OLAP系统解析:Apache Kylin和Baidu Palo哪家强?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OLAP系统解析:Apache Kylin和Baidu Palo哪家强?相关的知识,希望对你有一定的参考价值。
本文对 Apache Kylin 的理解基于近两年来在生产环境大规模地使用,运维和深度开发,我已向 Kylin 社区贡献了 98 次 Commit,包含多项新功能和深度优化。本文对 Baidu Palo 的理解基于官方文档和论文的阅读,代码的粗浅阅读和较深入地测试。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
1 系统架构
1.1 What is Kylin
1.2 What is Palo
2 数据模型
2.1 Kylin 的聚合模型
2.2 Palo 的聚合模型
2.3 Kylin Cuboid VS Palo RollUp
2.4 Palo 的明细模型
3 存储引擎
4 数据导入
5 查询
6 精确去重
7 元数据
8 高性能
9 高可用
10 可维护性
10.1 部署
10.2 运维
10.3 客服
11 易用性
11.1 查询接入
11.2 学习成本
11.3 Schema Change
12 功能
13 社区和生态
14 总结
15 参考资料
注: 本文的对比 基于 Apache Kylin 2.0.0 和 Baidu Palo 0.8.0。
Kylin 的核心思想是预计算,利用空间换时间来 加速查询模式固定的 OLAP 查询。
Kylin 的理论基础是 Cube 理论,每一种维度组合称之为 Cuboid,所有 Cuboid 的集合是 Cube。 其中由所有维度组成的 Cuboid 称为 Base Cuboid,图中 (A,B,C,D) 即为 Base Cuboid,所有的 Cuboid 都可以基于 Base Cuboid 计算出来。 在查询时,Kylin 会自动选择满足条件的最“小”Cuboid,比如下面的 SQL 就会对应 Cuboid(A,B):
select xx from table where A=xx group by B
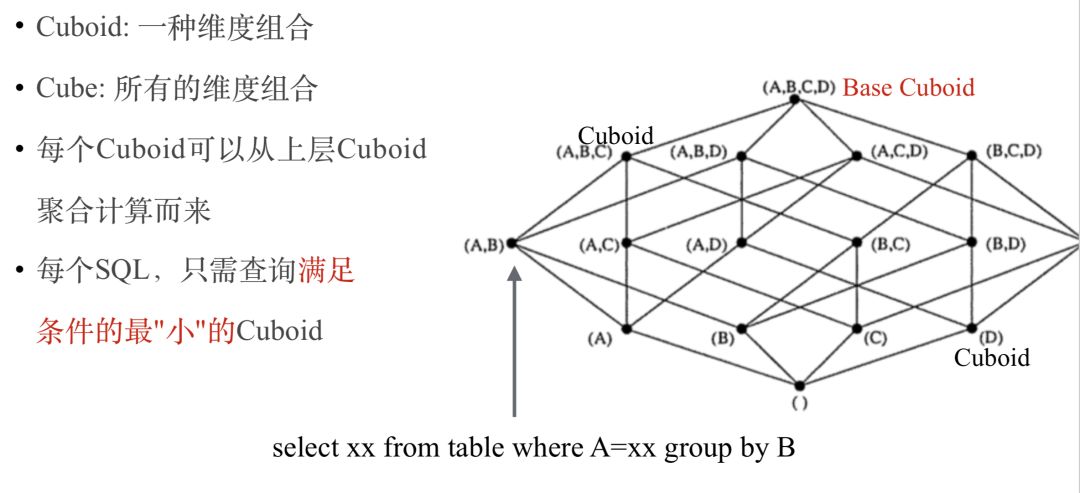
Kylin-cube
下图是 Kylin 数据流转的示意图,Kylin 自身的组件只有两个:JobServer 和 QueryServer。 Kylin 的 JobServer 主要负责将数据源(Hive,Kafka)的数据通过计算引擎(MapReduce,Spark)生成 Cube 存储到存储引擎(HBase)中;QueryServer 主要负责 SQL 的解析,逻辑计划的生成和优化,向 HBase 的多个 Region 发起请求,并对多个 Region 的结果进行汇总,生成最终的结果集。
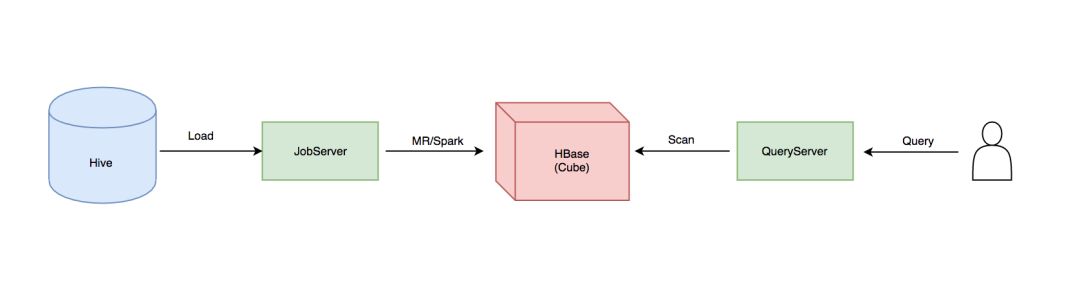
kylin-data
下图是 Kylin 可插拔的架构图, 在架构设计上,Kylin 的数据源,构建 Cube 的 计算引擎,存储引擎都是可插拔的。Kylin 的核心就是这套可插拔架构,Cube 数据模型和 Cuboid 的算法。
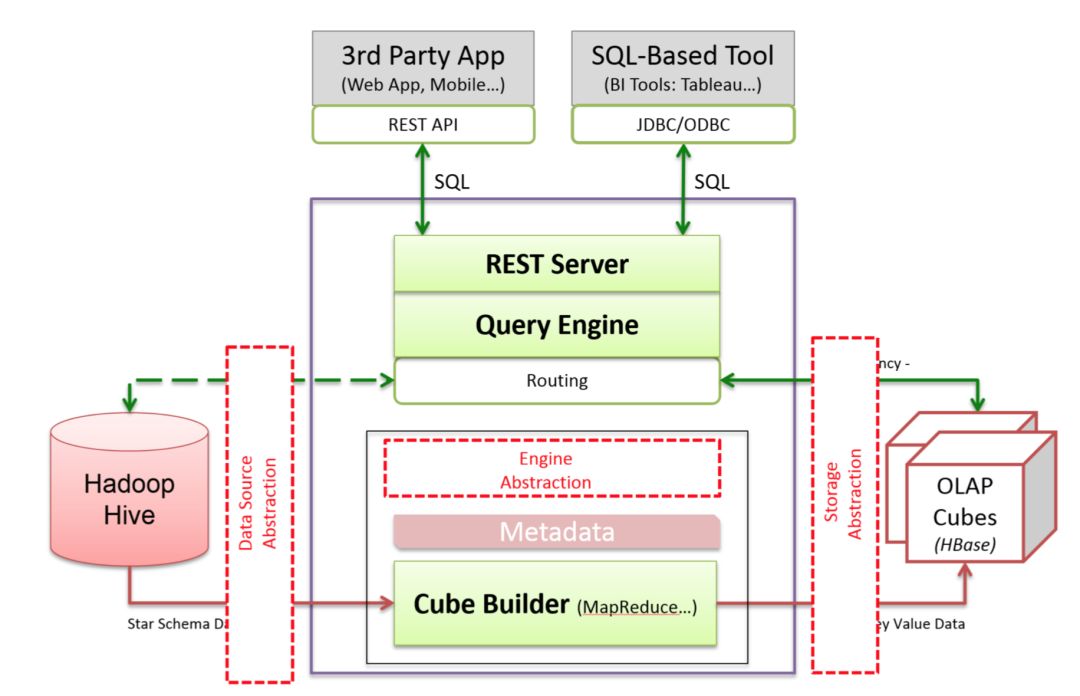
Kylin
