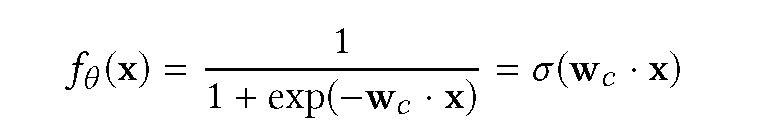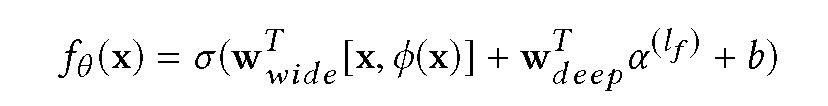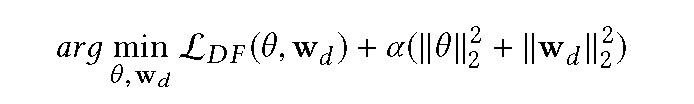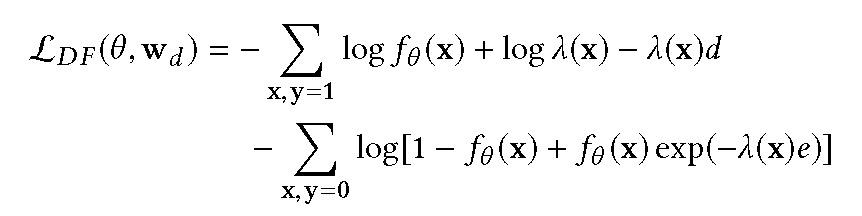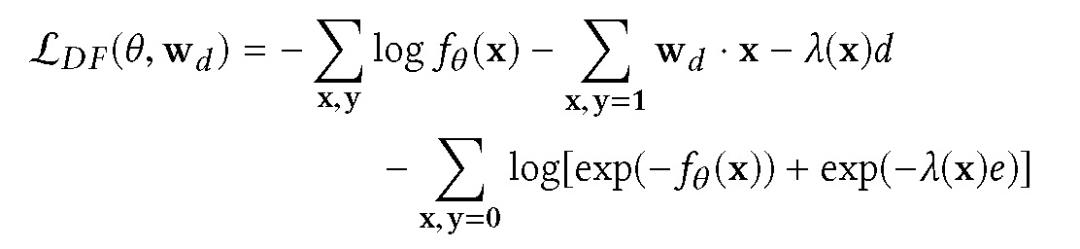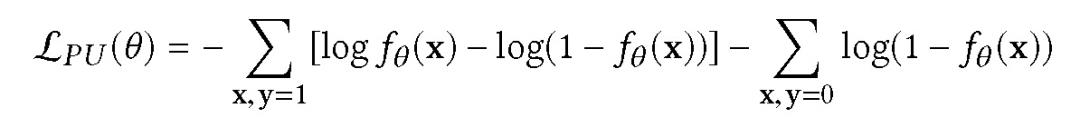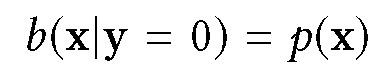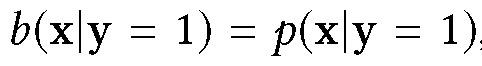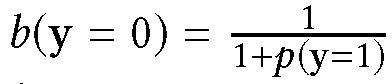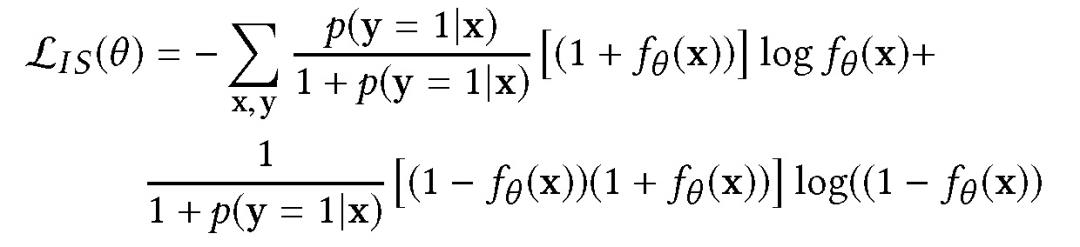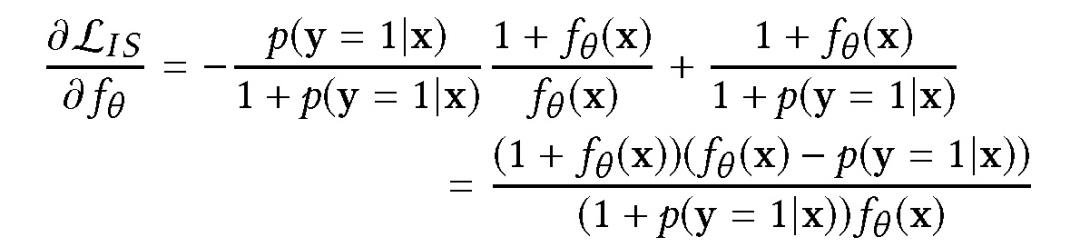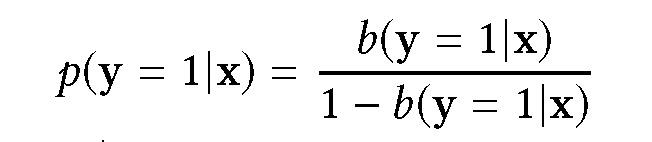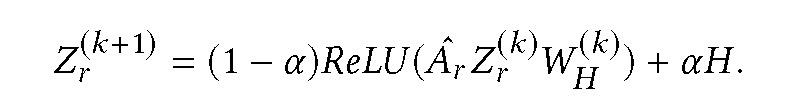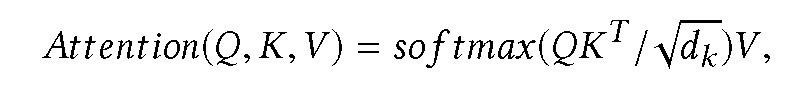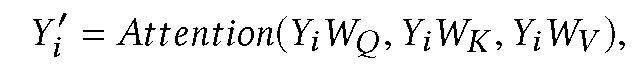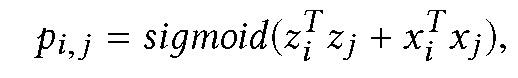RecSys提前看 | 深度学习在推荐系统中的最新应用 Posted 2021-04-19 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RecSys提前看 | 深度学习在推荐系统中的最新应用相关的知识,希望对你有一定的参考价值。
2019 年 9 月 16 日至 20 日,第 13 届 ACM Conference on Recommender System(RecSys)在丹麦哥本哈根召开。作为推荐系统的顶会,RecSys 一如既往受到了业界的广泛关注。与其他机器学习会议相比,RecSys 一向重视解决实际的问题,即结合在实际应用场景中推荐系统性能提升、效果提高等问题提出设计策略和算法解决方案等。随着深度学习研究的进一步深入,深度学习在推荐系统中的应用依然是研究热点之一,本次会议中图神经网络(Graph Neural Network,GNN)、经典深度学习模型都有所应用及改进。本文从中选取三篇,进行针对性的分析:
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction,提出一种基于损失函数的神经网络模型,用于解决连续学习过程中的延迟反馈问题。
Tripartite Heterogeneous Graph Propagation for Large-scale Social Recommendation,提出一种应用于社会化推荐系统的异构图传播结构。
On Gossip-based Information Dissemination in Pervasive Recommender Systems,提出一种离线手机端与邻近区域内其他设备之间推荐评分数据交换问题的普适推荐系统策略。
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
