.NET Core接入ElasticSearch 7.5
Posted DotNet技术平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET Core接入ElasticSearch 7.5相关的知识,希望对你有一定的参考价值。
写在前面
最近一段时间,团队在升级ElasticSearch(以下简称ES),从ES 2.2升级到ES 7.5。也是这段时间,我从零开始,逐步的了解了ES,中间也踩了不少坑,所以特地梳理和总结一下相关的技术点。
❝ES小趣闻:
多年前,一个叫做Shay Banon的刚结婚不久的开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始使用Lucene进行尝试。直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。Shay的妻子依旧等待着她的食谱搜索……
❞
由此看见,一个成功的男人背后总是站着一个女人,所以程序员们要早点找到对象,可程序员找到女朋友又谈何容易,程序猿注定悲伤-_-||。
ElasticSearch前期准备
EElasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,ES底层基于开源库Apache Lucene,不过Lucene使用门槛太高,ES隐藏了Lucene使用时的复杂性,使得分布式实时文档搜索、实时分析引擎、高扩展性变得更加容易。
安装
安装ES,首先要配置Java SDK,然后配置一下环境变量即可。然后再从官网下载ES安装包,可以选用默认配置,点击下一步—>安装。
在浏览器上输入http://localhost:9200/,显示如下文本,就意味着安装成功了。
❝{
"name" : "XXXXXXXXXX",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "mB04ov3OTvSz7OSe0GtZ_A",
"version" : {
"number" : "7.5.2",
"build_flavor" : "unknown",
"build_type" : "unknown",
"build_hash" : "8bec50e1e0ad29dad5653712cf3bb580cd1afcdf",
"build_date" : "2020-01-15T12:11:52.313576Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
❞
部分基本概念
节点 & 集群
集群由多个节点组成,其中一个节点为主节点,主节点由内部选举算法选举产生。当然主节点是相对的,是相对于内部而言的。ES去中心化,这是相对于外部而言的,从逻辑上说,与任何一个节点的的通信和与集群通信是没有区别的。如下图所示。
索引
索引保存相关数据的地方,是指向一个或者多个物理分片的逻辑命名空间 。另外,每个Index的名字必须是小写。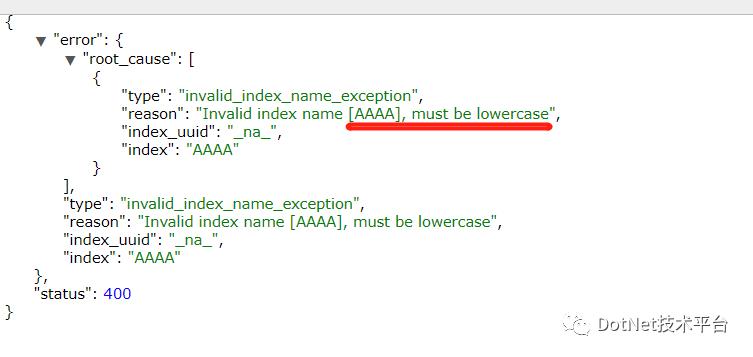
文档