Palo 是一个基于 MPP 的 OLAP 系统,主要整合了 Google Mesa(数据模型),Apache Impala(MPP Query Engine) 和 Apache ORCFile(存储格式,编码和压缩) 的技术。
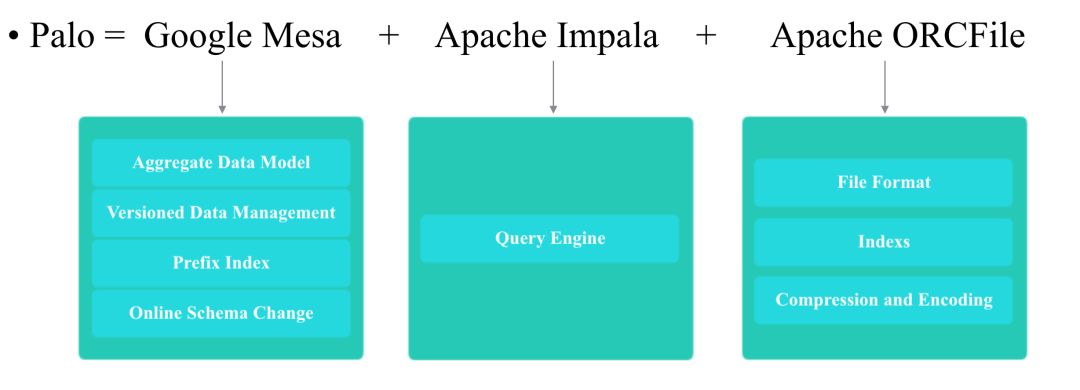
baidu-palo
Palo 的系统架构如下,Palo 主要分为 FE 和 BE 两个组件,FE 主要负责查询的编译,分发和元数据管理(基于内存,类似 HDFS NN);BE 主要负责查询的执行和存储系统。
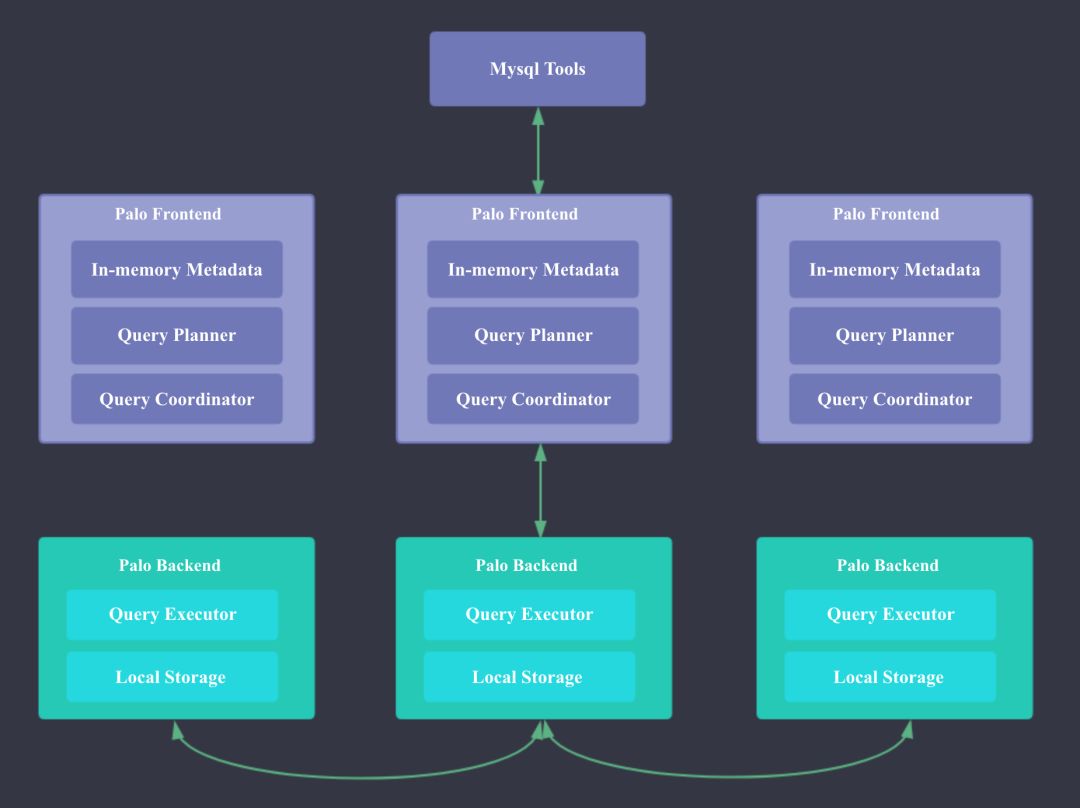
baidu-palo
Kylin 将表中的列分为维度列和指标列。在数据导入和查询时相同维度列中的指标会按照对应的聚合函数 (Sum, Count, Min, Max, 精确去重,近似去重,百分位数,TOPN) 进行聚合。
在存储到 HBase 时,Cuboid+ 维度 会作为 HBase 的 Rowkey, 指标会作为 HBase 的 Value,一般所有指标会在 HBase 的一个列族,每列对应一个指标,但对于较大的去重指标会单独拆分到第 2 个列族。
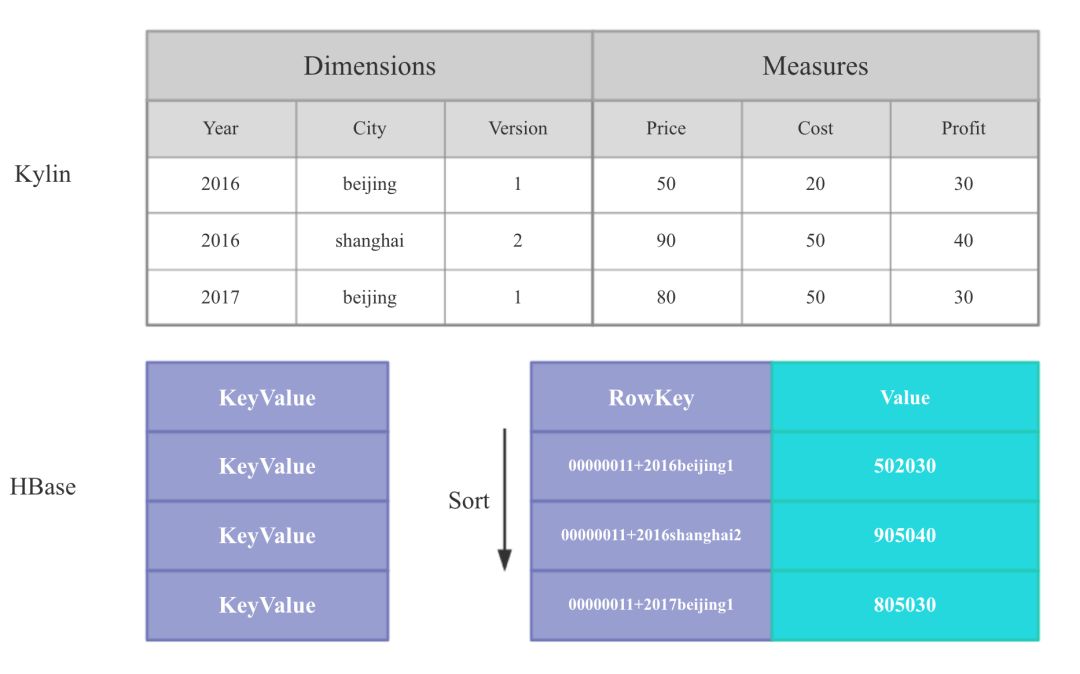
Kylin-model
Palo 的聚合模型借鉴自 Mesa,但本质上和 Kylin 的聚合模型一样,只不过 Palo 中将维度称作 Key,指标称作 Value。
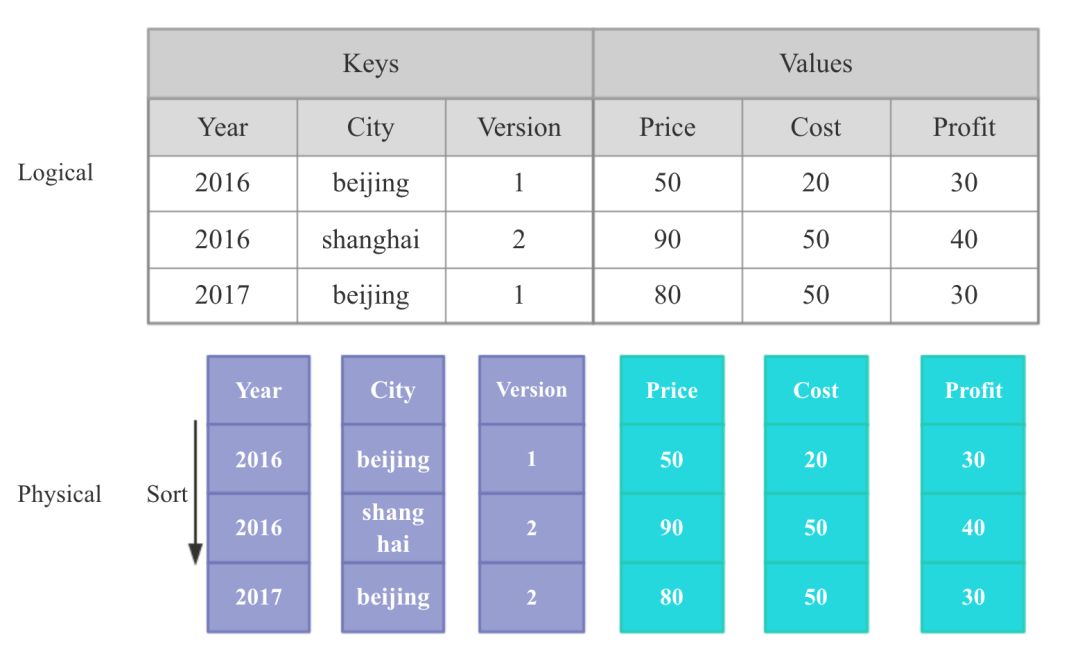
palo-data-model
Palo 中比较独特的聚合函数是 Replace 函数,这个聚合函数能够保证相同 Keys 的记录只保留最新的 Value, 可以借助这个 Replace 函数来实现 点更新。一般 OLAP 系统的数据都是只支持 Append 的,但是像电商中交易的退款,广告点击中的无效点击处理,都需要去更新之前写入的单条数据,在 Kylin 这种没有 Relpace 函数的系统中我们必须把包含对应更新记录的整个 Segment 数据全部重刷,但是有了 Relpace 函数,我们只需要再追加 1 条新的记录即可。 但是 Palo 中的 Repalce 函数有个缺点:无法支持预聚合, 就是说只要你的 SQL 中包含了 Repalce 函数,即使有其他可以已经预聚合的 Sum,Max 指标,也必须现场计算。
为什么 Palo 可以支持点更新呢?
Kylin 中的 Segment 是不可变的,也就是说 HFile 一旦生成,就不再发生任何变化。但是 Palo 中的 Segment 文件和 HBase 一样,是可以进行 Compaction 的,具体可以参考 Google Mesa 论文解读中的 Mesa 数据版本化管理(https://blog.bcmeng.com/post/google-mesa.html#mesa%E6%95%B0%E6%8D%AE%E7%89%88%E6%9C%AC%E5%8C%96%E7%AE%A1%E7%90%86)
Palo 的聚合模型相比 Kylin 有个缺点:就是一个 Column 只能有一个预聚合函数,无法设置多个预聚合函数。 不过 Palo 可以现场计算其他的聚合函数。 Baidu Palo 的开发者 Review 时提到,针对这个问题,Palo 还有一种解法:由于 Palo 支持多表导入的原子更新,所以 1 个 Column 需要多个聚合函数时,可以在 Palo 中建多张表,同一份数据导入时,Palo 可以同时原子更新多张 Palo 表,缺点是多张 Palo 表的查询路由需要应用层来完成。