应用于广告展示的推荐系统面临的一个重要难点是,由于季节性、广告活动的变化和其他因素,广告特征分布和点击率(click through rate,CTR)会随着时间而发生巨大的变化。解决这一问题的主要策略是不断地基于新数据连续训练预测模型。然而一些应用场景中数据标签仅存在一段时间且会出现一定的随机延迟,这些延迟的反馈标签对连续训练中的数据新鲜度提出了挑战:新数据在被训练算法接收时可能没有完整的标签信息。一个简单的解决这个问题的方案是除非用户给数据打正标签,否则任何一个数据点都是一个负样本。这种方案往往带来较低的 CTR,从而导致用户体验差和性能差。
本文的重点是找到推荐系统中损失函数和深度学习模型的最佳组合,使其在存在标签延迟反馈的情况下,能够从连续数据流中进行有效的大规模学习。本文考虑两种模型:一是简单 Logistic 回归模型,该模型应用简单、性能良好以及易于接收和处理在线训练的新训练样本,在展示广告中得到了广泛的应用。二是广度-深度(wide-deep)模型,该模型能够有效解决推荐系统的特征复杂性和多样性问题。此外,本文考虑五种损失函数:对数损失、假阴性(fake negative,FN)加权损失、FN 校准、正未标记损失和延迟反馈损失。
本文是首次使用深度学习模型来评估展示广告中的概率 CTR(pCTR),同时解决数据标签延迟反馈问题。考虑到由于时间成本较高,深度神经网络很难在在线训练中应用,本文在不增加工程成本的情况下,对延迟反馈问题进行基准测试并提出时间成本可行的解决方案。
本文提出了一种连续训练机制,假设前提是等待有限长的时间能够得到广告的正向参与标签。针对这一类问题,传统方法一般是预先给定样本数据负标签,直到用户标记后改为正标签。有偏数据分布,即观测到的分布情况,包含了标记为负的实际数据分布的所有样本。
本文考虑两种学习模型,简单 Logistic 回归模型和广度-深度(wide-deep)模型。
本文使用标准 Logistic 回归模型,该模型在展示广告领域得到了广泛的应用。
其中 sigma(.) 表示 sigmoid 函数,输入 x 是与特定请求的用户和候选广告相关的数千个特征的稀疏表示。
广度-深度模型包含两个组成部分:广度模块(广义线性模型)和深度模块(标准前向-后向神经网络)。广度模块处理原始输入特征和转换后的特征,例如交叉产品特征,将非线性特征添加到广义线性模型中。而深度模块主要是将高维稀疏特征转化为嵌入向量,从而将分类特征转换为密集的低维表示。广度-深度模型对 CTR 的预测如下:
其中,w_wide 表示广度模块的权重,w_deep 表示深度模块的权重,phi(x) 表示交叉产品变换,alpha 为深支末级激活。
(1)延迟反馈损失(delayed feedback loss)
在延迟反馈损失函数中,假定时滞服从指数分布,并将此模型与 Logistic 回归或深度模型联合训练。参数θ和 w_d 的正则对数似然优化为:
其中 alpha 为正则化参数,L_DF 表示为:
f_θ(x)对应 pCTR 模型的输出,d 对应于点击一个正样本的时间,而 e 代表自广告播放以来经过的时间。延迟反馈损失函数的数值计算格式为:
(2)正未标记损失(positive-unlabeled loss, PU 损失)
本文在 FN 设置下使用正未标记(positive unlabeled,PU) 损失,将有偏训练数据中的所有负样本视为未标记。损失函数为:
该损失函数可以看作是对正样本和负样本的传统对数损失。此外,只要观察到一个正样本,就向负梯度的相反方向递进。这个假设是合理的,因为对于每个正样本,都有基于假负样本梯度的参数更新。