Document的核心元数据有三个:_index、_type(7.X已经弱化了,8.0开始就会移除)、_id。Document 使用 JSON 格式表示。
分片
一个分片是一个底层的工作单元,它仅保存了全部数据中的一部分。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是主分片或者副本分片。索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
理论上一个主分片最大能够存储Integer.MAX_VALUE^128 个文档。
写操作探讨
文档会被保存到主分片,那么在多个分片的情况下是如何写入和精确搜索的。实际上这是通过以下公式确定的:
shard = hash(routing) % number_of_primary_shards
以上的routing的值是一个任意的字符串,它默认被设置成文档的_id字段,但是也可以被设置成其他指定的值。这个routing字符串会被传入到一个哈希函数(Hash Function)来得到一个数字,然后该数字会和索引中的主要分片数进行模运算来得到余数。这个余数的范围应该总是在0和number_of_primary_shards - 1之间,它就是一份文档被存储到的分片的号码。
这就解释了为什么索引中的主要分片数量只能在索引创建时被指定,并且将来都不能在被更改:如果主要分片数量在索引创建后改变了,那么之前的所有路由结果都会变地不正确,从而导致文档不能被正确地获取。那么如何水平扩展呢,可以移步Designing for scale。
所有的文档API(get, index, delete, bulk, update)都接受一个routing参数,它用来定制从文档到分片的映射。一个特定的routing值能够确保所有相关文档 - 比如属于相同用户的所有文档 - 都会被存储在相同的分片上。
写操作原理图: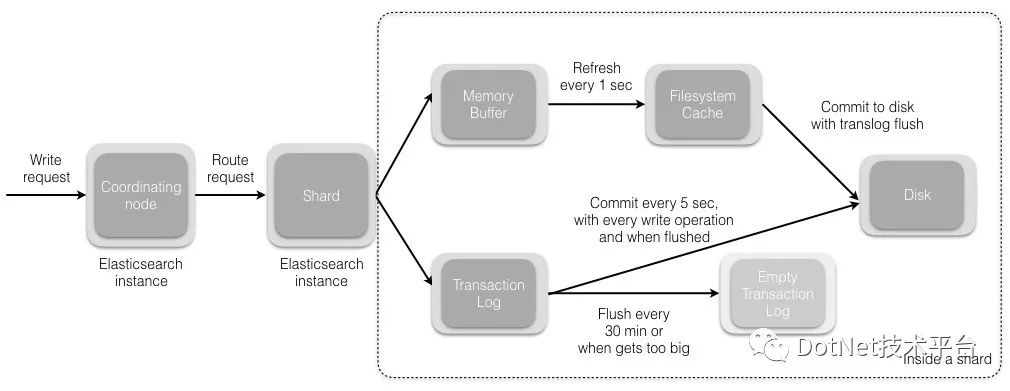 写入的请求流程如图所示(此图源自《Elasticsearch权威指南》):
写入的请求流程如图所示(此图源自《Elasticsearch权威指南》):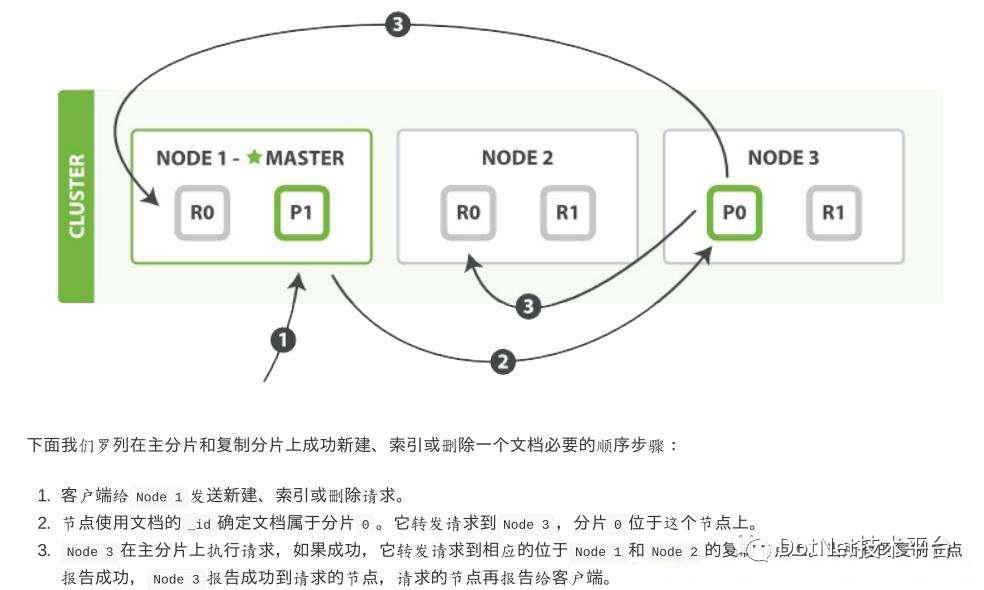 写入到磁盘流程如下图所示:
写入到磁盘流程如下图所示: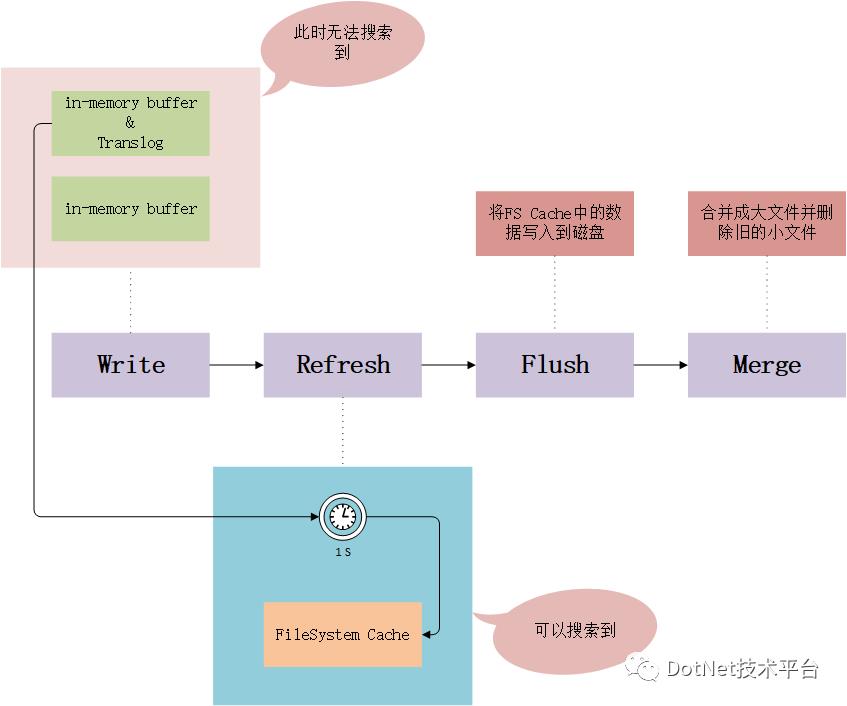 由此可见ES的实时并非是完全的实时,而是一种准实时(Near-Real-Time)。
由此可见ES的实时并非是完全的实时,而是一种准实时(Near-Real-Time)。
读操作探讨
读操作分为两个阶段,查询阶段(Query Phrase)以及聚合提取阶段(Fetch Phrase)。
查询阶段
协调节点接受到读请求,并将请求分配到相应的分片上(有可能是主分片或是副本分片,这个机制后续会提及),默认情况下,每个分片创建10个结果(仅包含 document_id 和 Scores)的优先级队列,并以相关性排序,返回给协调节点。
❝查询阶段如果不特殊指定,落入的分片有可能是 primary 也有可能是 replicas,这个根据协调节点的负载均衡算法来确定。