Palo 中和 Kylin 的 Cuboid 等价的概念是 RollUp 表,Cuboid 和 RollUp 表都可以认为是一种 Materialized Views 或者 Index。 Palo 的 RollUp 表和 Kylin 的 Cuboid 一样,** 在查询时不需要显示指定,系统内部会根据查询条件进行路由。 如下图所示:
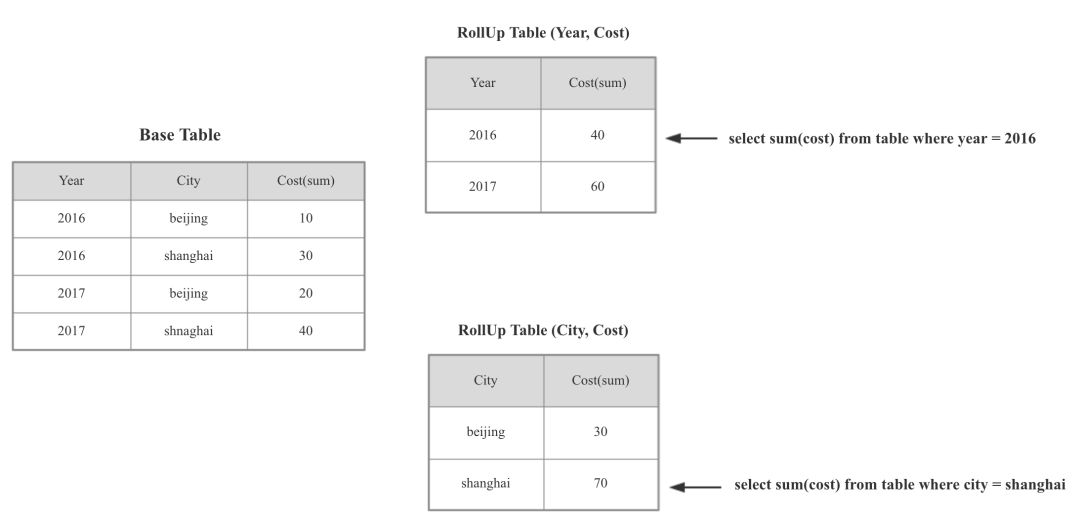
Palo Rollup
Palo 中 RollUp 表的路由规则如下:
选择包含所有查询列的 RollUp 表
按照过滤和排序的 Column 筛选最符合的 RollUp 表
按照 Join 的 Column 筛选最符合的 RollUp 表
行数最小的
列数最小的
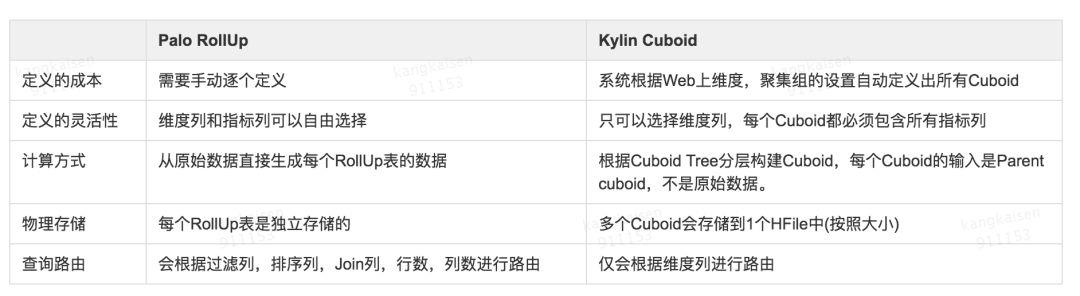
Kylin cuboid vs palo rollup
由于 Palo 的聚合模型存在下面的缺陷,Palo 引入了明细模型。
必须区分维度列和指标列
维度列很多时,Sort 的成本很高
Count 成本很高,需要读取所有维度列(可以参考 Kylin 的解决方法进行优化)
Palo 的明细模型不会有任何聚合,不区分维度列和指标列,但是在建表时需要指定 Sort Columns,数据导入时会根据 Sort Columns 进行排序,查询时根据 Sort Column 过滤会比较高效。
如下图所示,Sort Columns 是 Year 和 City。
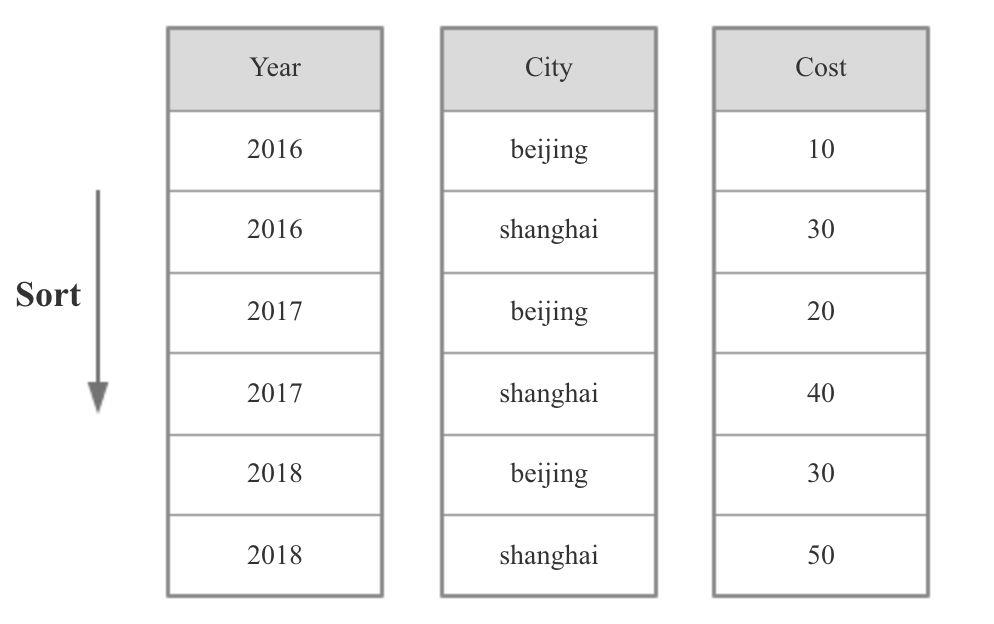
Kylin-detail-model
这里需要注意一点,Palo 中一张表只能有一种数据模型,即要么是聚合模型,要么是明细模型,而且 Roll Up 表的数据模型必须和 Base 表一致, 也就是说明细模型的 Base 表不能有聚合模型的 Roll Up 表。
Kylin 存储引擎 HBase:
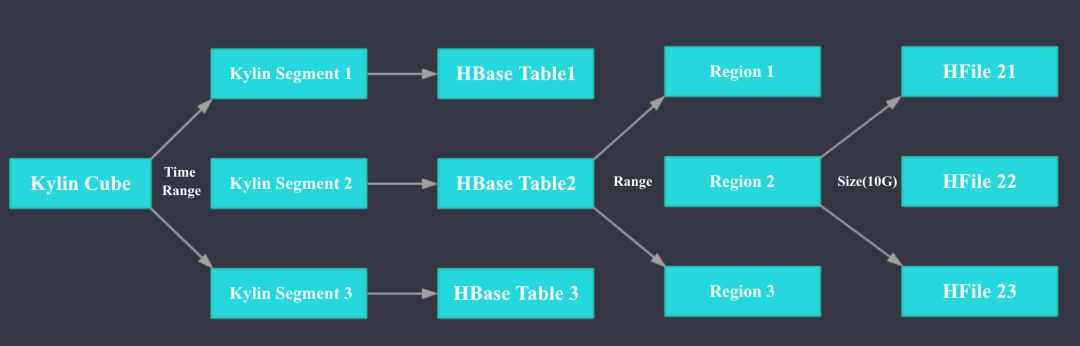
如上图所示,在 Kylin 中 1 个 Cube 可以按照时间拆分为多个 Segment,Segment 是 Kylin 中数据导入和刷新的最小单位。Kylin 中 1 个 Segment 对应 HBase 中一张 Table。 HBase 中的 Table 会按照 Range 分区拆分为多个 Region, 每个 Region 会按照大小拆分为多个 HFile。
关于 HFile 的原理网上讲述的文章已经很多了,我这里简单介绍下。首先 HFile 整体上可以分为元信息,Blcoks,Index3 部分,Blcoks 和 Index 都可以分为 Data 和 Meta 两部分。Block 是数据读取的最小单位,Block 有多个 Key-Value 组成,一个 Key-Value 代表 HBase 中的一行记录,Key-Value 由 Kylin-Len,Value-Len,Key-Bytes,Value-Bytes 4 部分组成。更详细的信息大家可以参考下图 (下图来源于互联网,具体出处不详):
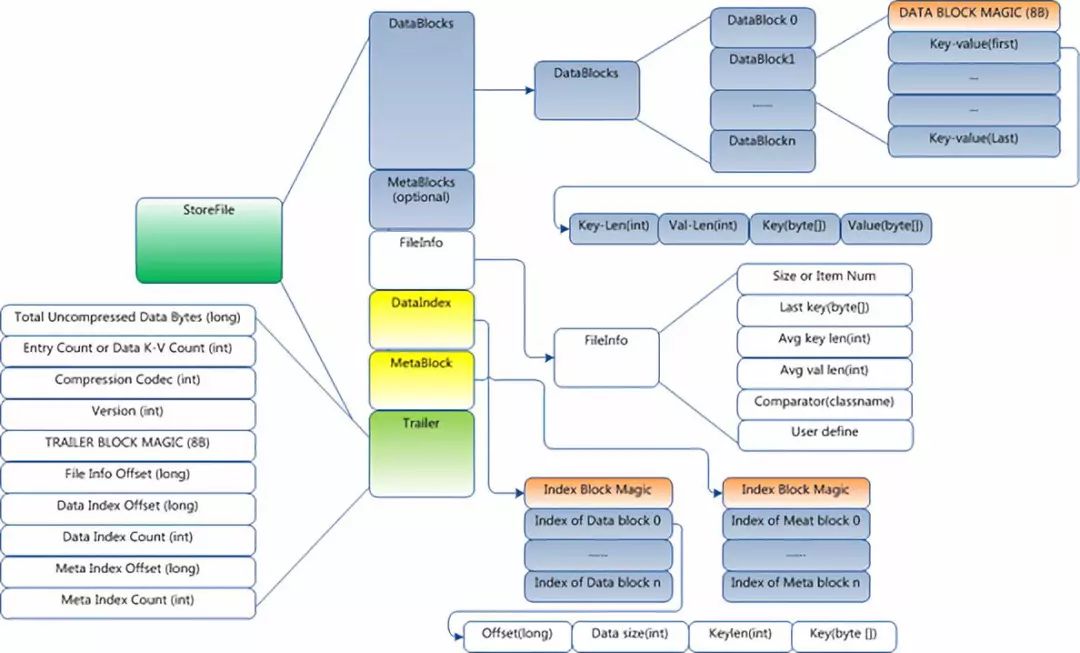
HBase-HFile
Palo 存储引擎:
如上图所示,Palo 的 Table 支持二级分区,可以先按照日期列进行一级分区,再按照指定列 Hash 分桶。具体来说,1 个 Table 可以按照日期列分为多个 Partition, 每个 Partition 可以包含多个 Tablet,Tablet 是数据移动、复制等操作的最小物理存储单元, 各个 Tablet 之间的数据没有交集,并且在物理上独立存储。Partition 可以视为逻辑上最小的管理单元,数据的导入与删除,仅能针对一个 Partition 进行。1 个 Table 中 Tablet 的数量 = Partition num * Bucket num。Tablet 会按照一定大小(256M)拆分为多个 Segment 文件,Segment 是列存的,但是会按行(1024)拆分为多个 Rowblock。
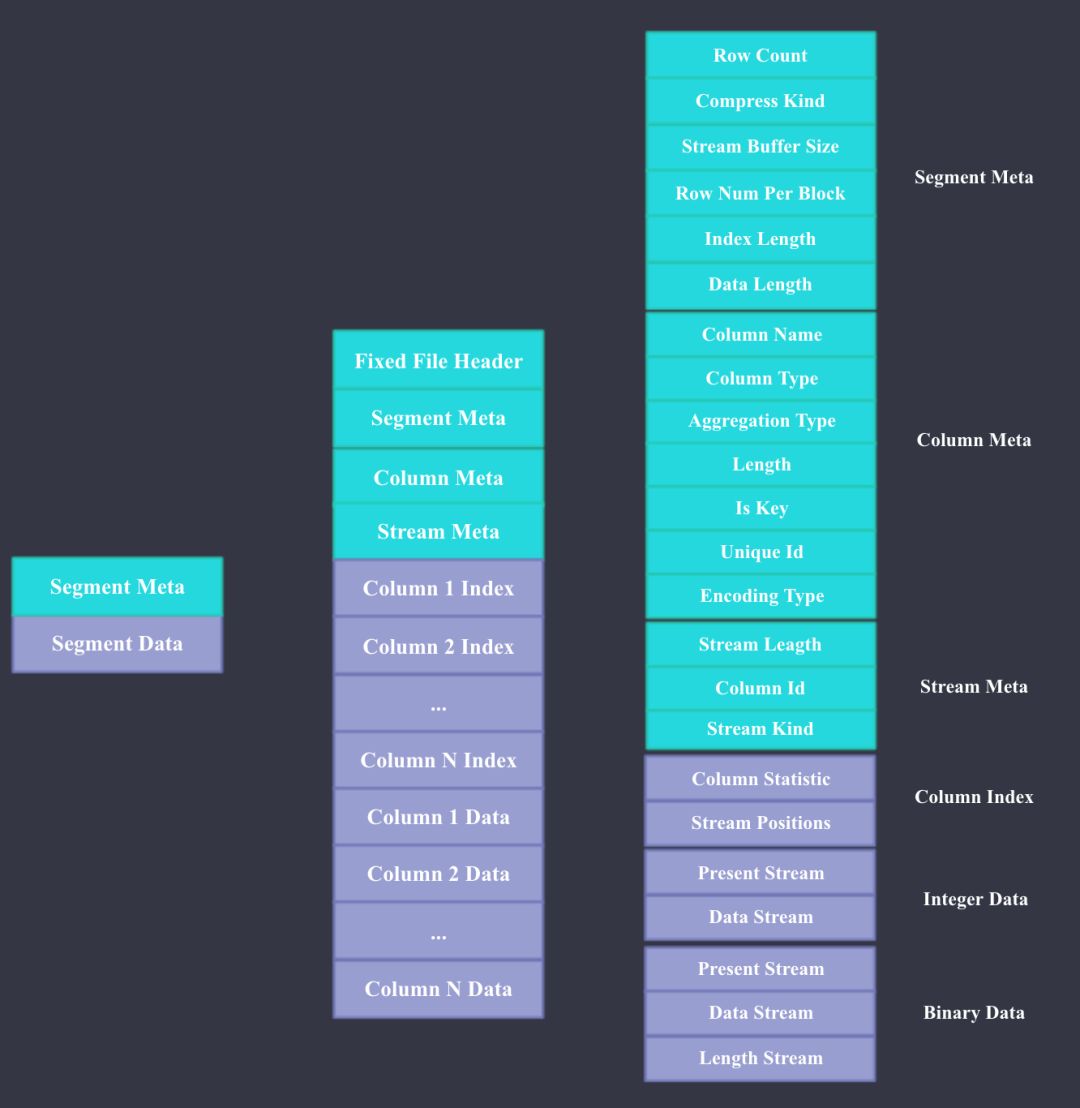
palo segment file
下面我们来看下 Palo Segment 文件的具体格式,Palo 文件格式主要参考了 Apache ORC。如上图所示,Palo 文件主要由 Meta 和 Data 两部分组成,Meta 主要包括文件本身的 Header,Segment Meta,Column Meta,和每个 Column 数据流的元数据,每部分的具体内容大家看图即可,比较详细。 Data 部分主要包含每一列的 Index 和 Data,这里的 Index 指每一列的 Min,Max 值和数据流 Stream 的 Position;Data 就是每一列具体的数据内容,Data 根据不同的数据类型会用不同的 Stream 来存储,Present Stream 代表每个 Value 是否是 Null,Data Stream 代表二进制数据流,Length Stream 代表非定长数据类型的长度。 下图是 String 使用字典编码和直接存储的 Stream 例子。
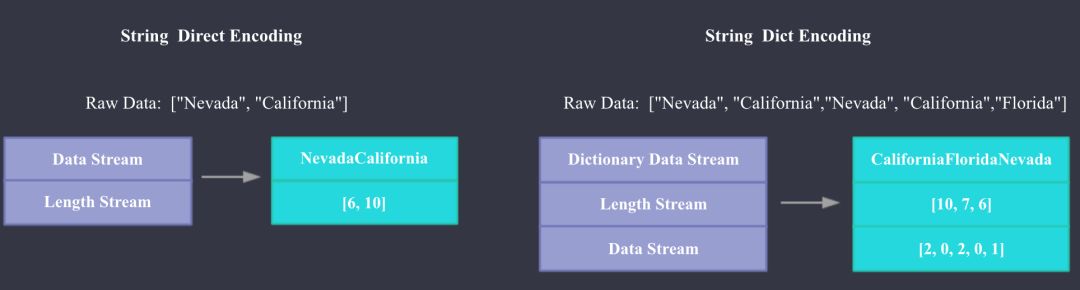
Palo String encoding
下面我们来看下 Palo 的前缀索引:

Palo index
本质上,Palo 的数据存储是类似 SSTable(Sorted String Table)的数据结构。该结构是一种有序的数据结构,可以按照指定的列有序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。前缀索引文件的格式如上图所示,索引的 Key 是每个 Rowblock 第一行记录的 Sort Key 的前 36 个字节,Value 是 Rowblock 在 Segment 文件的偏移量。
有了前缀索引后,我们查询特定 Key 的过程就是两次二分查找:
先加载 Index 文件,二分查找 Index 文件获取包含特定 Key 的 Row blocks 的 Offest, 然后从 Sement Files 中获取指定的 Rowblock;
在 Rowblocks 中二分查找特定的 Key
Kylin 数据导入:
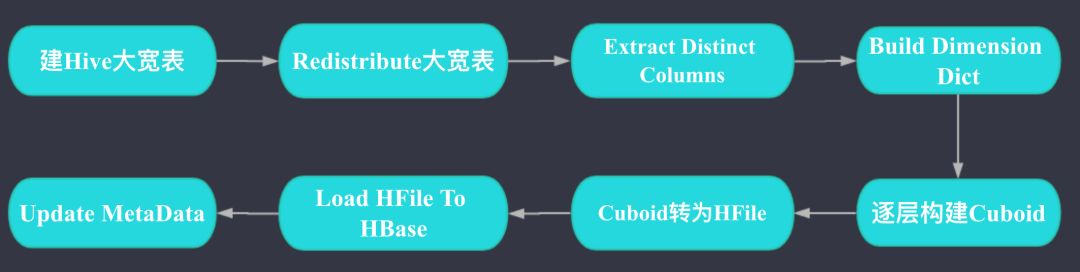
Kylin data loading
如上图,Kylin 数据导入主要分为建 Hive 大宽表 (这一步会处理 Join);维度列构建字典;逐层构建 Cuboid;Cuboid 转为 HFile;Load HFile To HBase; 元数据更新这几步。
其中 Redistribute 大宽表这一步的作用是为了将整个表的数据搞均匀,避免后续的步骤中有数据倾斜,Kylin 有配置可以跳过这一步。