(3)假阴性加权损失(fake negative weighted,FN 加权损失)
这种损失依赖于重要性抽样。在本文的训练设置中,样本被标记为负后进入训练队列,一旦用户参与后立即使用正标签进行复制。给定下面的假设:
其中 b 为偏移观测分布,p 为真实数据分布。由于所有样本数据初始标签都为负,所以有:
当∂L_IS/∂f_θ = 0 时,f_θ (x) = p(y = 1|x)
(4)FN 校准(fake negative calibration)
FN 校准中,模型估计偏移分布 b,L_IS(θ) 中 p(y=1|x) 改为:
由于对于偏移分布中的每一个正分布都能观察到 FN,即 b(y=1|x)≤0.5 和 p)y=1|x≤1,该分布始终有效。
实验目的:离线指标实验目的是验证所提出的损失函数是否适用于 CTR 预测问题,并用两个不同的数据集(一个内部数据集和一个公共数据集)对模型进行了训练和测试。
评价指标:Log 损失(Log loss)、相对交叉熵(relative cross entropy,RCE),精确召回曲线下面积(area under precision-recall curve, PR-AUC)。
实验目的:在线指标实验目的是对离线情况下效果最优的模型和损失函数进行进一步评估。在线指标反映了不同方法解决延迟反馈问题的实际性能。
数据库:以 Twitter 数据的延迟评估数据集执行评估,比较「控制」和「处理」(在 A/B 测试框架中)之间的性能。评估结束后 9 小时内删除假负样本标签。
评价指标:集合相对交叉熵(pooled RCE)、每千个请求收益(revenue per thousand requests,RPMq)。
本文在在线和离线实验中均使用随机梯度下降优化算子(stochastic gradient descent,SGD),学习速率为 0.02,衰退速率 0.000001,批处理大小为 128,延迟反馈损失学习速率为 0.005,延迟反馈模型的 L_2 正则化参数为 2。广度-深度模型中 4 层模型大小为 [400,300,200,100],中间层使用 ReLu 激活函数。权重参数使用 Glorot 优化。
离线实验中使用 Criteo 公开数据库。此数据库描述单击后的转换,因此与 CTR 预测相比,时间延迟通常更长。每个样本由一组散列分类特征和几个连续特征描述。训练样本总数为 1550 万个,测试样本为 350 万个。为了从原始的公共数据集中创建伪负数据,执行以下过程:使用最新的转换时间或单击时间作为快照时间,并在单击所有正样本时引入伪负样本。原始数据集用于验证 Logistic 和延迟反馈损失函数估计的实验,而包含单击时 FN 样本的数据库则用于评估 PU、FN 加权和 FN 校准损失函数。
对于离线指标实验中的内部数据,使用线下 Twitter 4 天的数据。评估过程是基于第二天的数据进行的。由于仅有一小部分广告提供了用户点击功能,数据标签的严重不平衡给算法带来了很大难度。为解决这一问题,本文的训练设置中将负样本减少到原始数据集的 5%,并且在损失函数中对负样本采用更高的权重。经过上述处理,训练样本约为 6.68 亿条视频广告,而测试数据为 700 万条广告。
在线指标中使用 Twitter 在线库,在在线实验中,所有的模型都在一个连续的数据流上进行训练,这个数据流是由回调数据实时生成的。将每个训练样本发布到模型的训练服务订阅的数据流中。连续训练过程每 10 分钟输出一个模型,然后由预测服务提取这些模型以服务于在线场景。