❞
聚合提取阶段
假设查询落入的分片数为 N,那么聚合阶段就是对 N*10 个结果集进行排序,然后再通过已经拿到的 document_id 查到对应的 document 并组装到队列里,组装完毕后将有序的数据返回给客户端。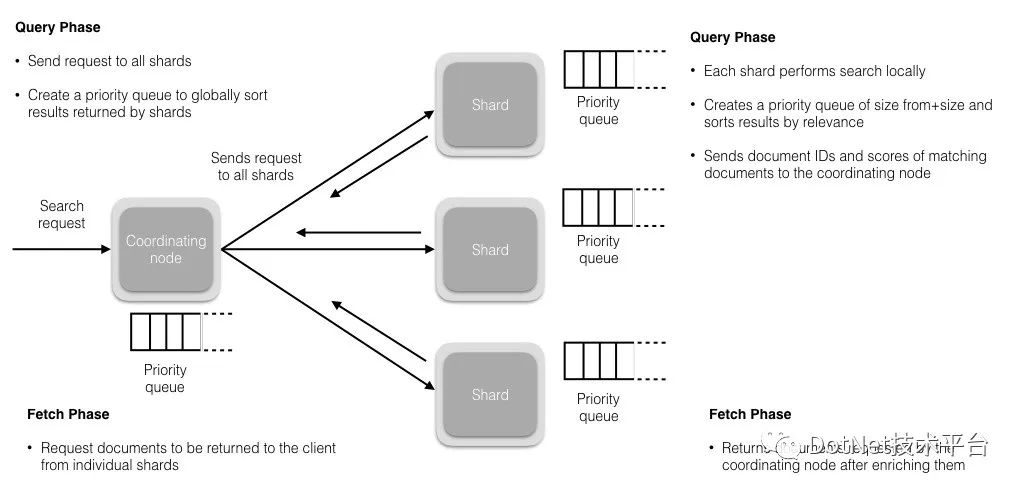
-
客户端发送请求到任意一个Node,成为Coordinating node -
Coordinating node对Document进行路由,将请求转发到对应的Node上,此时会使用Round-Robin随机轮询算法,在Primary Shard以及其所有Replica中随机选择一个,让读请求负载均衡 -
接收请求的node返回Document给Coordinating node -
Coordinating node返回Document给客户端
ElasticSearch实战
ES在.NET平台上的官方客户端是NEST,以下操作都是基于该package的。
常用操作
以下操作均基于ES-Head,该工具是一个Chrome插件,非常简单实用,而且可以在GitHub上搜到源码,方便个性化开发。
写入数据
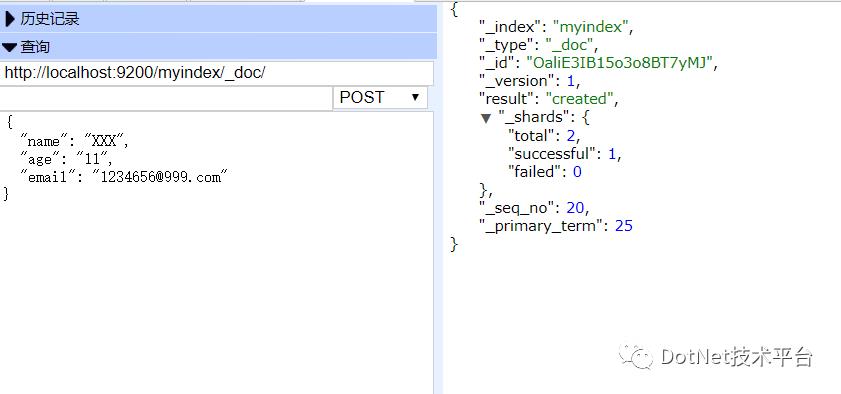 返回的数据中,可以看到Id是一段字符串,这是因为在写入的过程中并没有指定,所以会由ES默认生成。当然可以指定:
返回的数据中,可以看到Id是一段字符串,这是因为在写入的过程中并没有指定,所以会由ES默认生成。当然可以指定: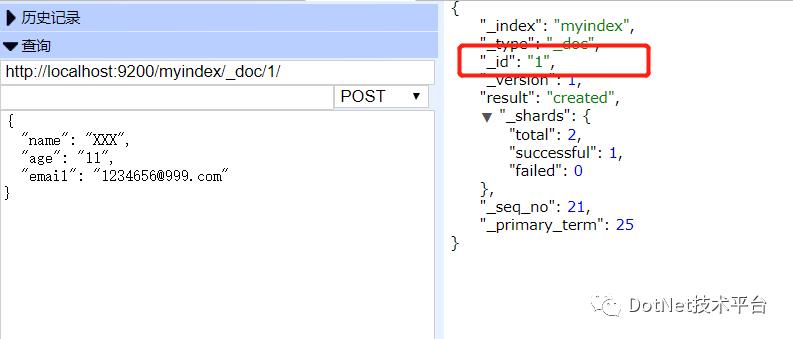
更新数据
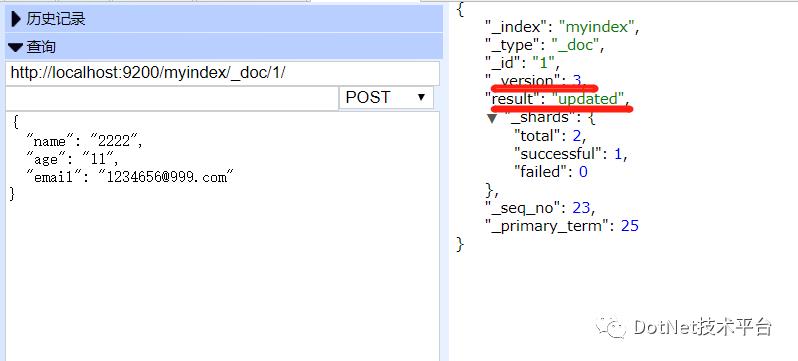 _version值会随着操作次数,逐渐迭代。
_version值会随着操作次数,逐渐迭代。
删除数据
查询操作:
项目升级过程中遇到的问题
分页查询过慢
初次的查询使用了深度分页(from-size)查询,当数据达到百万千万级别时,已经慢的让人忍无可忍。所谓深度查询就是涉及到大量 shard 的查询时,直接跳页到几千甚至上万页的数据,协调节点就有宕机的风险,毕竟协调节点需要将大量数据汇总起来进行排序,耗费大量的内存和 CPU 资源。所以慎用!尽可能用 Scroll API ,即只允许拿到下一页的信息,不允许跳页的情况出现,会避免这种情况的发生。
后来改用了快照分页(scroll),整个查询过程非常稳定,方差几乎可以忽略。该查询会自动返回一个_scroll_id,通过这个id(经过base64编码)可以继续查询。查询语句如下:http://localhost:9200/_search/scroll?scroll=1m&scroll_id=c2MkjsjskMkkssllasKKKOzM0NDg1ODpksksks5566HHsaskLLLqi692215。这个语句虽然很快,但是无法做到跳页查询,只能一页一页的查询。
快照分页参考代码如下:
❝var searchResponse = client.Search
(p => p.Query(t =>