其中 Extract Distinct Columns 这一步的作用是获取需要构建字典的维度列的 Distinct 值。假如一个 ID 维度列有 1,2,1,2,2,1,1,2 这 8 行,那么经过这一步后 ID 列的值就只有 1,2 两行,做这一步是为了下一步对维度列构建字典时更快速。
其他几个步骤都比较好理解,我就不再赘述。更详细的信息可以参考 Apache Kylin Cube 构建原理(https://blog.bcmeng.com/post/kylin-cube.html)
Palo 数据导入:
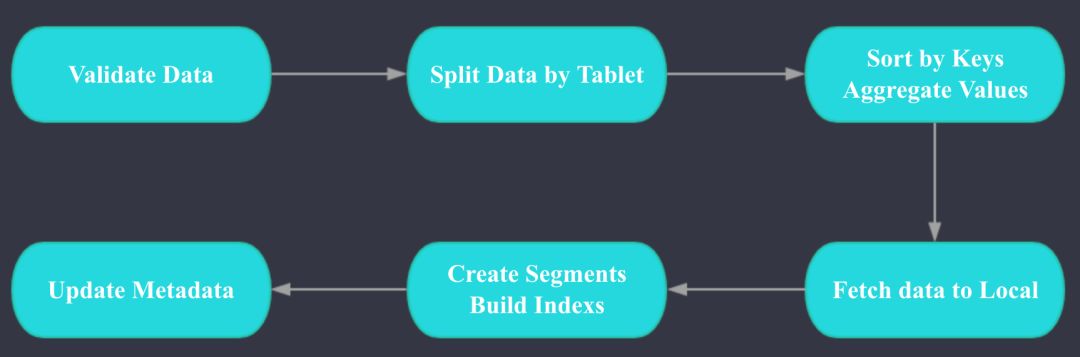
palo data loading
Palo 数据导入的两个核心阶段是 ETL 和 LOADING, ETL 阶段主要完成以下工作:
数据类型和格式的校验
根据 Teblet 拆分数据
按照 Key 列进行排序, 对 Value 进行聚合
LOADING 阶段主要完成以下工作:
每个 Tablet 对应的 BE 拉取排序好的数据
进行数据的格式转换,生成索引LOADING 完成后会进行元数据的更新。
Kylin 查询:
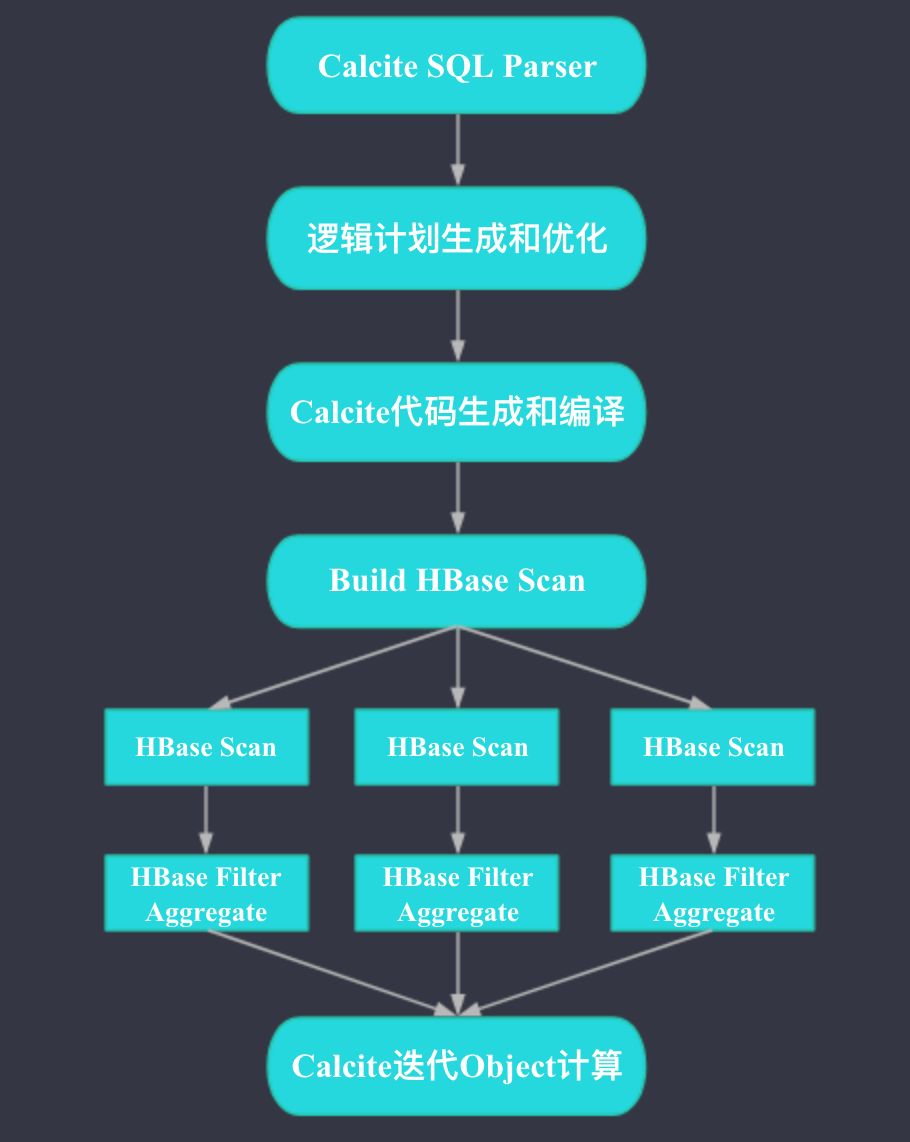
Kylin query
如上图,整个 Kylin 的查询过程比较简单,是个 Scatter-Gather 的模型。图中圆形框的内容发生在 Kylin QueryServer 端,方形框的内容发生在 HBase 端。Kylin QueryServer 端收到 SQL 后,会先进行 SQL 的解析,然后生成和优化 Plan,再根据 Plan 生成和编译代码,之后会根据 Plan 生成 HBase 的 Scan 请求,如果可能,HBase 端除了 Scan 之外,还会进行过滤和聚合(基于 HBase 的 Coprocessor 实现),Kylin 会将 HBase 端返回的结果进行合并,交给 Calcite 之前生成好的代码进行计算。
Palo 查询:
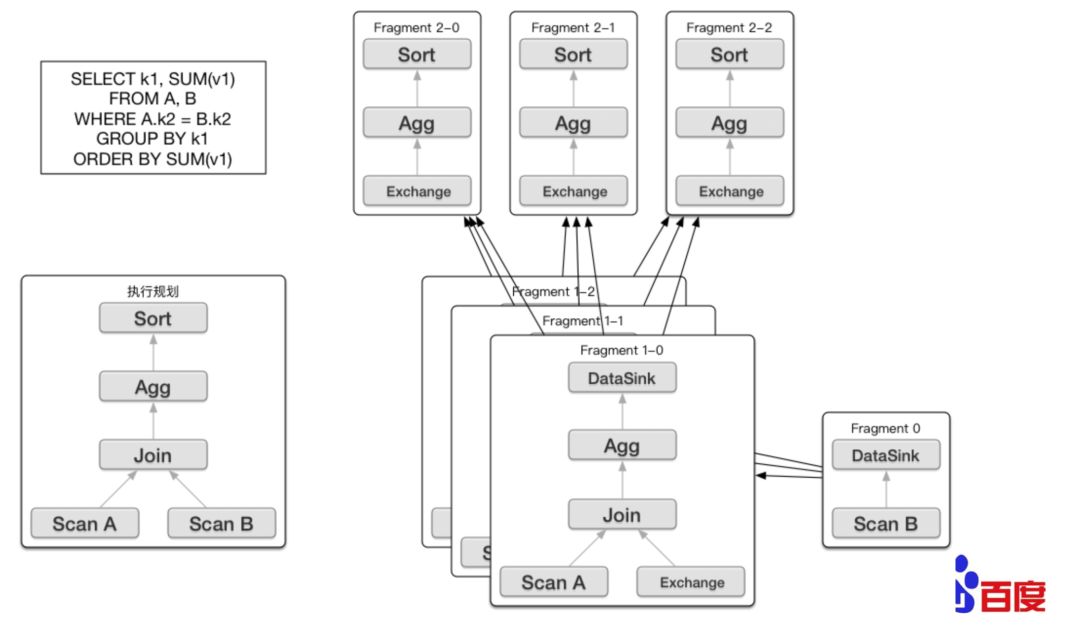
palo-impala-query
Palo 的查询引擎使用的是 Impala,是 MPP 架构。 Palo 的 FE 主要负责 SQL 的解析,语法分析,查询计划的生成和优化。查询计划的生成主要分为两步:
生成单节点查询计划 (上图左下角)
将单节点的查询计划分布式化,生成 PlanFragment(上图右半部分)
第一步主要包括 Plan Tree 的生成,谓词下推, Table Partitions pruning,Column projections,Cost-based 优化等;第二步 将单节点的查询计划分布式化,分布式化的目标是 最小化数据移动和最大化本地 Scan,分布式化的方法是增加 ExchangeNode,执行计划树会以 ExchangeNode 为边界拆分为 PlanFragment,1 个 PlanFragment 封装了在一台机器上对同一数据集的部分 PlanTree。如上图所示:各个 Fragment 的数据流转和最终的结果发送依赖:DataSink。
当 FE 生成好查询计划树后,BE 对应的各种 Plan Node(Scan, Join, Union, Aggregation, Sort 等)执行自己负责的操作即可。
Kylin 的精确去重:
Kylin 的精确去重是基于全局字典和 RoaringBitmap 实现的基于预计算的精确去重。具体可以参考 Apache Kylin 精确去重和全局字典权威指南(https://blog.bcmeng.com/post/kylin-distinct-count-global-dict.html)