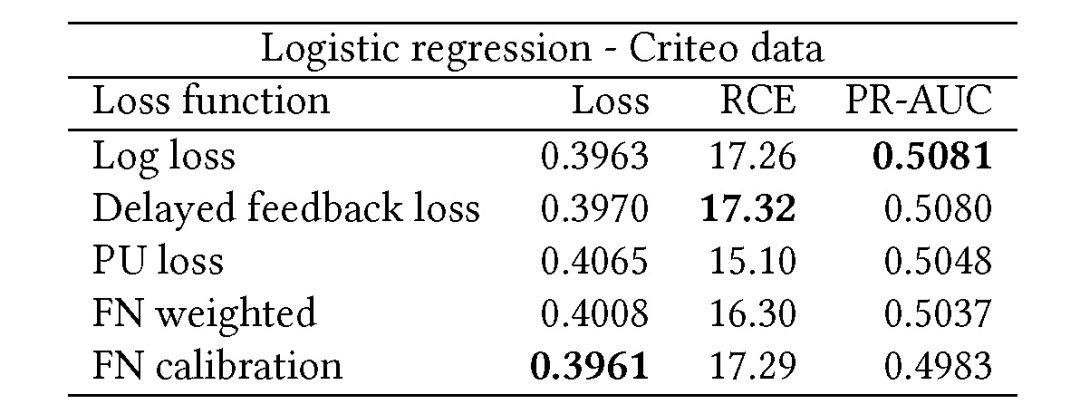
基于 Criteo 公开数据库的离线实验结果在表 1 中。使用延迟反馈损失函数产生的 RCE 最高(17.32),其次是 FN 校准损失函数(RCE 为 17.29),与 Log 损失的 RCE 持平。使用 PU 损失函数的结果最差,且在不同循环轮次实验中效果也最不稳定。实验结果表明,延迟反馈损失函数更适合于简单的 pCTR 模型(例如 Logistic 回归)和较少的训练样本。对于复杂的广度-深度模型则需要更稳健的解决方案,例如应用重要样本抽样策略等。
表 1. 基于公共 Criteo 数据的线性模型的离线结果。
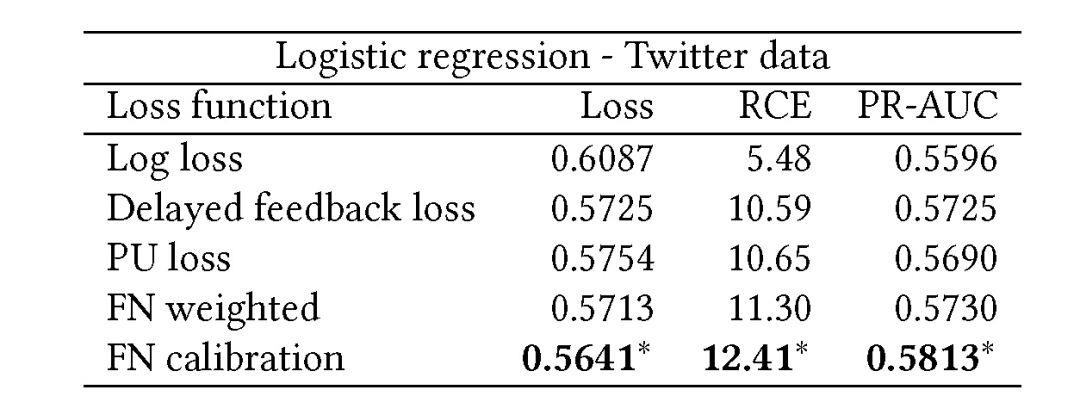
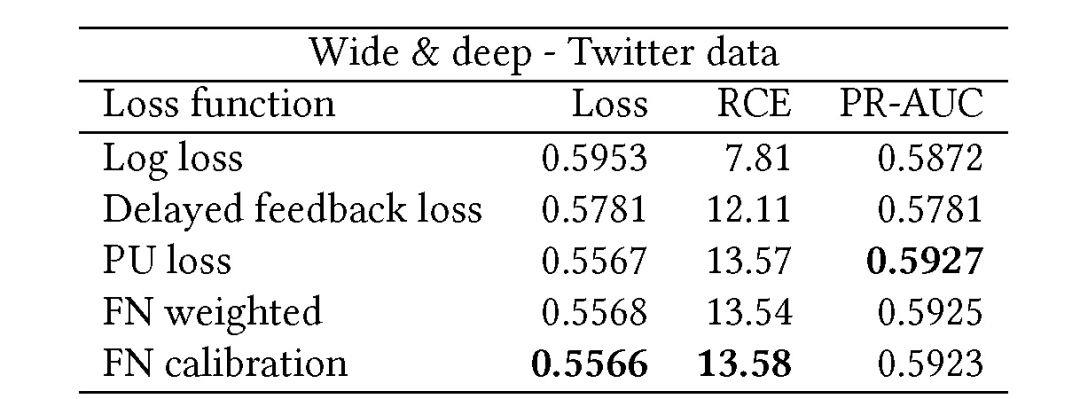
使用离线 Twitter 数据的实验结果在表 2 和表 3 中,分别用的是 Logistic 回归模型和广度-深度模型。由实验结果可知,广度-深度模型在应用不同损失函数的情况下,效果都优于 Logsitc 回归模型。
表 2. Twitter 数据的 Logistic 回归模型离线结果
表 3. Twitter 数据的广度-深度模型离线结果
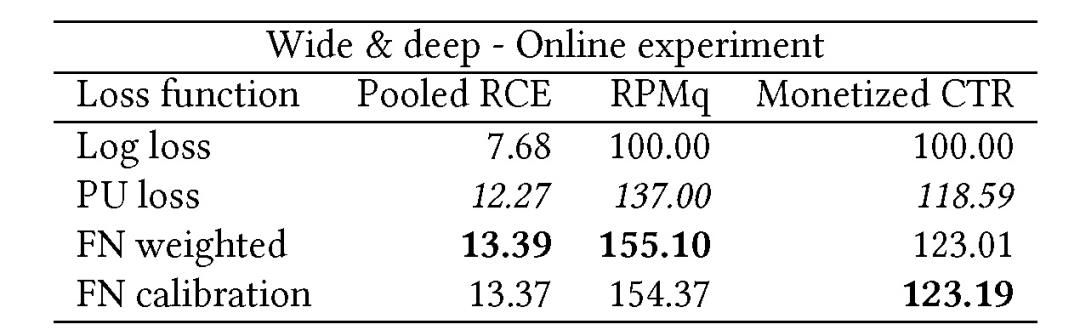
表 4 给出使用最优损失函数的广度-深度模型结果。应用 FN 加权损失函数和 FN 校正损失函数的 RPMq 值均高于传统的对数损失函数(分别提升了 55.10% 和 54.37%)。
表 4. 广度-深度模型以及性能最佳的损失函数(Twitter 数据)的在线结果
本文重点研究具有损失函数的神经网络模型在连续学习过程中的延迟反馈问题。由本文的分析可知,对于损失函数的选择需重点考虑梯度的时间依赖性,即基于伪负样本的参数更新先于来自正样本的更新。基于本文工作,后续考虑将重要样本抽样策略与时滞建模相结合,为训练样本分配与时间相关的权重。此外,还将继续研究连续学习中的其他问题,例如灾难性遗忘和过度拟合,以及研究更系统的方法来处理数据集偏差。
Tripartite Heterogeneous Graph Propagation for Large-scale Social Recommendation
原文地址:https://arxiv.org/abs/1908.02569?context=stat
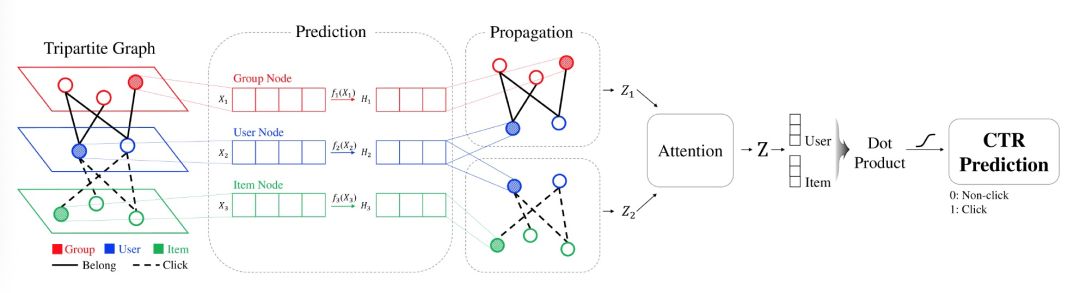
图神经网络(GNN)是一种有效的关系表示方法。应用于推荐系统 GNN 还存在一些难点,例如复杂的噪声连接和高度的异构性、过平滑等。本文提出了一种新的图嵌入方法——异构图传播(Heterogeneous Graph Propagation, HGP)来解决这些问题。HCP 使用 组-用户-项目(group-user-item)三部分图作为输入,以减少大规模社会化推荐系统图中的边缘数和路径复杂性。为了解决过平滑问题,HCP 将节点嵌入到一个基于 PageRank 的个性化传播方案中,分别用于组-用户图和用户-项目图。每个图中的节点嵌入使用注意力机制进行集成。
GNN 有多重不同的架构,本文基于图卷积神经网络(Graph convolutional networks)结构的 GNN 来处理属性化的多重异构网络,同时利用了个性化的 PageRank 方案。对于社会化推荐系统来说,项目、用户和社会关系构成了节点和边类型多样的复杂网络。单纯地将传播方案直接应用到异构图中,可能会导致对具有优势的边缘的偏差训练。本文提出的 HCP 能够独立地传播每种边类型的邻域,然后将最终的节点表示与注意力模型相结合。
