优化 Apache Spark 以提升工作负载吞吐量
Posted 宝通集团
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化 Apache Spark 以提升工作负载吞吐量相关的知识,希望对你有一定的参考价值。
Apache Spark作为一种常见的数据处理引擎,可用于对超大数据集进行高级分析。Spark采用了一个通用的集群计算框架,能够获取和处理实时的超大数据流,即时处理和分析事件和异常情况,从而支持企业快速制定决策,更好地响应用户需求。
Spark作为类Hadoop Map Reduce的通用并行框架,拥有Hapdoop Map Reduce所具有的优点。目前,大多数Hadoop发行版中都包含了Spark。但是由于Spark本身的两大优势,使Spark在处理大数据时已经成为首选框架,超越了Hadoop 引入MapReduce范例。
简单比较一下Spark和Hadoop的区别。

|
|

|
|
|
对分布式存储的大数据进行处理的工具 |
一个分布式系统基础架构 |
||
|
分析和处理数据 |
存储、索引和追踪数据 |
||
|
交互式查询和优化迭代工作负载 |
独立完成数据的存储和计算工作 |
||
|
在内存中以接近“实时”的时间完成所有的数据分析 |
磁盘级计算,计算时需要在磁盘中读取数据 |
||
从以上对比我们可以发现,Spark的数据存储受到限制。
为了使Spark能够在运行不同工作负载(例如机器学习应用)时实现卓越性能,Spark内置了内存数据存储功能。因此,Spark的性能要明显优于其他大数据处理技术。但是,Spark内存功能受到服务器中可用内存的限制;受此影响,执行 Spark作业期间经常出现系统内存已经饱和,但计算资源却处于闲置状态的情况。要消除这种限制,一种办法为在节点集群上运行Spark的分布式架构,以充分利用所有节点中的可用内存。虽然采用更多节点可以解决服务器DRAM容量问题,但会增加成本。因为DRAM不仅成本高昂,而且还要求各企业配置额外的服务器以获得更多内存。
英特尔® IMDT助力Spark扩展系统内存
英特尔® IMDT(Intel® Memory Drive Technology)是一种软件定义内存(SDM)技术,与英特尔® 傲腾™ 固态盘相结合使用时,可有效扩展系统内存。这种英特尔® 傲腾™ 固态盘与英特尔® IMDT的结合,可以透明地为操作系统和Spark 作业提供更多内存,消除Spark应用所固有的内存限制。为了演示此功能,英特尔使用了一种当前名为TeraSort的 Spark性能指标评测程序。 该程序测试得出的初始数值显示,英特尔® IMDT能够有效提升资源利用率,改进系统性能。
Spark TeraSort性能指标评测
TeraSort是一种常见的性能指标评测程序,用于测量在特定计算机系统上对1TB随机分布数据进行排序所需的时间。它最初是一种用于测量 Apache Hadoop集群的 MapReduce性能的常用方法,并且有一些用于Spark的变体。在数据处理中,传入的数据必须先排序才能进行分析或处理,因此排序性能至关重要。而这也说明了该性能指标评测套件如此流行的原因所在。
系统配置
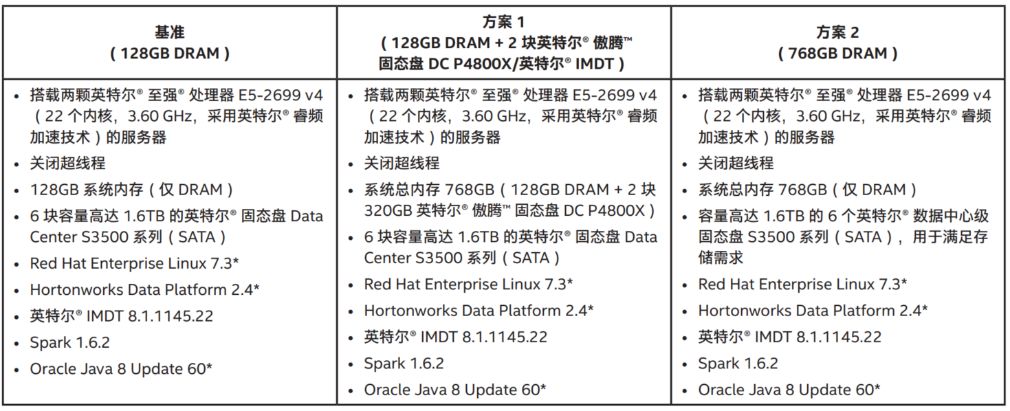
表1列出了测试的三个不同场景的系统配置。这三种配置包括:基准DRAM配置;基准配置加英特尔® IMDT,以增加内存容量;以及与仅增加DRAM的比较。
表 1:比较配置
测试方法
图1展示了软件堆栈的构成。Spark驱动器和执行器是JVM(Java虚拟机)进程。Spark执行器使用的内核和内存均可配置;在这些测试中,Spark驱动器的内存为7.5GB,Spark执行器的内存为21GB。

