基于FPGA的深度学习加速器综述:挑战与机遇
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于FPGA的深度学习加速器综述:挑战与机遇相关的知识,希望对你有一定的参考价值。
选自 arxiv
参与:姜悦、李亚洲
FPGA 的神经网络加速器如今越来越受到 AI 社区的关注,本文对基于 FPGA 的深度学习加速器存在的机遇与挑战进行了概述。
近年来,神经网络在各种领域相比于传统算法有了极大的进步。在图像、视频、语音处理领域,各种各样的网络模型被提出,例如卷积神经网络、循环神经网络。训练较好的 CNN 模型把 ImageNet 数据集上 5 类顶尖图像的分类准确率从 73.8% 提升到了 84.7%,也靠其卓越的特征提取能力进一步提高了目标检测准确率。RNN 在语音识别领域取得了最新的词错率记录。总而言之,由于高度适应大量模式识别问题,神经网络已经成为许多人工智能应用的有力备选项。
然而,神经网络模型仍旧存在计算量大、存储复杂问题。同时,神经网络的研究目前还主要聚焦在网络模型规模的提升上。例如,做 224x224 图像分类的最新 CNN 模型需要 390 亿浮点运算(FLOP)以及超过 500MB 的模型参数。由于计算复杂度直接与输入图像的大小成正比,处理高分辨率图像所需的计算量可能超过 1000 亿。
因此,为神经网络应用选择适度的计算平台特别重要。一般来说,CPU 每秒能够完成 10-100 的 GFLOP 运算,但能效通常低于 1 GOP/J,因此难以满足云应用的高性能需求以及移动 app 的低能耗需求。相比之下,GPU 提供的巅峰性能可达到 10TOP/S,因此它是高性能神经网络应用的绝佳选择。此外,Caffe 和 TensorFlow 这样的编程框架也能在 GPU 平台上提供易用的接口,这使得 GPU 成为神经网络加速的首选。
除了 CPU 和 GPU,FPGA 逐渐成为高能效神经网络处理的备选平台。根据神经网络的计算过程,结合为具体模型设计的硬件,FPGA 可以实现高度并行并简化逻辑。一些研究显示,神经网络模型能以硬件友好的方式进行简化,不影响模型的准确率。因此,FPGA 能够取得比 CPU 和 GPU 更高的能效。
回顾 20 世纪 90 年代,那时 FPGA 刚出现,但不是为了神经网络,而是为了电子硬件原型的快速开发而设计的。由于神经网络的出现,人们开始探索、改进其应用,但无法确定其发展方向。尽管在 1994 年,DS Reay 首次使用 FPGA 实现神经网络加速,但由于神经网络自身发展不够成熟,这一技术并未受到重视。直到 2012 年 ILSVRC 挑战赛 AlexNet 的出现,神经网络的发展渐为明晰,研究社区才开始往更深、更复杂的网络研究发展。后续,出现了 VGGNet、、ResNet 这样的模型,神经网络越来越复杂的趋势更为明确。当时,研究者开始注意到基于 FPGA 的神经网络加速器,如下图 1 所示。直到去年,IEEE eXplore 上发表的基于 FPGA 的神经网络加速器数量已经达到了 69 个,且还在一直增加。这足以说明该方向的研究趋势。
图 1:基于 FPGA 的神经网络加速器开发历史
论文:A Survey of FPGA Based Deep Learning Accelerators: Challenges and Opportunities

摘要:随着深度学习的快速发展,神经网络和深度学习算法已经广泛应用于各个领域,如图片、视频和语音处理等。但是,神经网络模型也变得越来越大,这体现在模型参数的计算上。虽然为了提高计算性能,研究者在 GPU 平台上已经做了大量努力,但专用硬件解决方案仍是必不可少的,而且与纯软件解决方案相比正在形成优势。在这篇论文中,作者系统地探究了基于 FPGA 的神经网络加速器。具体来讲,他们分别回顾了针对特定问题、特定算法、算法特征、通用模板的加速器,还比较了不同设备和网络模型中基于 FPGA 加速器的设计和实现,并将其与 CPU 和 GPU 的版本进行了比较。最后,作者讨论了 FPGA 平台上加速器的优势和劣势,并进一步探索了未来研究存在的机会。
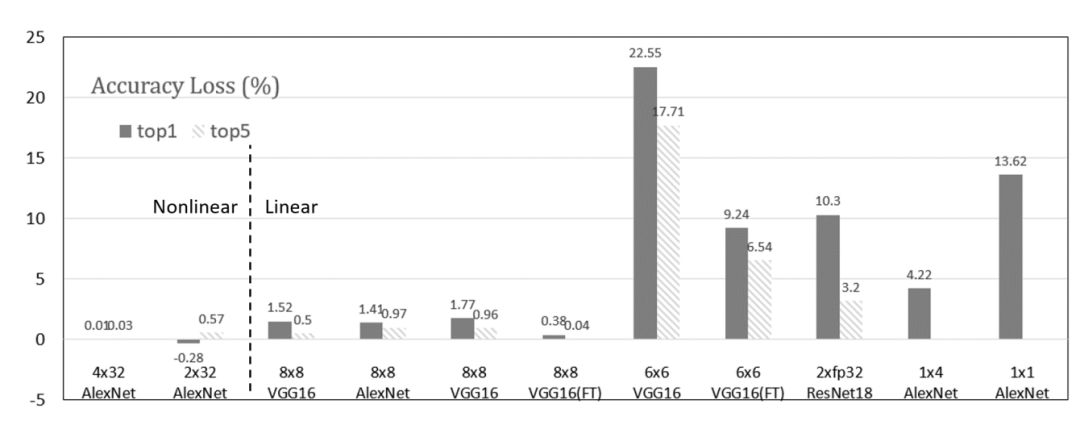
图 2: 不同数据量化方法的比较
