强化学习常用算法+实际应用 ,必须get这些核心要点!
Posted 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习常用算法+实际应用 ,必须get这些核心要点!相关的知识,希望对你有一定的参考价值。
本文约1700字,建议阅读5分钟
本文为你介绍强化学习最常用的算法。
[ 导读 ]强化学习(RL)是现代人工智能领域中最热门的研究主题之一,其普及度还在不断增长。本文介绍了开始学习RL需要了解的核心要素。戳右边链接上 新智元小程序 了解更多!
强化学习是现代人工智能领域中最热门的研究主题之一,其普及度还在不断增长。
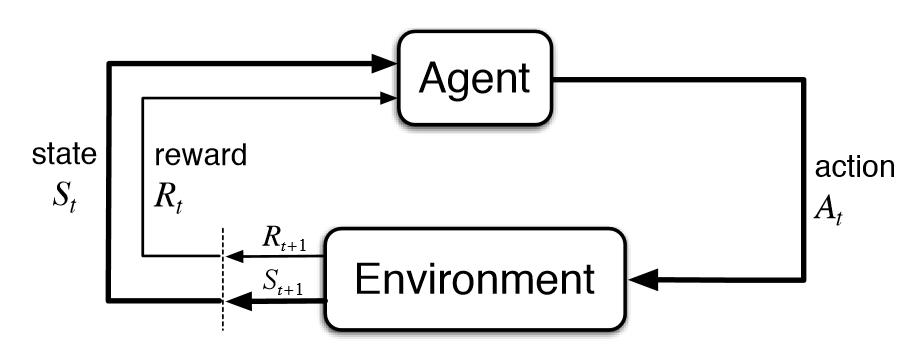
强化学习是一种机器学习技术,它使代理能够使用自身行为和经验的反馈通过反复试验在交互式环境中学习。
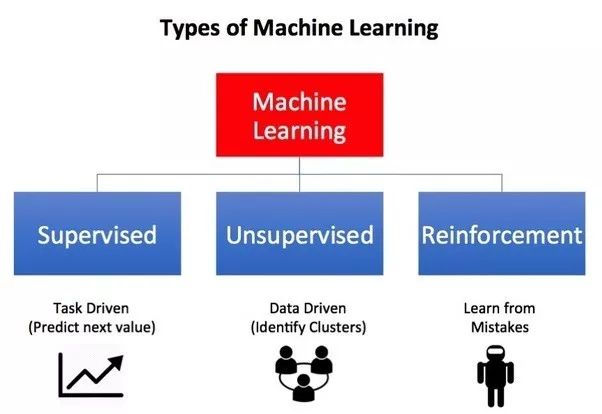
尽管监督学习和强化学习都使用输入和输出之间的映射,但监督学习提供给智能体的反馈是执行任务的正确动作集,而强化学习则将奖惩作为正面和负面行为的信号。
无监督学习在目标方面有所不同。无监督学习的目标是发现数据点之间的相似点和差异,而在强化学习的情况下,目标是找到合适的行为模型,以最大化智能体的总累积奖励。
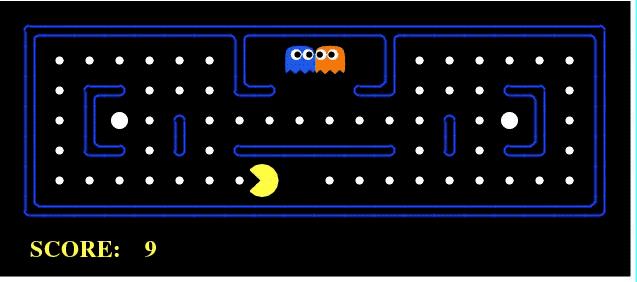
强化学习问题可以通过游戏来最好地解释。让我们以吃豆人游戏为例,智能体(PacMan)的目标是在网格中吃掉食物,同时避开途中出现的鬼魂。
在这种情况下,网格世界是智能体所作用的交互式环境。智能体成功迟到豆豆会得到奖励,如果智能体被幽灵杀死(输掉了游戏)则会被惩罚。
状态值得是智能体在网格世界中的位置,总累积奖励是赢得比赛。
为了建立最优政策,智能体面临探索新状态的困境,同时又要使其整体收益最大化,这称为“探索与开发”的权衡。
为了平衡两者,最佳的整体策略可能涉及短期牺牲。因此,智能体应该收集足够的信息,以便将来做出最佳的总体决策。
马尔可夫决策过程(MDP)是描述强化学习环境的数学框架,几乎所有强化学习问题都可以使用MDP来表述。
一个MDP由一组有限的环境状态S,在每种状态下的一组可能的动作A,一个实值奖励函数R和一个过渡模型P(s’,s | a)组成。
但是,现实环境更可能缺少任何有关环境动力学的先验知识。在这种情况下,无模型强化学习方法非常有用。
Q学习是一种常用的无模型方法,可用于构建自己玩的PacMan智能体。它围绕更新Q值的概念展开,Q值表示在状态s中执行动作a的值。以下值更新规则是Q学习算法的核心。