Palo 的精确去重:
Palo 的精确去重是现场精确去重,Palo 计算精确去重时会拆分为两步:
按照所有的 group by 字段和精确去重的字段进行聚合
按照所有的 group by 字段进行聚合

下面是个简单的等价转换的例子:

Palo 现场精确去重计算性能和 去重列的基数、去重指标个数、过滤后的数据大小成负相关;
Kylin 的元数据 :
Kylin 的元数据是利用 HBase 存储的,可以很好地横向扩展。Kylin 每个具体的元数据都是一个 Json 文件,HBase 的 Rowkey 是文件名,Value 是 Json 文件的内容。Kylin 的元数据表设置了 IN_MEMORY => 'true' 属性, 元数据表会常驻 HBase RegionServer 的内存,所以元数据的查询性能很好,一般在几 ms 到几十 ms。
Kylin 元数据利用 HBase 存储的一个问题是,在 Kylin 可插拔架构下,即使我们实现了另一种存储引擎,我们也必须部署 HBase 来存储元数据,所以 Kylin 要真正做到存储引擎的可插拔,就必须实现一个独立的元数据存储。
Palo 的元数据:
Palo 的元数据是基于内存的,这样做的好处是性能很好且不需要额外的系统依赖。 缺点是单机的内存是有限的,扩展能力受限,但是根据 Palo 开发者的反馈,由于 Palo 本身的元数据不多,所以元数据本身占用的内存不是很多,目前用大内存的物理机,应该可以支撑数百台机器的 OLAP 集群。 此外,OLAP 系统和 HDFS 这种分布式存储系统不一样,我们部署多个集群的运维成本和 1 个集群区别不大。
关于 Palo 元数据的具体原理大家可以参考 Palo 官方文档 Palo 元数据设计文档(https://github.com/baidu/palo/wiki/Metadata-Design)
Why Kylin Query Fast:
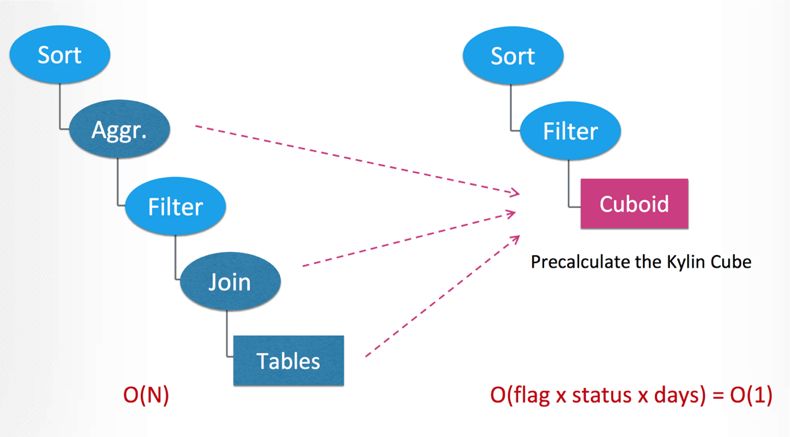
Kylin query
Kylin 查询快的核心原因就是预计算,如图 (图片出处 Apache kylin 2.0: from classic olap to real-time data warehouse https://www.slideshare.net/YangLi43/apache-kylin-20-from-classic-olap-to-realtime-data-warehouse),Kylin 现场查询时不需要 Join,也几乎不需要聚合,主要就是 Scan + Filter。
Why Palo Query Fast:
In-Memory Metadata。 Palo 的元数据就在内存中,元数据访问速度很快。
聚合模型可以在数据导入时进行预聚合。
和 Kylin 一样,也支持预计算的 RollUp Table。
MPP 的查询引擎。
向量化执行。相比 Kylin 中 Calcite 的代码生成,向量化执行在处理高并发的低延迟查询时性能更好,Kylin 的代码生成本身可能会花费几十 ms 甚至几百 ms。
列式存储 + 前缀索引。
Kylin 高可用:
Kylin JobServer 的高可用: Kylin 的 JobServer 是无状态的,一台 JobServer 挂掉后,其他 JobServer 会很快接管正在 Running 的 Job。JobServer 的高可用是基于 Zookeeper 实现的,具体可以参考 Apache Kylin Job 生成和调度详解(https://blog.bcmeng.com/post/kylin-job.html)。
Kylin QueryServer 的高可用:Kylin 的 QueryServer 也是无状态的,其高可用一般通过 nginx 这类的负载均衡组件来实现。
Kylin Hadoop 依赖的高可用: 要单纯保证 Kylin 自身组件的高可用并不困难,但是要保证 Kylin 整体数据导入和查询的高可用是 十分困难的,因为必须同时保证 HBase,Hive,Hive Metastore,Spark,Mapreduce,HDFS,Yarn,Zookeeper,Kerberos 这些服务的高可用。
Palo 高可用:
Palo FE 的高可用: Palo FE 的高可用主要基于 BerkeleyDB java version 实现,BDB-JE 实现了类 Paxos 一致性协议算法。
Palo BE 的高可用:Palo 会保证每个 Tablet 的多个副本分配到不同的 BE 上,所以一个 BE down 掉,不会影响查询的可用性。
Kylin 部署: 如果完全从零开始,你就需要部署 1 个 Hadoop 集群和 HBase 集群。 即使公司已经有了比较完整的 Hadoop 生态,在部署 Kylin 前,你也必须先部署 Hadoop 客户端,HBase 客户端,Hive 客户端,Spark 客户端。
Palo 部署: 直接启动 FE 和 BE。
Kylin 运维: 运维 Kylin 对 Admin 有较高的要求,首先必须了解 HBase,Hive,MapReduce,Spark,HDFS,Yarn 的原理;其次对 MapReduce Job 和 Spark Job 的问题排查和调优经验要丰富;然后必须掌握对 Cube 复杂调优的方法;最后出现问题时排查的链路较长,复杂度较高。
Palo 运维: Palo 只需要理解和掌握系统本身即可。
Kylin 客服: 需要向用户讲清 Hadoop 相关的一堆概念;需要教会用户 Kylin Web 的使用;需要教会用户如何进行 Cube 优化(没有统一,简洁的优化原则);需要教会用户怎么查看 MR 和 Spark 日志;需要教会用户怎么查询;
Palo 客服: 需要教会用户聚合模型,明细模型,前缀索引,RollUp 表这些概念。
Kylin 查询接入:Kylin 支持 Htpp,JDBC,ODBC 3 种查询方式。
Palo 查询接入: Palo 支持 mysql 协议,现有的大量 Mysql 工具都可以直接使用,用户的学习和迁移成本较低。
Kylin 学习成本: 用户要用好 Kylin,需要理解以下概念:
Cuboid
聚集组
强制维度
联合维度
层次维度
衍生维度
Extend Column
HBase RowKey 顺序
此外,前面提到过,用户还需要学会怎么看 Mapreduce Job 和 Spark Job 日志。
Palo 学习成本: 用户需要理解聚合模型,明细模型,前缀索引,RollUp 表这些概念。
Schema 在线变更是一个十分重要的 feature,因为在实际业务中,Schema 的变更会十分频繁。
Kylin Schema Change: Kylin 中用户对 Cube Schema 的任何改变,都需要在 Staging 环境重刷所有数据,然后切到 Prod 环境。整个过程周期很长,资源浪费比较严重。