对于一个异构图 G,节点映射函数为ϕ : V → O,边映射函数为ψ : E → R。Ar 表示包含类型为 r 的边的邻域矩阵。Aˆr 表示 Ar 的对称规范化邻接矩阵。将节点划分为不同种类:X1,X2, ...,X|O|,分别应用预测神经网络 Hi=f_i(Xi),将结果连接起来得到:H =[H1,H2, ...,H|O |]。HGP 使用具有附加可学习权重的非线性传播来学习深度节点表示:
将最终的节点表示矩阵与注意力模型(attention model)相结合。在保持通用性的前提下,我们从 z(k)_r 中为每种边缘类型选择第 i 个节点(行)。将这些向量叠加形成一个矩阵 Y_i,使用单层传感器的注意力模型:
其中,d_k 表示输入查询和键的维度。利用该模型,HCP 对 Y_i 进行注意力计算如下:
其中,查询、键和值是相同的,只是基于不同的权重矩阵相乘。然后,HGP 将 Y′_i 的所有行连接起来,并将其传递给线性层,生成第 i 个节点的表示向量 z_i。在本文提出的社会化推荐系统的应用中,计算用户和项目表示之间的点积相似性来预测 CTR
其中 X_i 是特征矩阵 X 的第 i 行向量。本文利用随机梯度下降算法,通过降低交叉熵损失来优化模型。递归的跨层邻域扩展需要消耗大量的时间和较高内存来训练大而密集的图,本文通过调整采样概率使其与每种类型的节点数成比例来解决这个问题。为了减小近似方差,采样概率与节点的阶数成正比。HGP 完整的模型架构见图 1。
图 1. 应用于社会化推荐系统的 HGP 的示意结构。HGP 为每种边缘类型独立地传播邻域,然后将最终的节点表示与注意力模型相结合。本文计算用户和项目表示之间的点积相似度来预测 CTR。
数据库:本文使用从大型社交网络收集的数据库,包含组、用户和项目三种节点类型。当用户属于同一组,则组和用户节点相连。与传统图中组所有用户都连接的方式比较,组节点有效地减少了边的数量和路径的复杂性。当用户与项目有交互行为时,项目和用户节点相连接。数据库中共有 1645279 个节点连接 4711208 个边。使用 BERT 和 VGG16 提取视觉语言属性的高级特征。利用线性嵌入层将分类属性转化为密集特征。最后,聚合所有特征来表示节点。使用前 11 天的数据作为训练集,随后 2 天的数据作为验证集,最后 4 天的数据作为测试集。
对比模型:metapath2vec、metapath2vec+EGES、MNE+EGES、FastGCN、HGP。
验证指标:ROC-AUC、PR-AUC、F1 score。
实验平台:NAVER Smart 机器学习平台(NSML)。
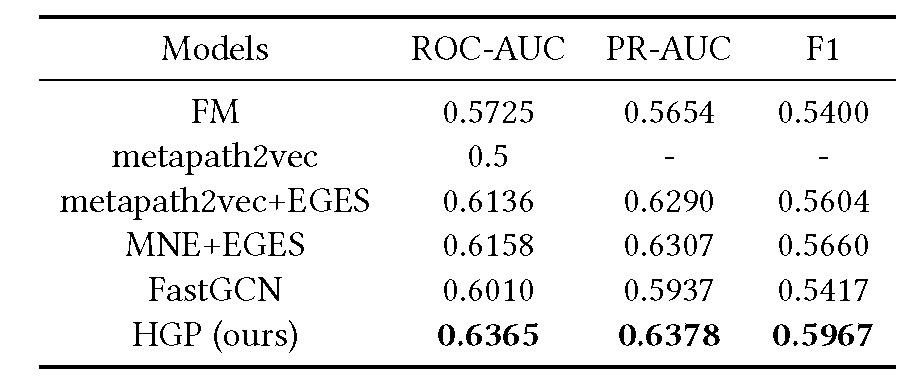
表 1. 对比模型的性能比较。 连字符「-」表示由于结果存在较大方差,无法得到稳定的性能。
对比实验结果见表 1,由实验可知,PR-AUC 和 F1 值与 ROC-AUC 成正比。不使用节点属性的 metapath2vec 无法完成 CTR 预测。HGP 的性能优于 FastGCN,这是由于 FastGCN 存在过平滑问题,不适用于异构图。HGP 性能优于其他异构图网络模型。此外,HGP 的验证损失能够在半天内收敛,因而能够满足实际应用场景中推荐系统所需的服务模型日常更新的要求。