Q学习和SARSA(状态-行动-奖励-状态-行动)是两种常用的无模型强化学习算法。它们的勘探策略不同,而利用策略却相似。
Q-学习是强化学习的一种方法。Q-学习就是要记录下学习过的政策,因而告诉智能体什么情况下采取什么行动会有最大的奖励值。Q-学习不需要对环境进行建模,即使是对带有随机因素的转移函数或者奖励函数也不需要进行特别的改动就可以进行。
对于任何有限的马可夫决策过程(FMDP),Q-学习可以找到一个可以最大化所有步骤的奖励期望的策略,在给定一个部分随机的策略和无限的探索时间,Q-学习可以给出一个最佳的动作选择策略。“Q”这个字母在强化学习中表示一个动作的品质(quality)。
而SARSA是一种策略上方法,在其中根据其当前操作a得出的值来学习值。这两种方法易于实现,但缺乏通用性,因为它们无法估计未知状态的值,这可以通过更高级的算法来克服,例如使用神经网络来估计Q值的Deep Q-Networks(DQNs)。但是DQN只能处理离散的低维操作空间。
深度确定性策略梯度(DDPG)是一种无模型,脱离策略,actor-critic的算法,它通过在高维连续操作空间中学习策略来解决此问题。下图是actor-critic体系结构的表示。
由于强化学习需要大量数据,因此它最适用于容易获得模拟数据的领域,例如游戏性,机器人技术。
强化学习被广泛用于构建用于玩计算机游戏的AI。AlphaGo Zero是第一个在古代中国的围棋游戏中击败世界冠军的计算机程序。其他包括ATARI游戏,西洋双陆棋等。在机器人技术和工业自动化中,强化学习用于使机器人自己创建有效的自适应控制系统,该系统从自身的经验和行为中学习。DeepMind在“通过异步策略更新进行机器人操纵的深度强化学习”方面的工作就是一个很好的例子。
强化学习的其他应用包括抽象文本摘要引擎,可以从用户交互中学习并随时间改进的对话智能体(文本,语音),学习医疗保健中的最佳治疗策略以及用于在线股票交易的基于强化学习的智能体。
以上是关于强化学习常用算法+实际应用 ,必须get这些核心要点!的主要内容,如果未能解决你的问题,请参考以下文章
深度学习与图神经网络核心技术实践应用高级研修班-Day3强化学习(Reinforcemen learning)
必须掌握的核心算法有哪些?
强化学习 常用平台
程序员必须掌握的核心算法有哪些?
深度学习与图神经网络核心技术实践应用高级研修班-Day4深度强化学习(Deep Q-learning)
iOS 程序员必须掌握的核心算法有哪些?