独家 | COVID-19:利用Opencv, Keras/Tensorflow和深度学习进行口罩检测
Posted 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独家 | COVID-19:利用Opencv, Keras/Tensorflow和深度学习进行口罩检测相关的知识,希望对你有一定的参考价值。
翻译:张一然
校对:冯羽
很多读者要求我写一篇相关博客;
看到其他人有相关的实验(其中我最欣赏的是Prajna Bhandary的实现,也就是我们今天要用到的)。
检测图片中的COVID-19口罩;
检测实时视频流中的口罩。
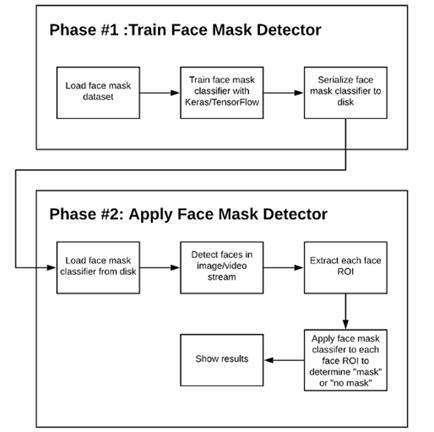
图一: 使用Python,OpenCV和TensorFlow/ Keras构建具有计算机视觉和深度学习功能的COVID-19口罩检测器的阶段和各个步骤。
训练:在该阶段我们主要是从磁盘加载口罩检测数据集,在该数据集上训练模型(使用Keras / TensorFlow),然后将模型序列化到磁盘;
部署:训练完口罩检测器后,加载训练好的口罩检测器,进行人脸检测,然后将人脸分类为戴口罩或不戴口罩。

图2:口罩检测数据集由“戴口罩”和“不戴口罩”图像组成。我们将使用该数据集,以及Python,OpenCV和TensorFlow/ Keras构建一个口罩检测器。
戴口罩: 690张图片;
不戴口罩: 686张图片。
最好的情况——她可以利用自己的项目来帮助他人;
最坏的情况——这给了她急需的心理逃生。
拍摄正常的脸部图像;
创建一个Python脚本向图片中的人脸添加口罩,从而创建一个人造的(但仍适用于现实世界)数据集。
眼
眼眉
鼻子
嘴
颚线

