深度学习的黑暗时代已来临?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习的黑暗时代已来临?相关的知识,希望对你有一定的参考价值。
译者 | 刘畅
责编 | 琥珀
出品 | AI科技大本营(ID:rgznai100)
【导语】热火朝天的人工智能技术,在许多领域都有令人印象深刻的成效,但依然掩盖不了缺乏真正人脑意识的事实。因此,研究人员决心找到缺失的东西。
你需要知道的是,深度学习已经在无人驾驶汽车、语音识别和其他众多方面产生了革命性的影响。
一张图片中,有一根大而成熟的亮黄色香蕉,人工智能(AI)还是会将其识别为烤面包机,尽管它应用了强大的深度学习技术。看起来就像是将一个小小的数字化日光贴纸贴在图像的某个角落。这个结果显示:即使训练数千张香蕉、毛虫、蜗牛和类似物体的照片,这个先进的AI系统也容易混淆。

这个深度学习研究人员称之为“对抗攻击”的例子,是由加州山景城的谷歌大脑(Google Brian)团队发现。它说明了AI在接近人类能力之前还需要走多远。“我最初认为对抗性的例子只是一种烦恼,”多伦多大学的计算机科学家Geoffrey Hinton说道,他是深度学习的先驱之一。“但我现在认为它们可能非常深奥。它会告诉我们,我们做错了什么。”
在AI从业者中广泛存在的一种情况是,任何人都可以轻易地列举一长串深度学习的弊端。例如,除了易受欺骗之外,还存在严重的低效率问题。Hinton说“让一个孩子学会认识一头母牛,并不需要他们的母亲说一万次牛”,而这却是深度学习系统中经常需要的数字。人类通常仅从一两个例子中就可以学会新概念。
然后是不透明问题。一旦训练好了一个深度学习系统,就无法确定它是如何做出决定的。“在许多情况下,即使AI得到了正确的答案,但也是不可接受的。”David Cox说,他是麻省理工学院与IBM联合实验室的计算神经科学家。他举了一个例子,假设一家银行使用人工智能来评估你的信誉,然后拒绝给你一笔贷款:“在许多州,有法律规定你必须解释原因”。
也许最重要的是,AI缺乏常识。深度学习系统可能是识别像素间的某种模式,但是他们无法理解模式的含义,更不用说理解它们产生的原因。DeepMind的AI研究员Greg Wayne说道,“我不清楚当前的系统是否能够知道沙发和椅子是用于坐着的。”
越来越多弱点的凸显,正在引起广大公众对人工智能技术的关注,特别是无人驾驶汽车,它们使用类似的深度学习技术进行导航,但也造成了广为人知的灾难和死亡事故。“人们已经开始说,‘也许人工智能存在问题’,”纽约大学的认知科学家加里·马库斯认为,他是深度学习里最直言不讳的怀疑论者之一。直到过去一年左右,他说,“过去有一种感觉是深度学习像拥有魔法。现在人们意识到它并不会魔法。”
尽管如此,但无可否认的一点是,深度学习仍然是一个非常强大的工具。这使得部署应用程序(例如面部和语音识别)变得非常常见,而这些应用程序在十年前几乎不可能完成。“所以我很难想象深度学习会在这点消失,”麻省理工的考克斯说。“更有可能我们会去修改它,或者丰富它。”
大脑战争
今天深度学习革命的根源在于20世纪80年代的“大脑战争”(brain wars),当时有两种不同的人工智能方法的倡导者争议性很大。
一派是现在称为“老式的AI”(good old-fashioned AI)的方法,自20世纪50年代以来一直占据主导地位。也可称之为符号AI,它使用数学符号来表示对象和对象之间的关系。再加上由人类建立的丰富的知识库,这些系统被证明在推理和得出关于诸如医学等领域的结论方面非常擅长。但是到了20世纪80年代,人们也越来越清楚地认识到,符号性的人工智能方法在处理现实生活中符号、概念和推理等方面时,表现得非常糟糕。
为了应对这些缺点,另一派的研究人员开始倡导人工神经网络,或称联接主义人工智能(connectionist AI),这是当今深度学习系统的前身。
