Nimbus: Hulu的深度学习平台
Posted hadoop123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nimbus: Hulu的深度学习平台相关的知识,希望对你有一定的参考价值。
背景
Hulu是美国领先的互联网专业视频服务平台,目前在美国拥有超过2500万付费用户。Hulu的目标是帮助用户在任意时刻、任何地点、以任何方式查找并欣赏到高质量的电视剧、电影和电视直播。实现这一目标离不开各个团队的努力,而AI在其中扮演者越来越重要的角色。在Hulu, 我们拥有诸多的researcher团队,如广告团队,推荐团队,视频理解团队等ji等。早期的时候,大家还是各自为战,以“小作坊”的形式构建机器学习相关环境。这种非集中式的生产模式存在着许多弊端。概括来说就是无法共享资源(计算资源,数据资源,尤其是昂贵的GPU资源),无法共享经验(模型或者框架优化)以及存在很高的额外的环境搭建和运维成本(严重影响了researcher的工作效率)。基于此,我们构建了AI Platform这个跨Team的组织。
整个AI Platform可以分为三层,从上到下依次是AI服务层,ML数据层,基础架构层。AI服务层主要是用于线上模型管理和部署,涉及到CICD, 监控,负载均衡等服务相关内容。ML数据层则包含了机器学习所用到的数据源,包含经过多个ETL pipeline清洗后生成的用于存放特征的数据仓库。最底层则是基础架构层,包括分布式存储,计算和调度等等,这也是我们基础架构团队主要负责的一块。
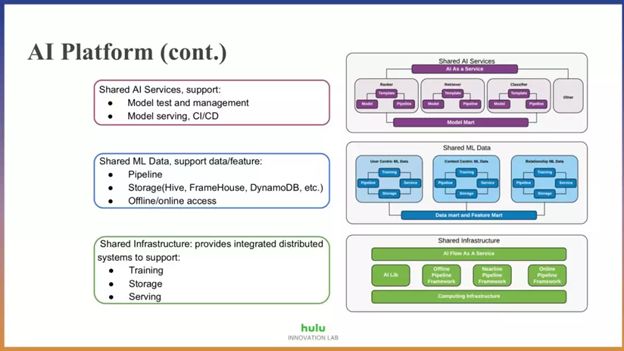
一个机器学习作业的生命周期大致可以分为数据准备阶段,模型训练阶段和模型服务阶段。在Hulu, 其对应的基础设施如下图所示。
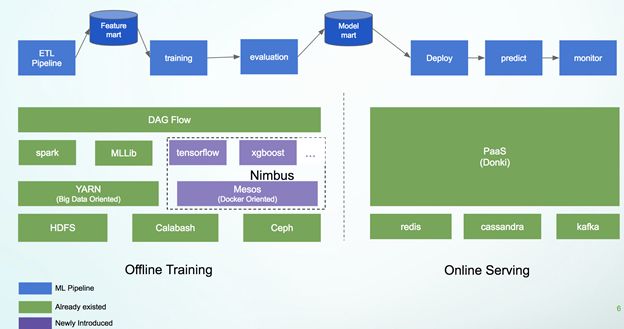
从图中可以看出,Hulu已经拥有大部分ML所需的基础设施,包括线上服务部分以及离线计算所能用到的Hadoop相关的基础设施等。这已经能满足一定程度的机器学习需求,但是Spark / Flink MLlib主要面向传统的机器学习算法,我们缺少了一套专门的机器学习平台,从而可以支持对环境要求更加复杂的机器学习框架尤其是深度学习框架。于是,我们研发了Nimbus。
技术选型
Docker
Docker是我们技术选型中最先确定的方向。机器学习平台一个很重要的需求就是对TensorFlow, Caffe, Pytorch,XGBoost等多种机器学习框架的支持,每种机器学习框架还有多种不同的版本,即使是统一版本也有不同的环境依赖,比如CUDA版本,Python版本等等。而Docker作为一个当下盛行的开源容器引擎,可以为任何模型训练创建一个轻量级的、可移植的、可隔离的容器环境,从而可以轻松应对这些需求。
Mesos