图3:要构建COVID-19口罩数据集,我们首先从不戴口罩的人的照片开始。

图4:下一步是应用人脸检测。在这里,我们借助了深度学习和OpenCV进行人脸检测。


图6:然后,我们使用dlib检测面部标志,找到将口罩放置在脸上的位置。

图7:COVID-19 口罩的示例。由于我们知道面部标志位置,因此可将该口罩自动覆盖在人脸的ROI上。

图8:在此图中,我们已将口罩添加到人脸上。不仔细看的话我们很难看出口罩是通过opencv和dlib面部标志人为添加上去的。

图9:展示了一组人工制作的COVID-19口罩图像。这将成为我们“戴口罩” /“不戴口罩”数据集的一部分,该数据集将被用于使用Python、OpenCV、Tensorflow/Keras的计算机视觉和深度学习技术训练的COVID-19面部口罩检测器。
参考Prajna的GitHub;
参考PyImageSearch上另一篇教程,如何利用面部标志自动将太阳镜戴在人脸上(https://www.pyimagesearch.com/2018/11/05/creating-gifs-with-opencv/)。
$ tree --dirsfirst --filelimit 10
.
├── dataset
│ ├── with_mask [690 entries]
│ └── without_mask [686 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── detect_mask_image.py
├── detect_mask_video.py
├── mask_detector.model
├── plot.png
└── train_mask_detector.py
5 directories, 10 files
train_mask_detector.py:接受输入数据,精调MobileNetV2,创建make_detector.model。同时以图片的形式输出训练过程中的准确度/损失曲线;
Detect_mask_image.py:在静态图片上进行口罩检测;
Detector_mask_video.py:此脚本将口罩检测应用于视频流中的每一帧。
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
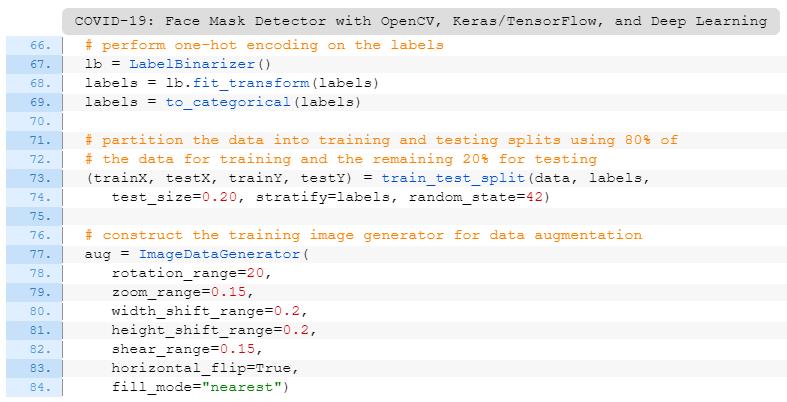
数据增强;
加载MobilNetV2分类器(我们将使用预训练的ImageNet权重对该模型进行精调);
建立一个新的全连接(FC)头;
预处理;
加载图像数据。
如何在Ubuntu上安装TensorFlow2.0;
如何在macOS上安装TensorFlow2.0。
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to output face mask detector model")
args = vars(ap.parse_args())
--dataset:人脸和戴口罩的人脸的输入数据集的路径;
--plot:输出训练过程图的路径,将使用matplotlib生成这些图;
--model:生成的序列化口罩分类模型的路径。
# initialize the initial learning rate, number of epochs to train for,
# and batch size
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
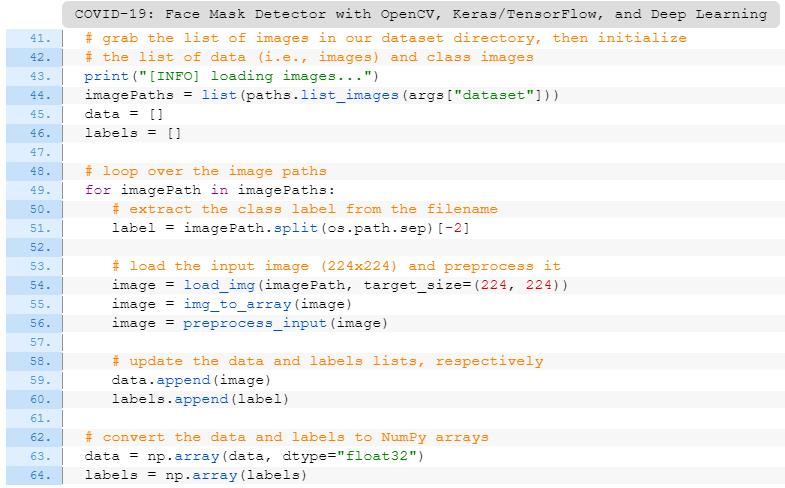
抓取数据集中的所有imagePath(第44行);
初始化数据和标签列表(第45和46行);
循环遍历imagePaths并加载+预处理图像(第49-60行)。预处理步骤包括将尺寸调整为224×224像素,转换成数组格式并将输入图像中的像素值缩放到[-1,1]范围(通过preprocess_input函数);
将预处理的图像和相关标签分别添加到数据和标签列表中(第59行和第60行);
确保我们的训练数据是NumPy数组格式(第63和64行)。
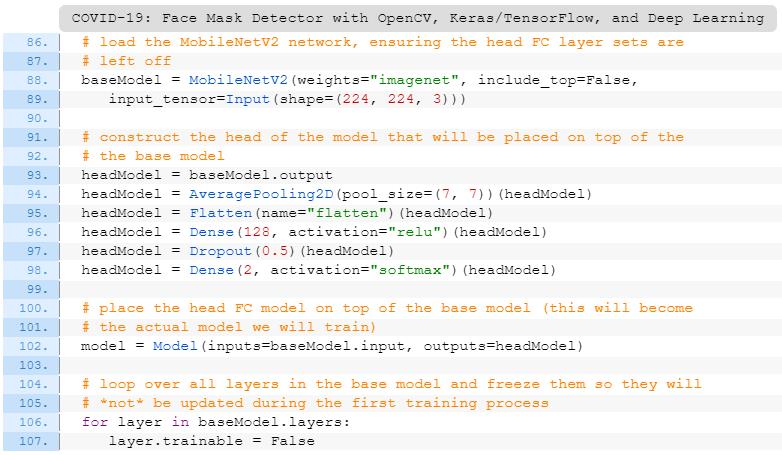
向MobileNet加载预训练的ImageNet权重,而不用担心网络的损失(第88和89行);
构造一个新的全连接层,并将其附加到模型最后以代替旧的全连接层(第93-102行);
冻结网络的基础层(106和107行)。这些基础层的权重在反向传播过程中不会更新,而顶层的权重将被调整。