这类想法是在任何的系统中,通过模拟节点网络来处理信号,这些节点就像是人脑中神经元的类似物。信号沿着连接或链路从节点传递到节点:类似于神经元之间的突触连接。像在真实大脑中一样,问题就转换为学习调整放大或抑制每个连接所携带信号的“权重”。
在实践中,大多数网络将节点排列为一系列层,而这些层大致类似于皮层中不同的处理中心。因此,专门用于图像的网络将具有一层输入节点,其响应于各个像素,其方式与杆状细胞和椎体细胞相应射入视网膜的光的方式一样。一旦激活,这些节点通过加权连接将其激活传播到下一级别的其他节点,这些节点组合输入信号并依次激活(或不激活)。这个一直持续到信号到达节点的输出层,其中激活模式提供一个断言。例如,输入图像是数字“9”。如果答案是错误的,那就说输入图像是一个“0”。而“反向传播”算法就是沿着层反向运行,调整权重以便下次获得更好的结果。
到20世纪80年代末,在处理嘈杂或模糊的输入时,这种神经网络已经证明比符号AI好得多。然而,这两种方法之间的对峙仍未得到解决。主要是因为当时适合人工智能系统的计算机资源非常有限,无法确切知道这些系统能够做什么。
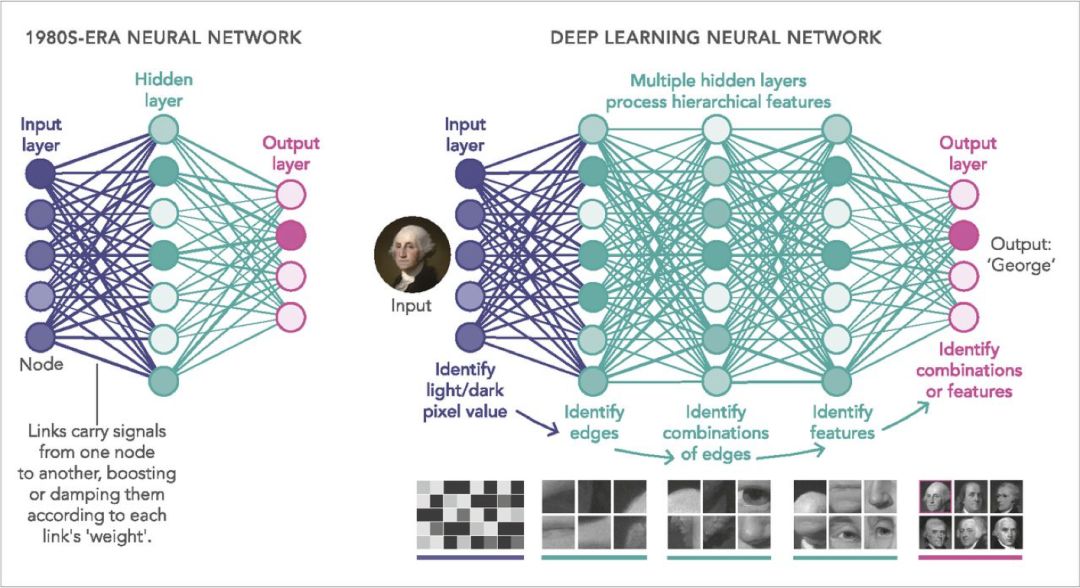
AI的“神经网络”模型主要是通过类似于神经元的节点网络发送信号。信号沿着链路传递到节点,类似于节点之间的突触连接。“学习”通过调整放大或抑制每个链路所承载信号的权重来提升结果。节点通常按层排列。而今天的计算机已经可以处理数十层的“深度学习”网络。
性能提升
通常意义上讲,从2000年开始,随着数量级更强大的计算机的出现以及社交媒体网站提供海量的图像、声音和其他训练数据。首先抓住这个机会的是Hinton, 他是反向传播算法的共同作者,以及20世纪80年代联盟主义运动的领导者。到了2010年中期,他和他的学生开始训练比以前更大的网络。它们相当的深,层数从一两层增加到大约六层。(而今天的商用神经网络通常使用超过100层。)
2009年,Hinton和他的两个研究生表明这种“深度学习”能够比任何其他已知方法更好地进行识别语音。2012年,Hinton和另外两名学生发表了实验,表明在识别图像时,深度神经网络可能比标准视觉系统好得多。“我们几乎将错误率减半,”他说。随着语音和图像识别的双炮齐鸣,深度学习应用的革命开始了。
早期的首要工作是扩展深度学习系统的训练方式,Matthew Botvinick表示。他在2015年从普林斯顿的神经科学小组离开,在DeepMind工作了一年。语音和图像识别系统都使用了所谓的监督学习,他说:“这意味着每张图片都有一个正确的答案,比如‘猫’,如果网络错了,你就告诉它什么是正确的答案。”然后网络会使用反向传播算法来改进其下一个猜测。
Botvinick说,如果你碰巧有几十个精心标记的训练样例,有监督的学习效果很好。而通常情况并非如此。它根本不适用于诸如玩视频游戏等没有正确或错误答案的任务,只有成功或失败的策略。
Botvinick解释说,事实上,在现实世界的生活中,你需要用到的是强化学习。例如,玩视频游戏的强化学习系统学会如何去寻求奖励(找到一些宝藏)并避免惩罚(赔钱)。
在深度神经网络上首次成功实现强化学习是在2015年,当时DeepMind的一个小组训练了一个网络来玩经典的Atari 2600街机游戏。“神经网络将在游戏中接收屏幕图像,” Botvinick说,“在输出端有指定动作的图层,比如如何移动操纵杆。”该神经网络的玩游戏的水平大致等于或者甚至超过了人类Atari玩家。到了2016年,DeepMind研究人员使用相同方法的更精细版本AlphaGo,它可以掌握复杂的棋盘游戏,并击败了当时的世界冠军。
超越深度学习
不幸的是,这些里程碑式的成绩都没有解决深度学习最根本的问题。例如,Atari系统必须玩数千轮才能掌握大多数人类玩家可以在几分钟内学到的游戏。除此之外,网络也无法理解或推理屏幕上的物体,如船桨。所以Hinton的问题仍然存在:(深度学习)究竟缺失了什么?