Palo Schema Change:Palo 支持 Online Schema Change。
所谓的 Schema 在线变更就是指 Scheme 的变更不会影响数据的正常导入和查询,Palo 中的 Schema 在线变更有 3 种:
direct schema change:就是重刷全量数据,成本最高,和 kylin 的做法类似。当修改列的类型,稀疏索引中加一列时需要按照这种方法进行。
sorted schema change: 改变了列的排序方式,需对数据进行重新排序。例如删除排序列中的一列, 字段重排序。
linked schema change: 无需转换数据,直接完成。对于历史数据不会重刷,新摄入的数据都按照新的 Schema 处理,对于旧数据,新加列的值直接用对应数据类型的默认值填充。例如加列操作。Druid 也支持这种做法。
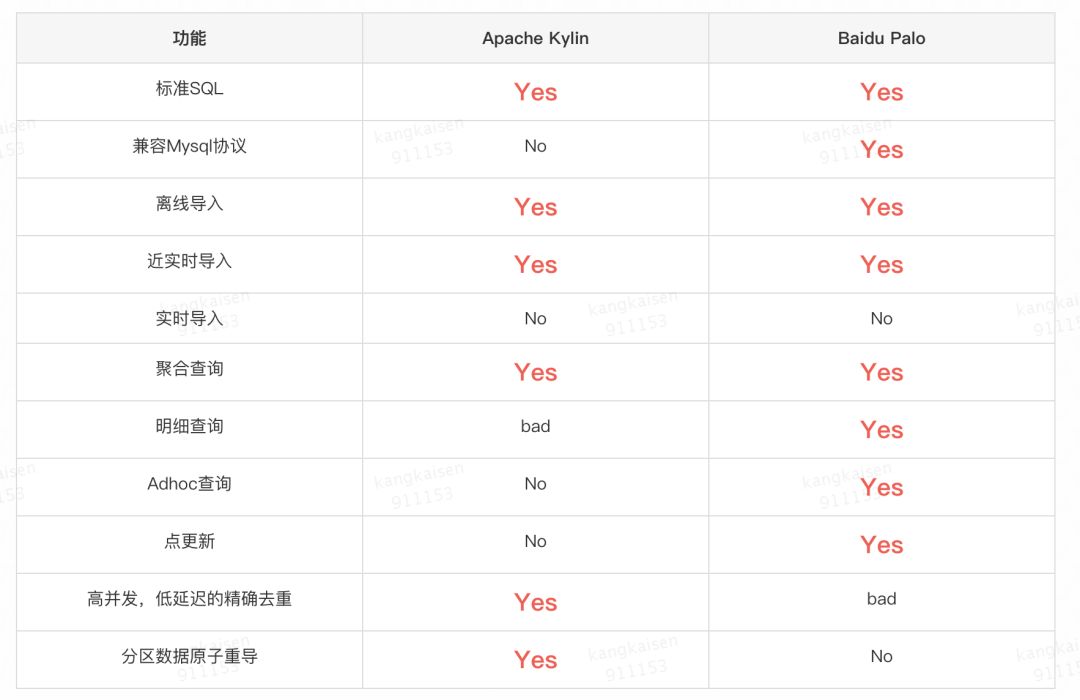
Apache kylin VS baidu palo
注: 关于 Kylin 的明细查询,Kylin 本身只有聚合模型,但是也可以 通过将所有列作为维度列,只构建 Base Cuboid 来实现明细查询, 缺点是效率比较低下。
注: 虽然 Palo 可以同时支持高并发,低延迟的 OLAP 查询和高吞吐的 Adhoc 查询,但显然这两类查询会相互影响。所以 Baidu 在实际应用中也是用两个集群分别满足 OLAP 查询和 Adhoc 查询需求。
Palo 社区刚刚起步,目前核心用户只有 Baidu;Kylin 的社区和生态已经比较成熟,Kylin 是第一个完全由中国开发者贡献的 Apache 顶级开源项目,目前已经在多家大型公司的生产环境中使用。
本文从多方面对比了 Apache Kylin 和 Baidu Palo,有理解错误的地方欢迎指正。本文更多的是对两个系统架构和原理的客观描述,主观判断较少。最近在调研了 Palo,ClickHouse,TiDB 之后,也一直在思考 OLAP 系统的发展趋势是怎样的,下一代更优秀的 OLAP 系统架构应该是怎样的,一个系统是否可以同时很好的支持 OLTP 和 OLAP,这些问题想清楚后我会再写篇文章描述下,当然,大家有好的想法,也欢迎直接 Comment。
1 Palo 文档和源码:https://github.com/baidu/palo
2 Kylin 源码:https://github.com/apache/kylin
3 Apache kylin 2.0: from classic olap to real-time data warehouse 在 Kylin 高性能部分引用了第 4 页 PPT 的截图:https://www.slideshare.net/YangLi43/apache-kylin-20-from-classic-olap-to-realtime-data-warehouse
4 百度 MPP 数据仓库 Palo 开源架构解读与应用 在 Palo 查询部分引用了第 31 页 PPT 的截图 https://myslide.cn/slides/6392
如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!
以上是关于OLAP系统解析:Apache Kylin和Baidu Palo哪家强?的主要内容,如果未能解决你的问题,请参考以下文章
卷皮OLAP平台进化史:Apache Kylin在卷皮网大数据平台的运用