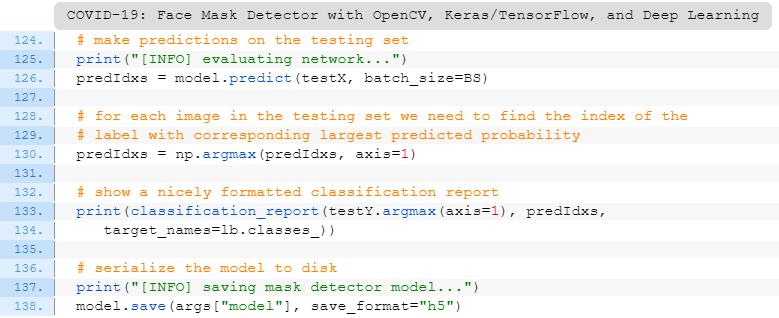
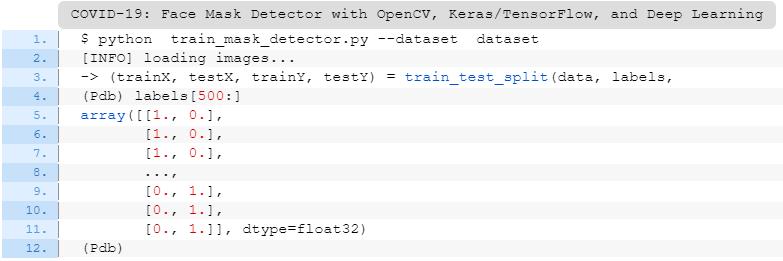
$ python train_mask_detector.py --dataset dataset
[INFO] loading images...
[INFO] compiling model...
[INFO] training head...
Train for 34 steps, validate on 276 samples
Epoch 1/20
34/34 [==============================] - 30s 885ms/step - loss: 0.6431 - accuracy: 0.6676 - val_loss: 0.3696 - val_accuracy: 0.8242
Epoch 2/20
34/34 [==============================] - 29s 853ms/step - loss: 0.3507 - accuracy: 0.8567 - val_loss: 0.1964 - val_accuracy: 0.9375
Epoch 3/20
34/34 [==============================] - 27s 800ms/step - loss: 0.2792 - accuracy: 0.8820 - val_loss: 0.1383 - val_accuracy: 0.9531
Epoch 4/20
34/34 [==============================] - 28s 814ms/step - loss: 0.2196 - accuracy: 0.9148 - val_loss: 0.1306 - val_accuracy: 0.9492
Epoch 5/20
34/34 [==============================] - 27s 792ms/step - loss: 0.2006 - accuracy: 0.9213 - val_loss: 0.0863 - val_accuracy: 0.9688
...
Epoch 16/20
34/34 [==============================] - 27s 801ms/step - loss: 0.0767 - accuracy: 0.9766 - val_loss: 0.0291 - val_accuracy: 0.9922
Epoch 17/20
34/34 [==============================] - 27s 795ms/step - loss: 0.1042 - accuracy: 0.9616 - val_loss: 0.0243 - val_accuracy: 1.0000
Epoch 18/20
34/34 [==============================] - 27s 796ms/step - loss: 0.0804 - accuracy: 0.9672 - val_loss: 0.0244 - val_accuracy: 0.9961
Epoch 19/20
34/34 [==============================] - 27s 793ms/step - loss: 0.0836 - accuracy: 0.9710 - val_loss: 0.0440 - val_accuracy: 0.9883
Epoch 20/20
34/34 [==============================] - 28s 838ms/step - loss: 0.0717 - accuracy: 0.9710 - val_loss: 0.0270 - val_accuracy: 0.9922
[INFO] evaluating network...
precision recall f1-score support
with_mask 0.99 1.00 0.99 138
without_mask 1.00 0.99 0.99 138
accuracy 0.99 276
macro avg 0.99 0.99 0.99 276
weighted avg 0.99 0.99 0.99 276
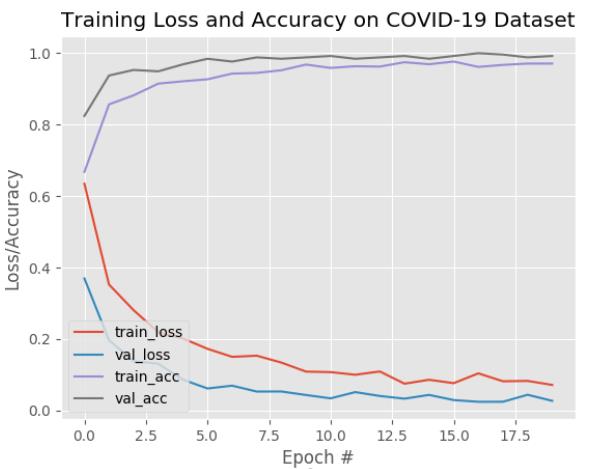
图10:COVID-19口罩检测器的训练精度/损失曲线显示出模型具有很高的准确率,并且在数据上几乎没有过拟合的迹象。现在,我们准备使用Python,OpenCV和TensorFlow/ Keras并应用我们的计算机视觉和深度学习知识来执行口罩检测。
从磁盘加载输入图像;
检测图像中的人脸;
应用我们的口罩检测器将人脸分类为戴口罩或不戴口罩。
# import the necessary packages
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to trained face mask detector model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
--image:输入图像的路径,其中包含用于推理的人脸图像;
--face:人脸检测模型目录的路径(我们需要先对人脸进行定位,然后再对其进行分类);
--model:口罩检测器模型的路径;
--confidence:可选项将概率阈值设置为覆盖50%,以过滤较差的人脸检测结果。
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the face mask detector model from disk
print("[INFO] loading face mask detector model...")
model = load_model(args["model"])
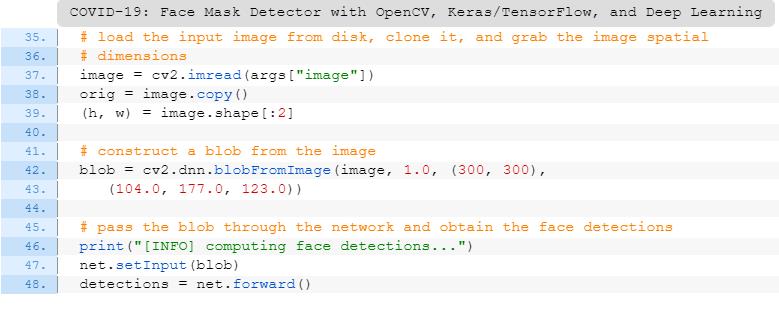

