卷皮OLAP平台进化史:Apache Kylin在卷皮网大数据平台的运用
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷皮OLAP平台进化史:Apache Kylin在卷皮网大数据平台的运用相关的知识,希望对你有一定的参考价值。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在开始案例分享前,先简单介绍一下“卷皮网”以及“卷皮网”的大数据团队“卷皮网”是一家专注高性价比商品的移动电商 ,日活跃高达 1000 多万“卷皮网”的大数据团队规模在 40 人左右,主要负责公司的底层数据仓库建设、OLAP 平台、报表系统等数据可视化工具,以及数据挖掘在搜索排序推荐上的应用、爬虫物流平台的建设、鹰眼风控系统、拨云日志系统等。
随着卷皮网的快速发展,数据规模快速增长,集群数据存储量成指数倍增大,服务器规模达到 100+ 台,与此同时公司的运营成员急剧增加,数据需求也随着业务的发展落地不断增长,如统计分析、运营报表、取数需求任务日益增大。为了节省取数工作的时间和人员开支,及时响应运营等部门同学数据需求的快速响应,我们于是开发了以自助数据分析为目标的 OLAP 平台。随着公司业务的日益扩增,平台经历了如下发展过程。
起初,数据规模较小,业务线比较简单,而且需求比较碎,故主要采取如下 ROLAP 引擎支撑:
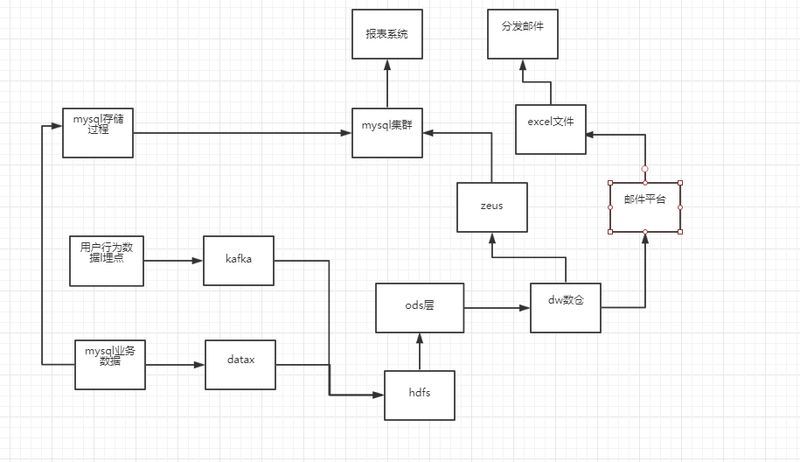
具体流程: 通过埋点采集用户行为数据,通过 Datax 和 Otter 同步数据到 Hive 集群和 mysql 集群,数据开发工程师通过 Etl 脚本 (Hive 脚本和 MySQL 存储过程) 两种方式将最终结果数据落地到 MySQL 数据库,最终呈现给业务方使用,还有一部分灵活定制的是通过邮件平台每日生成 Excel 附件,邮件推送给业务方
随着数据规模的增长和需求的增多,瓶颈逐渐显现。每个需求都要开发数据脚本,维度增加,开发周期拉长,同时需要耗费更多的人力,无法快速产出数据和响应需求变化。我们采用了 Saiku+Mondrian+Presto+Hive 的技术架构,通过分隔不同的业务线,最终生成若干个 Cube,提供给运营的同学使用,基本满足了业务方 90% 的数据需求。