选定Docker作为底层引擎之后,下一个需要抉择的便是资源管理和编排框架。当时主要考虑的Yarn,Mesos以及Kubernetes。 在选型中,一个很重要的考量是对gpu的支持上。Yarn基本上从yarn 3.1真正开始支持将gpu作为底层可分配资源,而hulu大规模使用的都是基于cdh5.7.3的2.6版本,虽然可以通过打一些补丁进行支持,但是涉及的集群规模很大、服务众多,存在较大的风险。于此同时,yarn与docker的结合也并不是很完美。剩下的Mesos和Kubernetes都可以满足我们的需求,但是基于当时的软件成熟度、运维复杂度以及经验积累等方面的考量,我们最终选择了Mesos。
Framework
Framework是Mesos上存在的一种概念。Mesos实现了两级调度架构。第一级调度位于Mesos Master的守护进程,负责管理Mesos集群中所有节点上运行的Slave守护进程。Mesos slave将它的可用资源汇报给master,master再将资源分配给对应的Framework,由Framework选择接受整个、部分或者拒绝这个资源。所有接受的资源之后将由Framework负责调度。Mesos上开源的Framework并不是特别的多,起初我们选择Marathon, 并基于此完成了第一个版本,可以实现分布式TensorFlow, XGBoost的训练。很快,我们发现了其存在的一些局限性。其中最主要的原因在于Marathon更适合于长服务类型的作业,在短作业的生命周期管理上不够灵活。另外一点在于采用Marathon-LB作为服务发现引擎时,在分布式训练中,所有流量都需要经过Marathon-LB,从而带来严重的网络性能问题。之后,我们便采用了Hulu自研的针对短作业的高吞吐的调度引擎CapOS作为Mesos之上的调度框架。
架构设计
整体架构主要分为三块,Nimbus管理层,计算层和存储层。
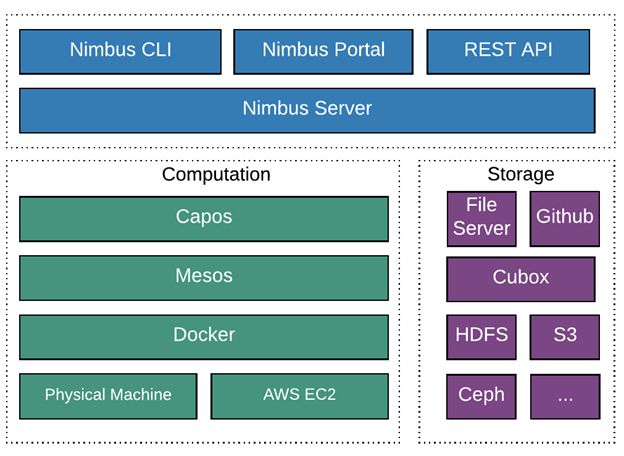
存储层主要包含了三块。(1)用于存储模型代码的Github以及基于Http的文件服务器。(2)Hulu内部用于存放镜像的镜像仓库Cubox。(3)用于存放海量的训练数据的多种分布式存储,如HDFS, S3, Ceph以及Hulu内部专门用作小文件存储的Framehouse等。
计算层主要采用了Mesos+Docker的解决方案,上层采用Capos作为调度平台,最终运行在IaaS层提供的物理机或者虚拟机之上。
Nimbus管理层上,通过封装和抽象,Nimbus对外提供了包括客户端、网页以及Restful API的访问接口,在这可以对机器学习任务进行一站式管理。Nimbus Server中包含了一些列AI作业管理的逻辑。
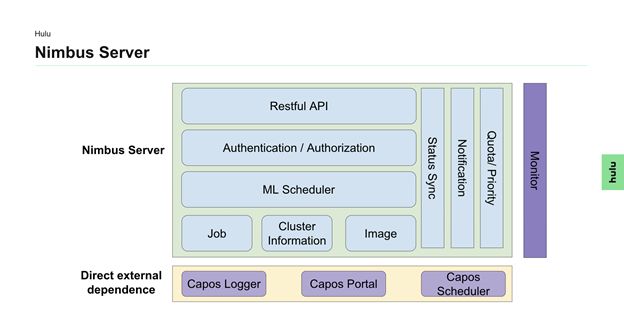
对于一个AI作业,Nimbus会根据框架类型和运行模式执行不同的处理逻辑。就运行模式而言,无非是分为单机模式和分布式模式。单机模式比较简单,一般直接对应一个容器。分布式模式则会相对复杂。目前主流的分布式训练主要包含一下几种方式。
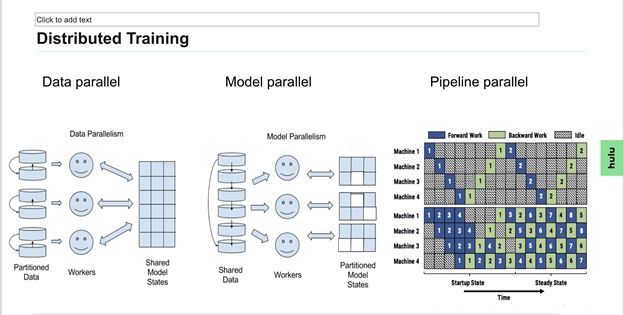