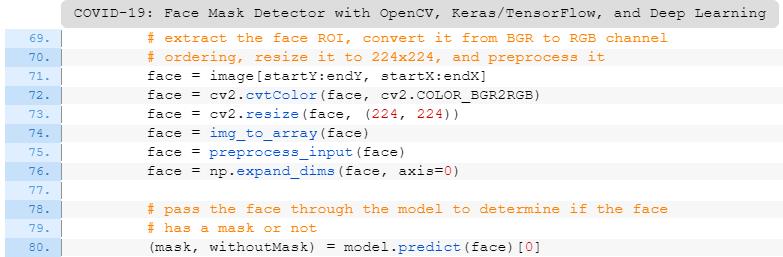
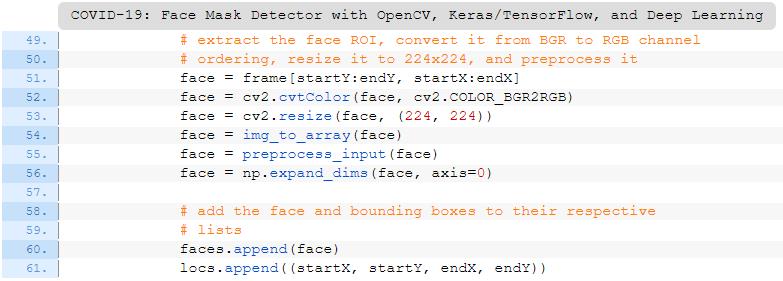
通过NumPy切片提取面部ROI(第71行);
采用与训练期间相同的方式对ROI进行预处理(第72-76行);
执行口罩检测以预测“戴口罩”或“不戴口罩”(第80行)。
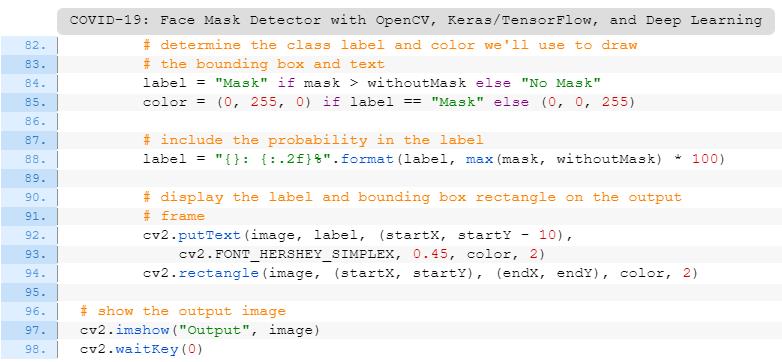
$ python detect_mask_image.py --image examples/example_01.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
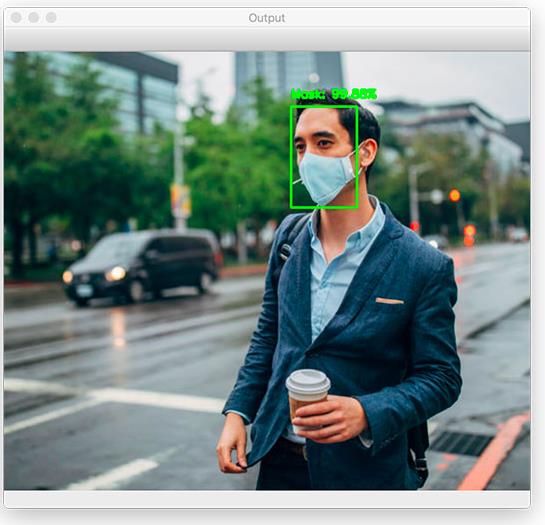
图11:这个男人在公共场所带口罩了吗?可以看出,我们的检测器检测到图中的人带着口罩. 使用Python,OpenCV和TensorFlow/ Keras的计算机视觉和深度学习方法使自动检测口罩成为可能。(图片来源:https://www.sunset.com/lifestyle/shopping/fashionable-flu-masks-germ-protection)
$ python detect_mask_image.py --image examples/example_02.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
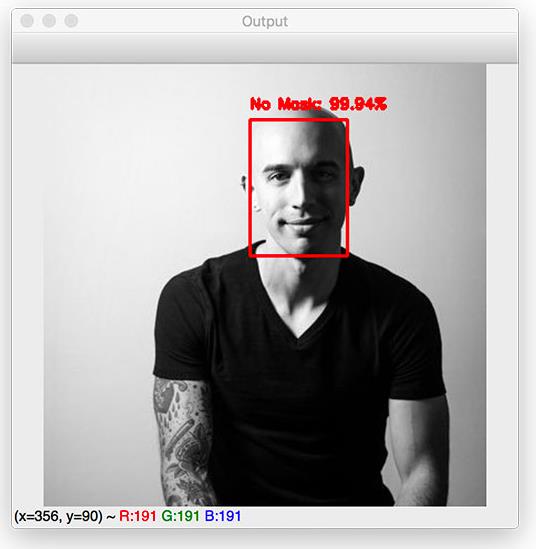
图12:我在这张照片中没有戴口罩。使用Python,OpenCV和TensorFlow/ Keras,我们的系统已正确检测到我的脸部为No Mask(“无口罩”)。
$ python detect_mask_image.py --image examples/example_03.png
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] computing face detections...
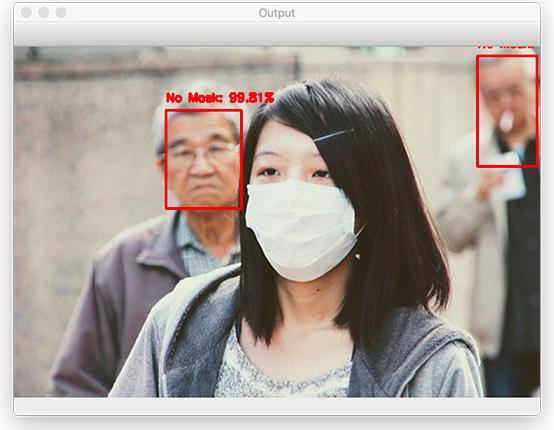
图13:为什么未检测到前景中的女士戴着口罩?使用Python,OpenCV和TensorFlow/ Keras构建的具有计算机视觉和深度学习功能的面罩检测器是否无效?(图片来源:https://www.medicaldevice-network.com/news/coronavirus-outbreak-mask-production/)
口罩遮盖区域太大;
用于训练人脸检测器的数据集不包含戴口罩的人脸示例图像。
# import the necessary packages
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from imutils.video import VideoStream
import numpy as np
import argparse
import imutils
import time
import cv2
import os
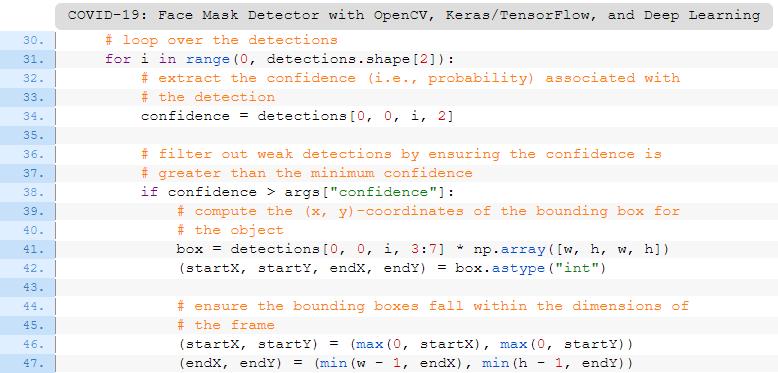
