分析、应用搜索,首购低至4折
https://cloud.tencent.com/act/cps/redirect?redirect=1066&cps_key=8f10246034787fddf87d59a8f400c9bd&from=console
【腾讯云】云数据库MySQL基础版1元体验,为中小企业量身打造,单节点架构,保证数据可靠性
https://cloud.tencent.com/act/cps/redirect?redirect=1034&cps_key=8f10246034787fddf87d59a8f400c9bd&from=console
以上是关于大数据分析利器ElasticSearch入门的主要内容,如果未能解决你的问题,请参考以下文章
Flink 实践教程:入门:写入 Elasticsearch
Elasticsearch全文检索技术 一篇文章即可从入门到精通(Elasticsearch安装,安装kibana,安装ik分词器,数据的增删改查,全文检索查询,聚合aggregations)(代码片