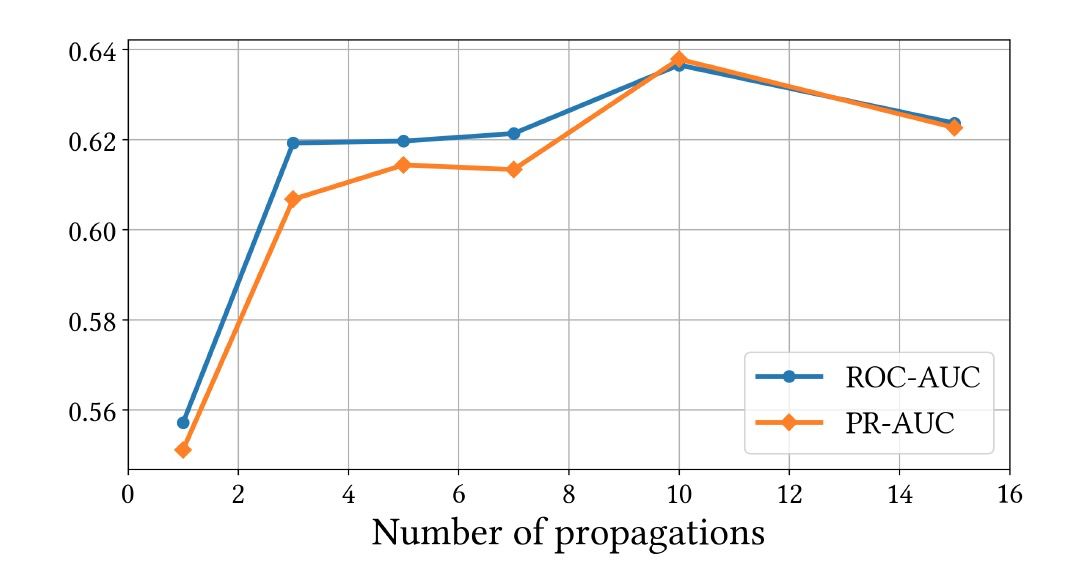
图 2 给出不同传播步骤下 HGP 的性能。HGP 需要至少两个步骤才能获知统一组内其他节点的信息(用户节点→组节点→用户节点)。如果传播步骤为 4 步,则可以接近具有共同偏好的用户的其他首选项(用户节点→组节点→用户节点→组节点)。传统架构的性能随着传播步骤数目的增加而降低。而 HGP 在步骤为 10 时达到最佳性能,并成功地避免了过平滑现象。
本文提出了一种应用于社会化推荐系统的图结构,即群-用户-项目三方的多重异构网络。本文提出的图形配置方案将计算时间和内存消耗减少为节点数的平方,组节点的属性有助于挖掘用户之间的社会关系。此外,本文还提出了一种基于图的推荐方法,称为异构图传播(HGP)机制。为了避免过平滑问题,HGP 使用个性化 PageRank 方案传播邻域信息。HGP 能够有效地处理图的异构性。为解决扩展性问题,本文采用了适合于异构环境的采样方法。后续可以通过添加其他社会属性(如地址、教育背景和共同兴趣)等来扩展图表,从而有效提升社会化推荐系统的效果。
On Gossip-based Information Dissemination in Pervasive Recommender Systems
原文地址:https://arxiv.org/abs/1908.05544
普适计算采用分布式和嵌入式设备随时随地完成通信和数据处理。随着手机的推广使用、手机性能的提升以及网络通信能力的提升,普适计算的应用价值越来越高。本文重点研究离线手机端与邻近区域内其他设备之间推荐评分数据的交换问题。本文提出了一种传播和过滤策略,将传统的寻找相似的对等设备和交换项目偏好的方法从分散领域转化为普适推荐系统问题。同时本文还给出了一个移动应用程序原型,实现了所提出的设备到设备的信息交换。
近年来,随着数据获取、存储、处理的渠道越来越多,关于数据隐私保护的技术受到越来越多的关注。欧盟于 2018 年 5 月通过了《通用数据保护条例》,针对数据处理、获取等提出了严格的限制,但是这些限制仅停留在用户规则的层面,并不涉及技术层面的约束。
目前,解决大规模授权数据池隐私问题的推荐系统架构主要有三种:一是,联邦学习(Federated Learning),基于分布在客户端中的数据,通过中央服务器和客户端之间的通信生成集中的推荐模型。二是,分散推荐系统,在没有中央服务器的情况下,分布式客户端直接对等通信交互。它们通常建立在使用八卦机制(Gossip)的文件共享对等网络的基础上,在对等节点加入或网络扰动的情况下,建立起用于快速网络搜索和网络恢复的逻辑覆盖网络。三是,基于位置感知推荐的普适系统,无需将本地数据传输到中央服务器进行推荐。
在这三种方法中,本文认为普适推荐系统效果最好。一是,由于智能手机本身的数据和移动计算能力提升,使得在智能手机端训练和生成推荐模型变得更加可行。二是,普适系统中推荐模型构建过程仅在设备上完成,因此对网络连通的情况没有任何要求。本文提出了一种基于 Gossip 机制的普适推荐系统数据传播和过滤策略,利用 Google 的 Nearby Connection API,通过安卓手机应用程序的方式实现了传播过程。
本文提出一种基于运动中的人携带的移动设备的推荐数据传播策略。当设备物理空间位置靠近时,设备之间会进行后台数据交换,之后进行设备内的定制过滤过程。作者将此方法称为传播(Propagate)和过滤(Filter)。
