工作经验分享:Spark调优优化后性能提升1200%
Posted About云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工作经验分享:Spark调优优化后性能提升1200%相关的知识,希望对你有一定的参考价值。
问题导读
1.本文遇到了什么问题?
2.遇到问题后,做了哪些分析?
3.本文解决倾斜使用哪些方法?
4.本次数据倾斜那种方法更有效?
5.解决性能优化问题的原理是什么?
优化后效果
1.业务处理中存在复杂的多表关联和计算逻辑(原始数据达百亿数量级)
2.优化后,spark计算性能提升了约12倍(6h-->30min)
3.最终,业务的性能瓶颈存在于ES写入(计算结果,ES索引document数约为21亿 pri.store.size约 300gb)
1. 背景
业务数据不断增大, Spark运行时间越来越长, 从最初的半小时到6个多小时
某日Spark程序运行6.5个小时后, 报“Too large frame...”的异常
org.apache.spark.shuffle.FetchFailedException: Too large frame: 2624680416
2. 原因分析
2.1. 抛出异常的原因
Spark uses custom frame decoder
(TransportFrameDecoder) which does not support frames larger than 2G.
This lead to fails when shuffling using large partitions.
根本原因: 源数据的某一列(或某几列)分布不均匀,当某个shuffle操作是根据此列数据进行shuffle时,就会造成整个数据集发生倾斜,即某些partition包含了大量数据,超出了2G的限制。
异常,就是发生在业务数据处理的最后一步left join操作
2.2. 粗暴的临时解决方法
增大partition数, 让partition中的数据量<2g
由于是left join触发了shuffle操作, 而spark默认join时的分区数为200(即spark.sql.shuffle.partitions=200), 所以增大这个分区数, 即调整该参数为800, 即spark.sql.shuffle.partitions=800
2.3. 解决效果
Spark不再报错,而且“艰难”的跑完了, 跑了近6个小时!
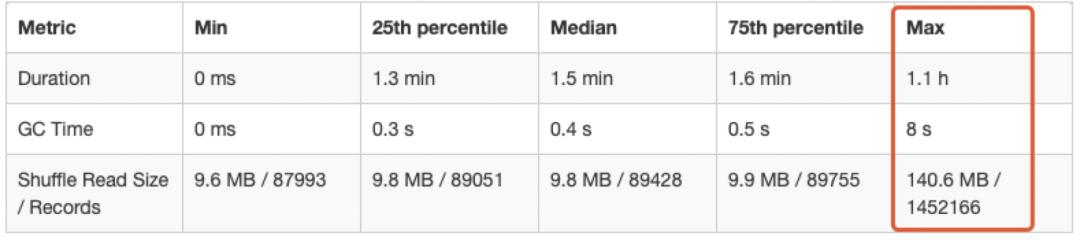
通过Spark UI页面的监控发现, 由于数据倾斜导致, 整个Spark任务的运行时间是被少数的几个Task“拖累的”
3. 思考优化
3.1. 确认数据倾斜
方法一: 通过sample算子对DataSet/DataFrame/RDD进行采样, 找出top n的key值及数量
方法二: 源数据/中间数据落到存储中(如HIVE), 直接查询观察
3.2. 可选方法
1.HIVE ETL 数据预处理
把数据倾斜提前到 HIVE ETL中, 避免Spark发生数据倾斜
这个其实很有用
2.过滤无效的数据 (where / filter)
NULL值数据
“脏数据”(非法数据)
业务无关的数据
3.分析join操作, 左右表的特征, 判断是否可以进行小表广播 broadcast
(1)这样可避免shuffle操作,特别是当大表特别大
(2)默认情况下, join时候, 如果表的数据量低于spark.sql.autoBroadcastJoinThreshold参数值时(默认值为10 MB), spark会自动进行broadcast, 但也可以通过强制手动指定广播
visitor_df.join(broadcast(campaign_df), Seq("random_bucket", "uuid", "time_range"), "left_outer")
业务数据量是100MB
(3)Driver上有一个campaign_df全量的副本, 每个Executor上也会有一个campaign_df的副本
(4)JOIN操作, Spark默认都会进行 merge_sort (也需要避免倾斜)
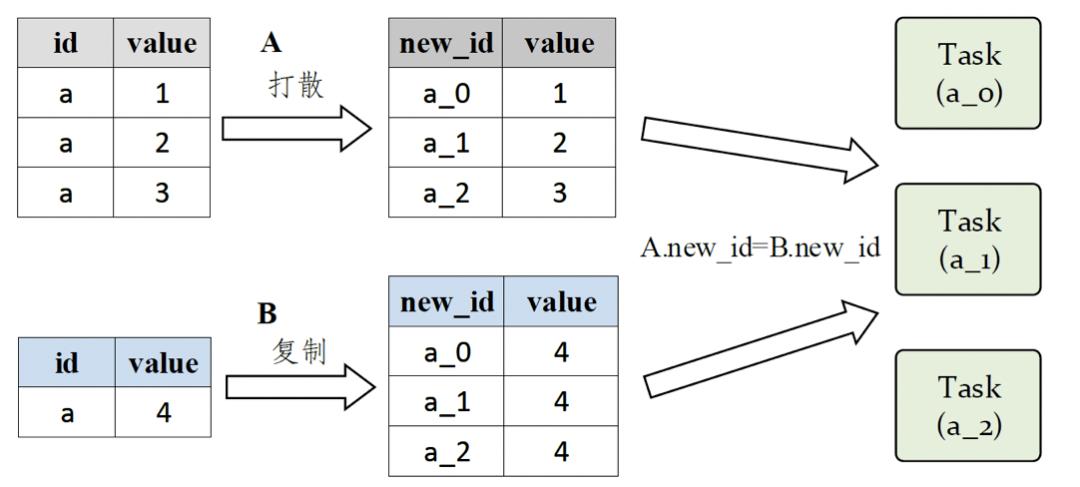
4.数据打散, 扩容join
分散倾斜的数据, 给key加上随机数前缀
A.join(B)
1.提高shuffle操作并行度
spark.sql.shuffle.partitions
2.多阶段
aggregate操作: 先局部聚合, 再全局聚合
给key打随机值, 如打上1-10, 先分别针对10个组做聚合
最后再统一聚合
join操作: 切成多个部分, 分开join, 最后union
判断出,造成数据倾斜的一些key值 (可通过观察或者sample取样)
如主号
单独拎出来上述key值的记录做join, 剩余记录再做join
独立做优化, 如broadcast
结果数据union即可
3.3. 实际采用的方法
HIVE 预处理
过滤无效的数据
broadcast
打散 --> 随机数
shuffle 并行度
Example:
......
visitor_leads_fans_df.repartition($"random_index")
.join(broadcast(campaign_df), Seq("random_bucket", "uuid", "time_range"), "left_outer")
.drop("random_bucket", "random_index")
......
复制代码原文链接
https://cloud.tencent.com/developer/article/1621351
----------------------------END----------------------------
【1】
【2】
【3】
【4】
【5】
【6】
【7】
【8】
以上是关于工作经验分享:Spark调优优化后性能提升1200%的主要内容,如果未能解决你的问题,请参考以下文章