def detect_and_predict_mask(frame, faceNet, maskNet):
# grab the dimensions of the frame and then construct a blob
# from it
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),
(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
faceNet.setInput(blob)
detections = faceNet.forward()
# initialize our list of faces, their corresponding locations,
# and the list of predictions from our face mask network
faces = []
locs = []
preds = []
帧:我们信息流中的帧;
faceNet:用于检测人脸在图像中的位置的模型;
maskNet:我们的COVID-19口罩分类器模型。
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--face", type=str,
default="face_detector",
help="path to face detector model directory")
ap.add_argument("-m", "--model", type=str,
default="mask_detector.model",
help="path to trained face mask detector model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
--face:人脸检测器目录的路径;
--model:训练好的口罩分类器的路径;
--confidence:用来过滤较差检测的最小概率阈值。
# load our serialized face detector model from disk
print("[INFO] loading face detector model...")
prototxtPath = os.path.sep.join([args["face"], "deploy.prototxt"])
weightsPath = os.path.sep.join([args["face"],
"res10_300x300_ssd_iter_140000.caffemodel"])
faceNet = cv2.dnn.readNet(prototxtPath, weightsPath)
# load the face mask detector model from disk
print("[INFO] loading face mask detector model...")
maskNet = load_model(args["model"])
# initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
人脸检测器;
COVID-19口罩检测器;
网络摄像头视频流。