t.Bool(l => l.Filter(f => f.DateRange(m => m.GreaterThanOrEquals(startTime).Field(d => d.PostDate)))))
.From(0)
.Size(Configurations.SyncSize)
.Index("archive")
.Sort(s => s.Ascending(a => a.PostDate)).Scroll("60s"));while(某条件)
{
searchResponse = client.Scroll<ElasticsearchTransaction>("60s", searchResponse.ScrollId);
//跳出循环的条件}
❞
模糊查询
该场景涉及到多个字段的模糊查询,当然,这种查询是十分消耗效率的,使用的时候要慎重,同时还要控制模糊关键字的数量,以尽可能在满足业务的情况下,提升查询效率,参考代码如下:
❝public static List<IHit
> GetDataByFuzzy(ElasticClient client920>0) { string[] fieldList =
{
"filed1",
"filed2",
"filed3",
"filed4",
"filed5",
"filed6",
"filed7",
"filed8",
"filed9"
};
string term = string.Concat("*", string.Join("* *", "i u a n".Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries)), "*");
var result = client9200.Search<TModel>(p => p.Query(q => q.Bool(b=>b.Must(t=>t.QueryString(c => c
.Fields(fieldList)
.Query(term)
.Boost(1.1)
.Fuzziness(Fuzziness.Auto)
.MinimumShouldMatch(2)
.FuzzyRewrite(MultiTermQueryRewrite.ConstantScoreBoolean)
.TieBreaker(1)
.Lenient()
)).Filter(f=>
f.Term(t=>
t.Field(d=>d.AccountKey).Value("123456789")))))
.ScriptFields(sf => sf.ScriptField("datetime1",
sc => sc.Source("doc['datetime1'].value == null?doc['datetime2'].value: doc['datetime1'].value")))
.Source(true)
.Index("archive")
.From(0)
.Size(10000)
.Sort(s => s.Descending(a => a.CreateDate)));
return result.Hits.Select(p=>p.Source).ToList();}