其中模型并行和流水线并行需要依赖于特定模型结构支持,因此并不具有通用型。作为平台方,我们主要考虑支持的是数据并行。数据并行一个主流的方案的是采用Parameter Server架构,这也是TensorFlow默认的方案。
我们利用CapOS提供的Programing API接口,实现了针对TensorFlow PS架构的Application Master,包含资源申请, 拓扑管理,组件间服务发现等环节。相较于之前同于LB的方式进行服务发现,这里采用了端到端直连的方式进行通信,可以尽量分摊网络开销,优化整体网络性能。
相对PS模式之外另一种数据并行方案采用的Allreduce模式,根据实现方式不同又可以细分为Ring Allreduce、Tree Allreduce等等。XGBoost的分布式实现就是基于Allreduce模式。同样的,我们也需要实现其对应的Application Master逻辑。
优化和改进
作为平台提供方,我们也一直致力于在功能性、易用性、性能等方面进行改进。下面将罗列一些比较重要的点。
框架支持
随着AI的火热发展,各种机器学习框架层出不穷。由于人力有限,我们也不可能面面俱到,对所有框架进行集成。根据目前Hulu的使用情况,我们已经完成了对TensorFlow, Pytorch, Caffe2,XGBoost, Gensim, LightGBM的支持。在框架集成上,除了完成一系列和我们底层存储对接外,很重要的一步在于镜像构建。在这里我们也做很多工作,包括
(1)一些源码的改造,使XGBoost分布式模式可以运行在容器之中,Caffe2的编译脚本的改造使得可以自动build出各种CUDA、OpenCV组合下的镜像。
(2)一系列的构建脚本,可以快速的完成对已支持框架的新版本的测试和集成。
(3)利用一些镜像优化手段如多阶段构建、基础层共享以及基础镜像提前分发等手段减少镜像下载时间,从而降低启动延迟。
(4)此外,Nimbus也支持自定义镜像,方便用户使用一些独特的计算环境或者框架。我们提供了一些模板镜像,方便用户进行镜像制作。
调试工具
调试是模型开发阶段必不可少的环境。一般而言,本地运行都会比远端执行更容易调试。为了较少这部分影响,我们提供了一些列工具。除了常规的作业日志和监控系统外,我们也集成了Terminal,可以远程登陆到机器内部进行调试。集成了Jupyter notebook, 并且提供debug模式,内置了nimbus-run和nimbus-tensorboard等命令,可以很方便的在容器内进行边修改,边调试运行,边看结果,尽可能实现和本地调试一样的体验。由于debug模式同实际运行使用了同样的资源,为了避免资源浪费,我们会有时间限制,到期后除非续约,否则将自动回收资源。/在这种模式下,Jupyter主要用作debug场景,我们也在计划构建真正意义的Jupyter as a Service,可以取代reacher的工作站,完成云端编码、测试、训练等一条龙服务。
调度策略优化