展开人脸边界框和戴口罩/不戴口罩的预测(第117和118行);
确定标签和颜色(122-126行);
注释标签和面边界框(第130-132行)。
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
$ python detect_mask_video.py
[INFO] loading face detector model...
[INFO] loading face mask detector model...
[INFO] starting video stream...
训练数据有限;
人工生成的戴口罩数据集(请参见上面的“如何创建我们的面罩数据集?”部分)。
步骤1:执行人脸检测;
步骤2:对每张脸进行口罩检测。
如您想与我们保持交流探讨、持续获得数据科学领域相关动态,包括大数据技术类、行业前沿应用、讲座论坛活动信息、各种活动福利等内容,敬请扫码加入数据派THU粉丝交流群,红数点恭候各位。

译者简介
张一然,哥本哈根大学计算机系硕士毕业,研究方向为图像补全。现从事自然语言处理工作。感兴趣方向为计算机视觉和自然语言处理,喜欢看书旅游。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织
以上是关于独家 | COVID-19:利用Opencv, Keras/Tensorflow和深度学习进行口罩检测的主要内容,如果未能解决你的问题,请参考以下文章
observablehq 美国 COVID-19 确诊数曲线
observablehq 美国 COVID-19 确诊数曲线
自然语言处理基于 LDA 和 BERTopic 的 COVID-19 论文内容分析