❞
关于排序
在本次的ES优化升级过程中,关于排序的操作可以说是很纠结的。按照业务要求,要根据两个时间类型的字段进行排序,如果某个为空,就按照不为空的排序,使得其排序结果达到穿插的效果,而不是像SQL语句那样order field1, field2的排序结果那样。
找出解决方案的过程很痛苦,因为官方的demo无法运行,经过多方尝试,终于在查看ElasticSearch源代码的情况下,找到了解决方案。
查询语句如下:
❝{
"from": 0,
"query": {
"bool": {
"filter": [
{
"term": {
"UserId": {
"value": "123456789"
}
}
}
]
}
},
"size": 10,
"sort": [
{
"_script": {
"script": {
"source": "doc.DateTime1.empty?doc.DateTime2.value.toInstant().toEpochMilli():doc.DateTime1.value.toInstant().toEpochMilli()"
},
"type": "number",
"order": "desc"
}
}
]}
❞
C#参考代码如下:
❝var searchResponse = _elasticsearchClient.Search
(s => s ❞.Query(q => q.Bool(b => b
.Filter(m => m.Term(t => t.Field(f => f.UserId).Value(userId)),m => m.QueryString(qs => qs.Fields(fieldList).Query(term.PreProcessQueryString())))))
.Index(indexName)
.ScriptFields(sf => sf
.Source(true)
.Sort(s=>s.Script(sr=>sr.Script(doc => doc.Source("doc.DateTime1.empty ? doc.DateTime2.value.toInstant().toEpochMilli() : doc.DateTime1.value.toInstant().toEpochMilli()"))))
.From(startIndex)
.Size(pageSize));
参考链接:
https://www.dazhuanlan.com/2020/02/13/5e44f118b75cb/ https://www.toutiao.com/i6824365055832752653
以上是关于.NET Core接入ElasticSearch 7.5的主要内容,如果未能解决你的问题,请参考以下文章
.net core 与ELK安装Elasticsearch可视化工具
.net core使用NLog+Elasticsearch记录日志
十四.net core(.NET 6)搭建ElasticSearch(ES)系列之给ElasticSearch添加SQL插件和浏览器插件