图 1:软件堆栈
Spark执行器进程包含两个部分:用户提交‘spark作业’和驱动器向执行器分配‘任务’,如图2所示。
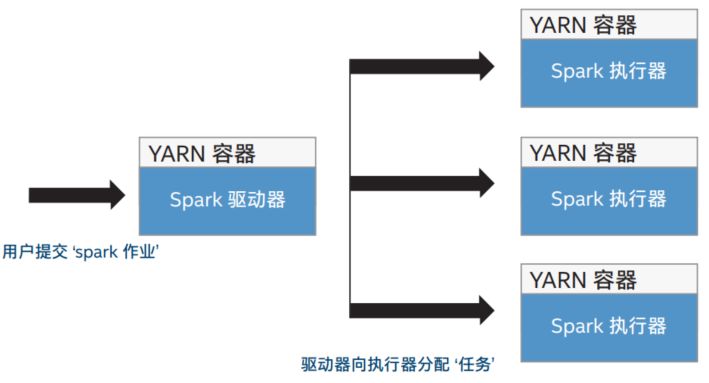
图 2:Spark 执行器进程
在Spark TeraSort性能指标评测的实验中,实验的排序数据共有4种大小:100GB、250GB、500GB和1TB。使用表1中给出的3种不同场景(128G DRAM、使用英特尔® IMDT的DRAM扩展和增加DRAM容量)的系统配置,在这4种排序数据(100GB、250GB、500GB和1TB)的上使用不同数量的执行器(4个执行器、8个执行器和8个执行器)来进行实验测评。执行器的数量与场景一一对应。
图 3:性能指标评测结果
这一内存扩展方法可通过使用英特尔® IMDT显著加大系统内存,同时通过运行更多的Spark执行器,充分利用系统计算容量。该性能指标评测程序表明,在具有相同内存和计算能力的系统上,通过添加英特尔® IMDT软件,可以将 Spark作业吞吐量提高一倍。相对于使用英特尔® IMDT,另一种方法是为系统添加更多DRAM。如图3的性能指标评测结果所示,添加更多DRAM只能略微提高性能,但成本却要显著高于英特尔® IMDT。
测试表明,通过在运行基于Spark的TeraSort工作负载的单个服务器节点上,使用英特尔® IMDT添加两块英特尔® 傲腾™ 固态盘DC P4800X,吞吐量提高了一倍,同时运行时间缩短了多达40%。而在向系统添加更多DRAM的方案中,性能相比于IMDT的方案略有提高。然而,要实现这一不到6%的性能提升,成本需要增加大约50%。
相比之下,英特尔® IMDT软件凭借更低的成本(在本文的比较中,成本大约是DRAM成本的一半),以及所能实现的更高容量(英特尔® IMDT可在双路节点中添加1280-3200GB的系统内存),在总体拥有成本方面明显具有更高的优势。
文章摘自英特尔精英汇
想购买及了解更多英特尔产品详情,欢迎咨询以下联系方式!
宝通集团联系方式
宝通官网:www.ex-channel.com
客户垂询邮箱:cuifang.mo@ex-channel.com
客户垂询QQ:1627678462
邮编:518026
以上是关于优化 Apache Spark 以提升工作负载吞吐量的主要内容,如果未能解决你的问题,请参考以下文章
优化采用英特尔® IMDT 技术的 Apache Spark*