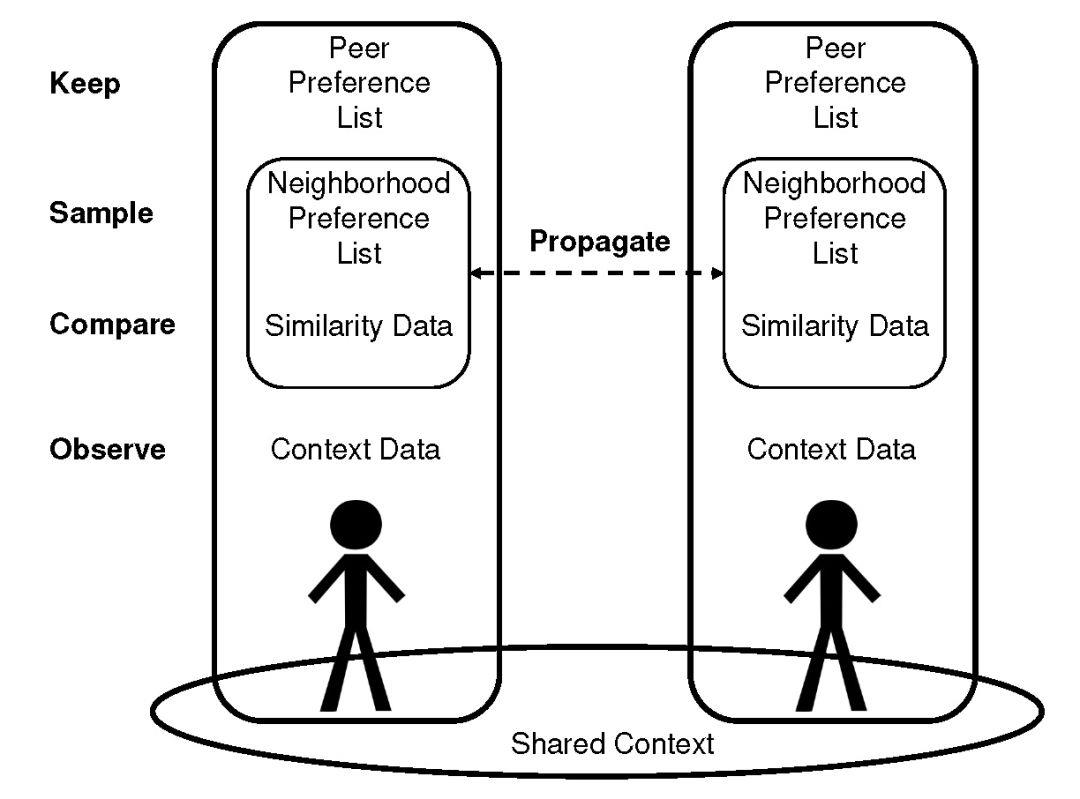
图 1:Propagate 和 Filter 提出的四种数据类型及其在传播中的应用
规定每个设备携带四种类型的数据(参见图 1),基于四种类型的数据生成本地个性化推荐。
对等首选项列表(Peer Preference List):对等设备中评定的项目列表,数据格式为二进制数或标量等级。在本文的原型实现中,对等设备中实现对电影的分级打分,其中每个电影都由公共可用的网络电影数据库(Internet Movie Database,IMDb)提供的唯一标识符进行标识。对等首选项列表数据保存在设备上。
邻域首选项列表(Neighborhood Preference List):每一个节点将之前从 k 个最相似的节点收集到的打分数据整合到一个项目评分列表中。因此,它是未知对等设备中数据子集的首选项列表。邻域首选项列表能够传播给其他对等设备,同时每个对等设备也能够控制将自己的哪些对等首选项列表传播到附近对等设备中。
相似数据(Similarity Data):任何类型的数据都可用于计算对等相似度。相似数据能够传播给附近的对等设备,因此必须保证其隐私性。隐私保护相似性比较可以在项目向量和文本数据上进行。
上下文数据(Context Data):用于描述特征的数据,如位置、时间、天气或对等活动(跑步、吃饭、通勤)等,能够被感知(例如通过传感器)或检索(例如通过网络)。
当两个或多个对等设备在物理空间上相互靠近时,智能手机建立快速和安全的配对连接,并交换他们的邻域首选项列表和相似数据。在上述传播过程中,接收到的数据包含上下文数据,例如描述相遇的时间或位置。
传播过程中收集到的数据包含大量未过滤的原始数据。为了得到有用信息,需要通过相似性进行数据过滤。从对等设备接收到数据后,设备开始执行过滤过程。首先,基于相似数据对比发送方和接收方的相似度;第二,如果对等相似度高于 k-最高值,则基于 k-最相似对等设备的对等首选项列表和邻域首选项列表对邻域首选项列表进行重新采样;第三,基于本地可用的数据运行推荐算法,以获得新的或更新以前生成的推荐评级结果。
传播和过滤的传播过程通过特殊的方式在邻近的智能手机之间建立无线连接,交换相似数据和邻域首选项列表,然后终止连接。此时网络拓扑结构基本上是断开的,没有可利用的对等关系信息(例如,社交网络、推荐系统或车辆网络中的对等网络重叠情况等)。能够访问到的对等方的数据总量由连接时间和对等方公开的数据量所决定。
Gossip 协议需要一个连接的对等网络以便聚合相似的对等设备,同时通过对等采样保持网络连接。在传统的分散推荐系统中,为了实现对等采样,即使项目和对等设备都不在邻域空间内,即它们在网络中随意移动,仍需要保证网络连接。当一个对等设备从一个类似的对等设备接收数据时,会重新取样他/她的邻域偏好列表;如果不是相似对等节点,则什么也不做。因此,传播和过滤会创建一个恒定的项目推荐清单,清单能够在相似的对等设备之间流转,而不会在不同的对等设备之间流转。该属性允许在从未在地理位置上彼此接近的对等设备之间传递信息,并避免不同对等节设备间的信息传输。从这个意义上讲,传播和过滤解决了普适推荐系统容易出现的数据稀缺性问题。
基于本文的算法已经开发完成了一个 android
本文应用场景数据为在 IMDb 中注册和唯一标识的电影。电影的评分结论为 1 到 5 星不等,并以格式如下格式存储:(用户 ID、电影 ID、评分数据)。电影分级列表实现了对等首选项列表。一旦用户完成了评级打分,他/她就可以激活共享。