CapOS默认的调度策略针对高吞吐做了大量优化,缺乏针对机器学习任务特别是分布式机器学习任务的优化。得益于其提供的灵活的Programming API,在默认策略之上我们封装了一层的针对AI作业的调度策略。
(1)数据中心自动选择。Hulu目前同时使用了多套数据中心,包括自己本地构建的两个数据中心以及云上的多个数据中心。Nimbus提供了对多个数据中心进行调度的能力。用户可以自己选择数据中心也可以由系统进行设置。数据中心一旦配置错误,将带来大量的跨数据中心的访问,极大的影响模型训练的速度。为此,我们加入了对数据源的位置感知能力,系统根据AI作业的输入和输出信息,以及各个数据中心的资源使用情况,可以自动选择最为合适的数据中心。
(2)GPU 优先的调度策略。GPU对于机器学习尤其是深度学习来说是一种极为重要的资源。在当前Nimbus集群中,同时存在了GPU作业和一般的CPU作业。在之前调度逻辑中,CPU作业可能会占据GPU机器上的CPU和内存资源,导致GPU任务因为CPU或者内存不足而没法调度出去,从而可能引发GPU资源闲置。在之后,我们对GPU机器做了额外的保护,尽量避免CPU作业抢占GPU的资源,只有当GPU机器出现闲置并且CPU机器不足以满足的情况下才会进行调度。
(3)分布式任务拓扑感知。分布式训练主要瓶颈在于多机之间的通信开销。因此我们需要分布式训练的各个节点尽可能位于同一机房,同一机架甚至同一机器上。在PS架构下,PS 节点作为中心节点,网络流量往往非常大,很容易把带宽跑满,在这种场景下需要尽可能把PS节点打散到不同的宿主机上,从而分摊网络流量。我们当前的版本还是基于一个比较粗的力度,这一点不如K8S,其可以利用Pod Affinity很容易实现更细粒度的优化。
统一的IO层
虽然用户的模型代码几乎可以不用修改就可以直接运行在Nimbus之上,然而在大规模机器学习训练过程中,势必需要引入分布式存储。从本地存储转到分布式存储,这将带来很大的使用习惯的改变。尽管主流分布式存储也都支持POSIX标准,然而这会降低IO性能,影响训练效率。为了减少这层gap,我们引入了一个统一的IO层,提供常用的文件Open,List, Delete接口,对外屏蔽底层文件系统的差异。所有的IO请求都将根据schema不同自动路由到不同文件系统之中。
开源社区合作
Nimbus相关生态系统中有大量的来源于开源社区的组件。作为平台方,我们也一直紧密关注着开源社区尤其是机器学习框架的动态。汲取社区力量更好的服务Hulu内部用户,也把Hulu的需求和优化回馈给社区。我们向XGBoost社区反馈了分布式模式下的文件处理的bug并解决后贡献给开源社区(dmlc-core/pull/452)。后续我们也会和社区保持紧密的联系,共同推动社区的良性发展。
作者简介:苏经纬,Hulu AI基础架构研发工程师,专注于AI、容器、容器编排等技术。
以上是关于Nimbus: Hulu的深度学习平台的主要内容,如果未能解决你的问题,请参考以下文章
Hulu机器学习问题与解答系列 | 十五:多层感知机与布尔函数