表 1: 不同平台上不同模型的性能比较
机遇和挑战
早在 20 世纪 60 年代,Gerald Estrin 就提出了可重构计算的概念。但是直到 1985 年,第一个 FPGA 芯片才被 Xilinx 引入。尽管 FPGA 平台的并行性和功耗非常出色,但由于其重构成本高,编程复杂,该平台没有引起人们的重视。随着深度学习的持续发展,其应用的高并行性使得越来越多的研究人员投入到基于 FPGA 的深度学习加速器研究中来。这也是时代的潮流。
基于 FPGA 加速器的优势
1)高性能,低能耗:高能效的优点不容小觑,之前的许多研究已经证明了这一点。从表 1 中可以看出,GOP/j 在 FPGA 平台上的表现可以达到在 CPU 平台上的几十倍,它在 FPGA 平台上表现的最低水平与其在 GPU 平台上的表现处于一个层级。这足以说明基于 FPGA 的神经网络加速器的高能效优势。
2)高并行性:高并行性是选择 FPGA 平台加速深度学习的主要特性。由于 FPGA 的可编辑逻辑硬件单元,可以使用并行化算法轻松优化硬件,已达到高并行性。
3)灵活性:由于 FPGA 具有可重构性,它可以适用于复杂的工程环境。例如,在硬件设计和应用设计完成之后,通过实验发现性能未能达到理想状态。可重构性使得基于 FPGA 的硬件加速器能够很好地处理频繁的设计变更并满足用户不断变化的需求。因此,与 ASIC 平台相比,这种灵活性也是 FPGA 平台的亮点。
4)安全性:当今的人工智能时代需要越来越多的数据用于训练。因此,数据的安全性越来越重要。作为数据的载体,计算机的安全性也变得更加显著。目前,一提到计算机安全性,想到的都是各种杀毒软件。但是这些软件只能被动地防御,不能消除安全风险。相比之下,从硬件架构层级着手能够更好地提高安全性。
基于 FPGA 的加速器的劣势
1)可重构成本:FPGA 平台的可重构性是一把双刃剑。尽管它在计算提速方面提供了许多便利,但是不同设计的重构所消耗的时间却不容忽视,通常需要花几十分钟到几个小时。此外,重构过程分为两种类型:静态重构和动态重构。静态重构,又叫编译时重构,是指在任务运行之前配置硬件处理一个或多个系统功能的能力,并且在任务完成前将其锁定。另一个也称为运行时配置。动态重构是在上下文配置模式下进行的。在执行任务期间,硬件模块应该按照需要进行重构。但是它非常容易延迟,从而增加运行时间。
2)编程困难:尽管可重构计算架构的概念被提出很久了,也有很多成熟的工作,但可重构计算之前并未流行起来。主要有两个原因:
从可重构计算的出现到 21 世纪初的 40 年时间是摩尔定律的黄金时期,其间技术每一年半更迭一次。所以这种架构更新带来的性能提升不像技术进步那么直接、有力;
对成熟的系统而言,在 CPU 上传统的编程采用高阶抽象编程语言。但是,可重构计算需要硬件编程,而通常使用的硬件编程语言(Verilog、VHDL)需要程序员花费大量时间才能掌握。
期望
尽管基于 FPGA 的神经网络加速器仍旧有这样、那样的问题,但其未来发展依然可期。以下几个方向仍然有待研究:
优化计算流程中的其他部分,现在,主流研究聚焦在矩阵运算回路,激活函数的计算少有人涉及。
访问优化。需要进一步研究进行数据访问的其他优化方法。
数据优化。使用能够自然提升平台性能的更低位数据,但大部分的低位数据使得权重和神经元的位宽一样。图 2 还可以改进与非线性映射的位宽差。所以,应该探索出更好的平衡态。
频率优化。当前,大部分 FPGA 平台的运算频率在 100-300MHz,但 FPGA 平台理论上的运算频率可以更高。这一频率主要受限于片上 SRAM 和 DSP 之间的线程。未来研究需要找到是否有方式避免或者解决该问题。
FPGA 融合。据参考论文 37 中提到的表现,如果规划和分配问题能够得到良好解决,多 FPGA 集群可以取得更好的结果。此外,当前此方向没有太多研究。所以非常值得进一步探索。
自动配置。为了解决 FPGA 平台上复杂的编程问题,如果做出类似英伟达 CUDA 这样的用户友好的自动部署框架,应用范围肯定会拓宽。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于基于FPGA的深度学习加速器综述:挑战与机遇的主要内容,如果未能解决你的问题,请参考以下文章