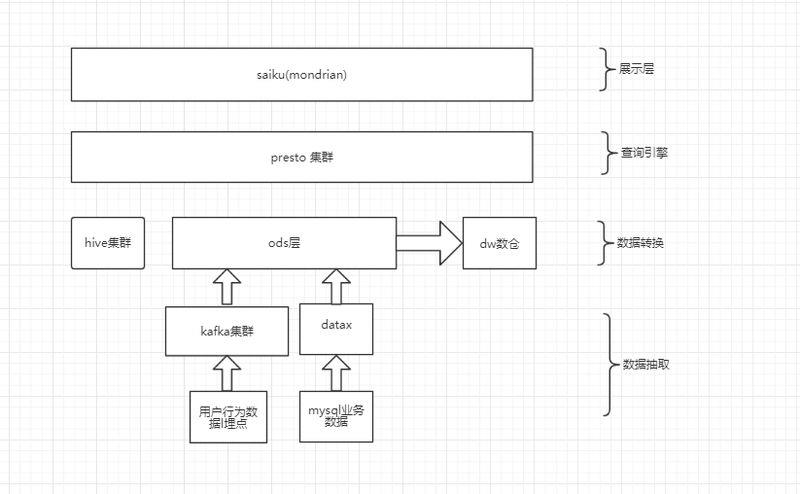
由于 Presto 是在线运算执行查询的,在日增上亿数据查询的时候,表现极为吃力。于是我们于 2016年 8 月份开始引入 Apache Kylin(以下简称 Kylin),将用户行为数据等超大规模数据迁移到 Kylin 上,同时大大缓解 Presto 集群的压力。
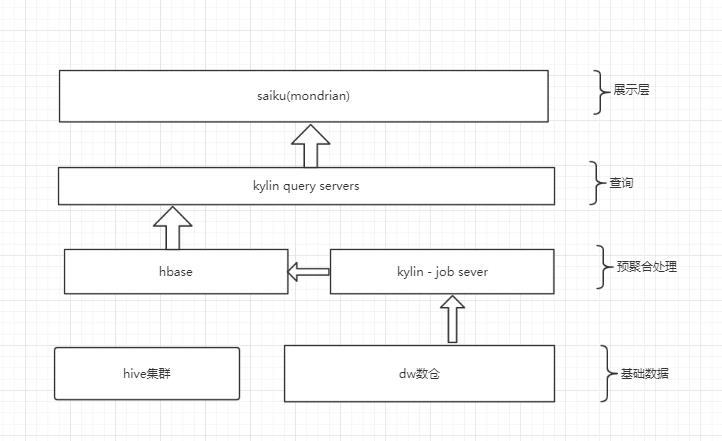
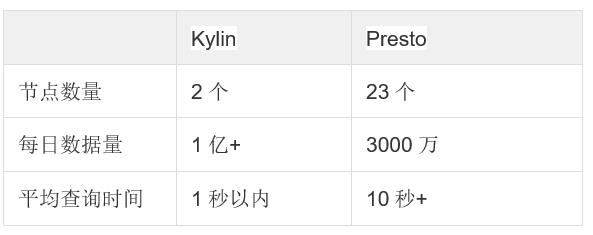
由于 Kylin 的基本原理是通过预计算实现空间换时间,Presto 需要在线查询源数据,所以 Kylin 的性能远远好于 Presto,Kylin 和 Presto 的查询性能对比。
该版本只支持星型模式,在 MR 上进行构建 Cube。起初我们根据业务线设计 Cube,其中最大的一个 Cube,维表 20+,其中包含若干高基数维,我们在预聚合的时候发现该 Cube 处理时间非常长,甚至造成内存溢出。于是我们对 Cube 进行了优化,以下是用到的一些优化手段:
1. 我们将该 Cube 根据业务细分成若干个 Cube, 同时对高基数维度做了优化
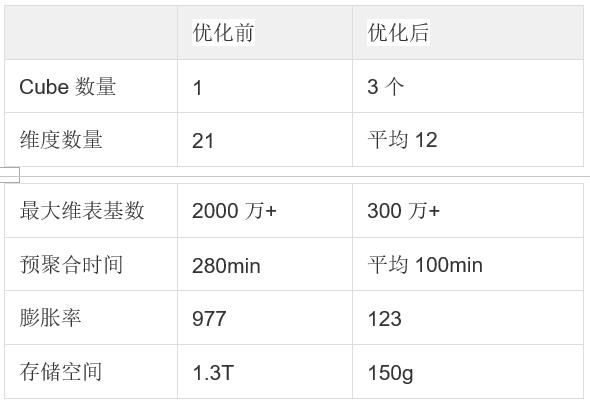
2. 使用了 Cube 构建的高级设置。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierarchy Dimension)和必要维度(Mandatory Dimension)等。基于这些设置,我们对拆分后的 Cube 进行了进一步的优化
(1) Mandatory Dimension
一般设置查询时经常使用的维度,我们使用了日期作为必需维度
(2)Hierarchy Dimension
如果维度关系有一定层级性、基数由小到大的情况可以使用层级维度。比如年月日,省市区,一级类目二级类目三级类目等等
(3)Joint Dimension
如果维度之间是同时出现的关系,即查询阶段,绝大部分情况都是同时出现的。可以使用 联合维度。
根据高级配置后,虽然牺牲了部分查询的查询性能,但是极大的优化了预聚合的性能。以下是优化之后的性能指标:
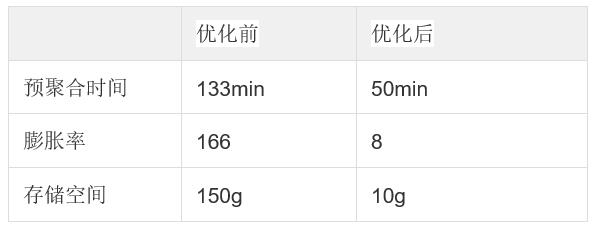
2017 年 4 月 30 号 Kylin v2.0 版本发布,不到三个月的时间,v2.1 版本正式发布。这两个版本主要有使用 Spark 做预聚合,支持雪花模型等新特性,对于我们解决 OLAP 预聚合慢的需求可以提供更多支持,并解决老版本的 Cube 构建时长、构建不稳定等问题。以下是 v1.6 版本和 v2.1 版本的一个对比:
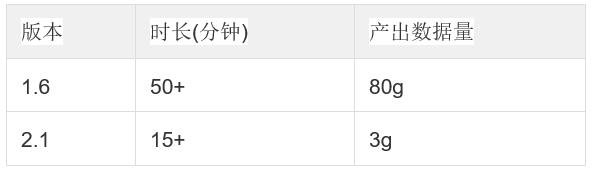
场景 1:新版本 MR 构建性能对比
事实事导入 2kw(2g) 测试数据, 使用 19 个维度 (维度基数在 1w 以下),6 个 Count Distinct(Bitmap),8 个普通指标,聚合方式:2^10 (无 Join Dimension, 无 Mandatory Dimensions),以 MR 引擎进行构建。
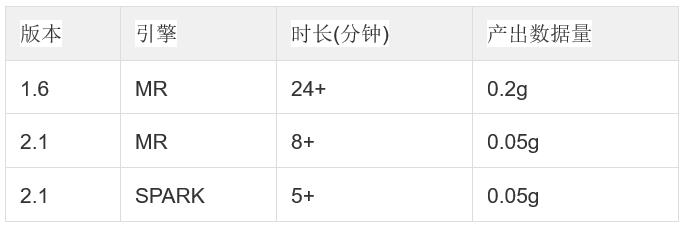
场景 2:Spark 构建性能以及 Join Dimension
事实事导入 1kw(1.4g) 测试数据, 使用 16 个维度 (维度基数在 1w 以下),4 个普通指标,聚合方式 : (2^3 + 2^4 + 2) (有 Join Dimension, 有 Mandatory Dimensions),以 Spark 和 MR 引擎分别进行构建。
场景 3:维表数量对性能的影响
事实事导入 3kw(3g) 测试数据, 使用 15 个维表,30+ 维度 (维度基数在 1w 以下),12 个 Count Distinct(bitmap),8 个普通指标,聚合方式:2^5 + 2^5 + 2^5 (有 Join Dimension, 无 Mandatory Dimensions),以 MR 引擎进行构建。
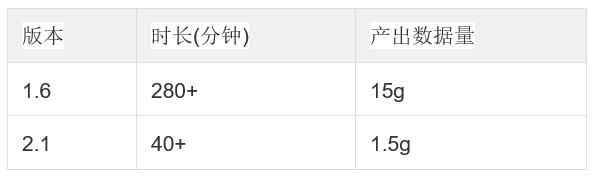
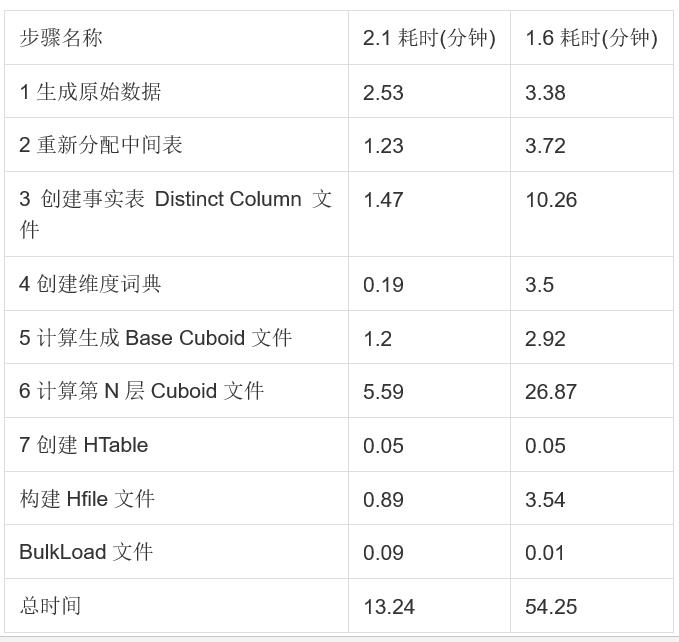
由于这两个版本的 MR 构建性能差异较大,单独对比各阶段的耗时,发现 v2.1 有了全面的提升。
我们的业务场景根据数据规模和业务复杂度来使用不同的技术框架。趋势如下:

数据业务需求可视化结构