本文进行了六个不同的实验,设备为 Nexus 5 智能手机,手机具备最新的蓝牙版本(包括 BLE)和 Wi-Fi 连接功能。
a. 大量评分数据共享:共享评分数据约为 1000 条,大小为 100KB。一旦建立连接,全部 1000 条数据同时立刻传输,且不会丢失任何数据。
b. 在多个设备之间共享数据:在四个智能手机之间共享评分数据,这四个手机的评分是独立不相交的。评分数据得以正确和无损的传输。
c. 公共交通工具中的数据共享:我们成功地在柏林的公交车和地下铁的三个设备之间共享评分数据,这些设备暴露在许多 WiFi 和蓝牙干扰信号下。实验表明,瞬时的网络连接中断并不会影响数据传输。一旦重新建立网络连接,共享的占位推荐信息被经由开放电影数据库(http://www.omdbapi.com/)API 获取得到的电影元数据填充。
d. 有效传输范围:在包含蓝牙、BLE、Wifi 等通信 API 条件下,二类设备例如手机等一般有效的传输半径为 10 米。本文在室内和户外 3 至 12 米无障碍半径范围内进行实验,实验结果见表 1。实验结论是,评分数据的有效传播半径在 3 到 6 米之间。
e. 平均初始连接延迟:
测量两个设备的初始连接延迟,即在建立连接之前所需的时间。
为保证成功连接,设备之间距离为 1 米,连接是通过不同的应用程序实现的(待连接设备的 ID 不在缓存中)。
平均连接延迟为 25.9 秒,最小连接延迟为 11 秒,最大连接延迟为 41 秒。
f. 电池耗尽:由于广播和发现步骤(预连接)必须连续执行,因此通过实验验证长时间在后台进行广播、发现和共享信息是否可行。由于无法模拟现实场景,因此只测量应用程序的预连接电池消耗量,这就为电池消耗量提供了一个下限。将两个设备重置为出厂设置。跟踪三种不同情况下的电池电量:(1)在后台运行并打开共享的应用程序;(2)关闭共享的应用程序;(3)出厂设置条件下,在所有三种情况下,显示器都关闭。实验结果见表 2。
实验结果表明,本文提出的传播-过滤策略在大规模评分数据和多设备交互的情况下,以及在诸如地铁等没有互联网连接的地区,都可以可靠工作。当然,该策略目前还存在一定的局限性。首先,数据的可靠传输半径为 6 米,这一方面加强了隐私保护,另一方面却限制了能够共享数据的潜在对等设备的数量。第二,平均初始连接延迟(25.9 秒)过长,这就造成了经过的行人之间,或在红绿灯处等待、在咖啡馆或餐厅中彼此相邻或乘坐公共交通工具等场景中该策略都不适用。第三,电池的耗电量相对较高,每小时至少耗电 5%,这就造成无法持续广播和发现。
后续工作重点是启动移动应用程序来收集使用数据。本文中的策略对采样过程和推荐算法都采用保留占位符的方式,一旦能够收集使用数据,就可以测试采样和推荐策略的不同组合。此外,还将继续收集和评估用户对应用程序的反馈,包括用户界面和用户体验等。
作者介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content @jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于RecSys提前看 | 深度学习在推荐系统中的最新应用的主要内容,如果未能解决你的问题,请参考以下文章
RecSys2020-推荐系统顶会论文大集锦
学习推荐系统必看的10篇RecSys论文,收藏!(官方推荐)
推荐系统一个吹NB的方法
推荐系统一个吹NB的方法
三年四大顶会,深度推荐系统18篇论文只有7个可以复现
项目总结ACM Recsys2019