也许根本没缺什么。也许所需要的只是更多的连接,更多的网络层和更复杂的训练方法。毕竟,正如Botvinick指出的那样,在数学上已经证明神经网络等同于一台通用计算机,这意味着如果你能找到正确的连接权重,那么它们就没有不能执行的任何计算,至少在原理上是这样。
但在实践中,这样的警告可能是该领域研究人员有越来越强烈感受的一个重要原因,这样的感受就是需要一些新想法来克服深度学习的缺点。
一种解决方案是简单地扩展训练数据的范围。例如,在2018年5月发表的一篇文章中,Botvinick所在的DeepMind小组研究了在多个任务中训练网络时会发生什么。他们发现只要网络从后向前有足够的“周期性”连接,网络就能记住它从一个瞬间到下一个瞬间正在做什么。它能够自动得从已学的课程里,更快学会新任务。这至少是人类式“元学习”或learn-to-learn的雏形,这个能力让我们能快速的掌握某种事物。
更激进的一种可能方式是放弃训练一个大型网络来解决问题的方法,而是让多个网络协同工作。在2018年6月,DeepMind团队发布了一个他们称之为生成查询网络(Generative Query Network)的架构,该架构利用两个不同的网络来学习复杂的虚拟环境,而不需要人工的输入。其中一个被称为“表示网络”(representation network),基本上使用标准的图像识别学习方法来识别在任意给定时刻AI可见的内容。
同时,生成网络(generation network)学习通过获取第一个网络的输出来生成整个环境的3D模型。实际上,这个任务就是对AI看不见的对象和特征进行预测。举个例子,如果桌子只有三条腿可见,则模型就能涵盖具有相同尺寸、形状和颜色的第四条腿。
反过来,这样的预测结果会让系统学习的速度比标准的深度学习方法快得多,Botvinick说。“试图预测事物的agent会在每个时间步骤自动获得反馈,因为它可以看到它的预测结果如何。”因此它可以不断更新其模型以使其更好。此外,这种学习是自监督的:研究人员不必去标注任何东西使其工作,只需要提供奖励和惩罚机制。
一种更为激进的方法是,放弃让网络从头开始学习每个问题。“白板说”的说法确实可以让网络发现此前可能是研究人员从未想过的对象和行为方式,甚至是完全出乎意料的游戏策略。但是人类的学习从来都不是“白板”:对于几乎任何任务,人类至少可以依靠通过经验学习或进化硬塞到他们大脑中的先验知识。
例如,婴儿似乎天生就有许多固有的“归纳偏见”,这些偏见促使他们以惊人的速度吸收某些核心概念。到了2个月大的时候,他们已经开始掌握直觉物理的原理,其中包括物体存在的概念,他们倾向于沿着连续的路径移动;同样,婴儿也开始学习直觉心理学的基础知识,其中包括识别面孔的能力和认识到世界包含自己移动和行动的个体的能力。
具有这种天生的“归纳偏见”可能有助于深度神经网络拥有同样快速的学习能力,这就是为什么该领域的许多研究人员现在将其作为首要研究内容。事实上,在过去的1年或2年内,该领域的研究人员已经看到了一种被称为图网络的方法。“这些深度学习系统,它们将事物作为对象和关系表现出天生的偏见,”Botvinick说。
例如,某些对象(如爪子、尾巴和胡须)可能都隶属于较大的对象(猫),其关系是part of。同样,球A和B组可能具有相互关系the next to,地球与太阳有轨道围绕(is-in-orbit-around)关系,依此类推,通过大量其他例子,其中任何一个都可能表示为抽象图,其中节点对应于对象和关系的链接。
因此,图网络(graph network)是一种神经网络,它将图作为输入,而不是原始像素或声波。然后学会推理和预测对象及其关系如何随时间演变。(在某些应用程序中,可能会使用单独的标准图像识别网络来分析场景并首先挑选出对象。)
图网络的方法已经阐释了快速学习和人类对各种应用程序的掌握能力,包括复杂的视频游戏。如果它继续像研究人员所希望的那样发展,它可以通过提高训练速度和效率来缓解深度学习的10000-cow问题。并且它可以使网络更不容易受到对抗性攻击,因为代表一个物体的是系统,而不仅仅是像素,它不会被一点噪音或一个无关的贴纸轻易地干扰。
Botvinick承认,在任何这样的领域都不会轻易或快速地取得根本性进展。但即便如此,他认为这些不是无边界的。“这些挑战非常真实,”他说,“但并非死路一条。”
参考链接:
https://www.pnas.org/content/116/4/1074
(本文为 AI科技大本营翻译文章,转载请微信联系 1092722531。)
推荐阅读:
点击“阅读原文”,打开CSDN APP 阅读更贴心!
以上是关于深度学习的黑暗时代已来临?的主要内容,如果未能解决你的问题,请参考以下文章