曝光转化分析是对平台坑位的曝光点击率做多维分析的 Cube,日增数据量在数亿级别。用户画像分析是对基于平台所有用户的属性做多维分析的 Cube,日增数据在三千万左右。
以下我们成单路径分析为例做详细介绍:
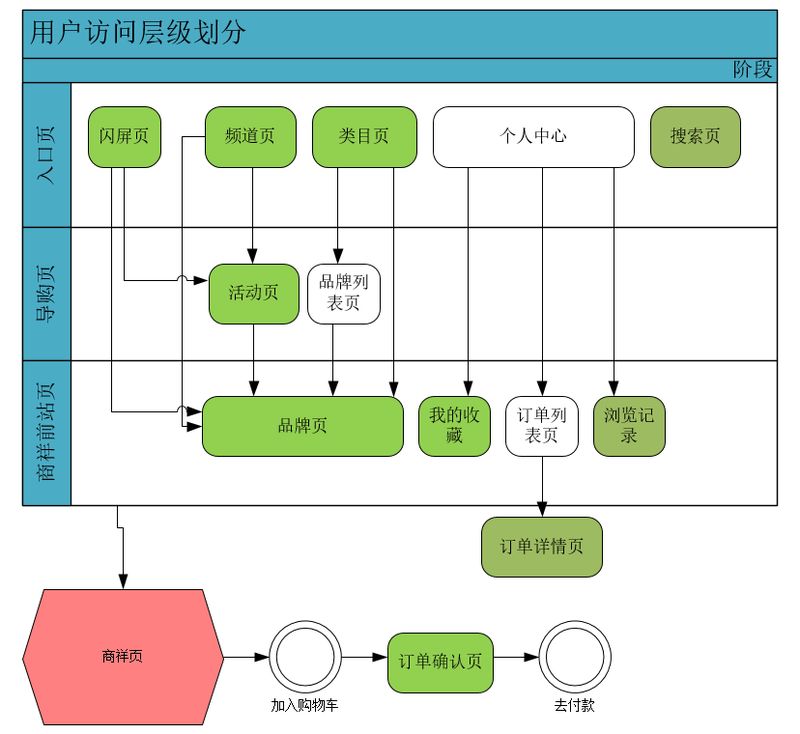
简介: 成单路径是围绕用户从浏览页面到最终下单到支付的整个生命周期的用户行为路径分析。采用的是归因算法。我们采用的归因方法是事先对我们平台的页面进行划分层级,用户在返回上一层级的时候重新覆盖。这样我们在计算最终转化率能达到,一个订单最终只归到一条下单路径,具体的页面划分层级如下:
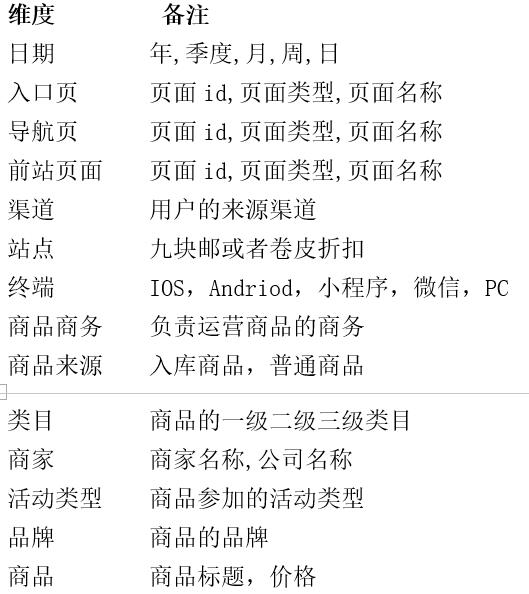
下表是成单路径的维度和指标说明
初期我们使用 Presto 来做成单路径分析,当时数据量日增还在 1 千万左右,90% 查询在 10 秒以内。随着公司用户规模的增长,行为数据呈指数级增加,数据高峰时期日增达到上亿级别,Presto 的查询显得有点力不从心,我们引进了 Kylin,大大得缓解了问题,90% 的查询的性能回归到 1 秒以内。后记:
卷皮 OLAP 一年多时间经历了三次重大的变革,目前平台采用 Presto 和 Kylin 两种引擎并用,事实表日增数量级在千万级别或以下,维表数多在 15 张以上最好采用 Presto,而事实表日增数量级在千万级别以上乃至上亿,维表数小于 15 个时候可以采用 Kylin。采用 Kylin 一定要将模型提前设计周全,不要频繁变更,因为每次模型变更数据都需要重刷,重新聚合,费时费力。
许湘楠, 毕业于武汉大学, 有多年的 WEB 系统开发经验,现就职于武汉奇米网络科技公司 (卷皮网), 担任大数据开发工程师,主要负责公司 OLAP 平台研发。
如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!
以上是关于卷皮OLAP平台进化史:Apache Kylin在卷皮网大数据平台的运用的主要内容,如果未能解决你的问题,请参考以下文章
Kylin系列-使用Saiku+Kylin构建多维分析OLAP平台
大数据分析平台Apache Kylin的部署(Cube构建使用)
OLAP系统解析:Apache Kylin和Baidu Palo哪家强?