自然语言处理基于 LDA 和 BERTopic 的 COVID-19 论文内容分析
Posted 皮皮要HAPPY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理基于 LDA 和 BERTopic 的 COVID-19 论文内容分析相关的知识,希望对你有一定的参考价值。
基于 LDA 和 BERTopic 的 COVID-19 论文内容分析
关于 COVID-19 的研究不胜枚举,截至 2022 年初,已发表了超过 800000 800000 800000 篇与 COVID-19 相关的论文。对这些论文进行梳理是一项非常具有挑战性的任务,但这可以帮助我们确定哪些领域可以更多的从研究或研究基金中受益。在本文中,我将评估这些 COVID-19 研究论文的主题,尝试揭示这些统计数据和趋势。
数据集来自 The COVID-19 Open Research Dataset (CORD-19),该数据集包含了与冠状病毒研究或 COVID-19 大流行相关的学术论文语料库。 CORD-19 数据集旨在支持文本挖掘和 NLP 研究,并为评估 COVID-19 大流行的主题提供良好开端。
尽管获取 CORD-19 数据相对不难,但因数据质量问题仍要进行数据清洗,具体的数据清洗过程细节不在本文讨论范围内。我仅保留 2020 年初 COVID-19 爆发后发表的论文,并要求摘要至少提及一个与 COVID-19 相关的关键词,同时只保留英文论文。经分析,CORD-19 数据集中只有 0.8% 的论文是用非英语语言撰写的。经筛选后得到了大约 215000 215000 215000 篇与 COVID-19 相关的论文摘要样本。
第一个目标是确定这些 COVID-19 论文样本中研究的主题。许多 COVID-19 论文都是关于医学主题的,其中包含了大量医学术语,需要大量的背景知识才能理解。鉴于个人背景,我仅专注于与一般方面相关的 COVID-19 论文,例如对经济、信息传输、工作和学习方式的影响。我将这些非医学论文称为 “社科论文”。为此创建一个两步识别过程,首先将社科论文和医学论文分开,然后专注于发现社科论文的子主题。
为了从医学论文中识别社科论文,首先在大约 25000 25000 25000 篇论文上训练了一个 LDA 模型。 LDA 模型是适合该任务的主题建模方法,它具有足够的判别能力,能将社科论文与医学论文分开,是一种有效方法。经过一些实验后,我选择了一个包含 10 10 10 个集群的模型,如下图所示。我评估了每个集群中的热门关键词,并将集群 5 5 5、 6 6 6 和 10 10 10 标记为社科论文。在所有的论文摘要上应用 LDA 模型后,如果社科集群的概率总和超过 50 % 50\\% 50%,则将一篇论文归类为社科论文。最后一共得到大约 66000 66000 66000 篇讨论社会话题的 COVID-19 论文。
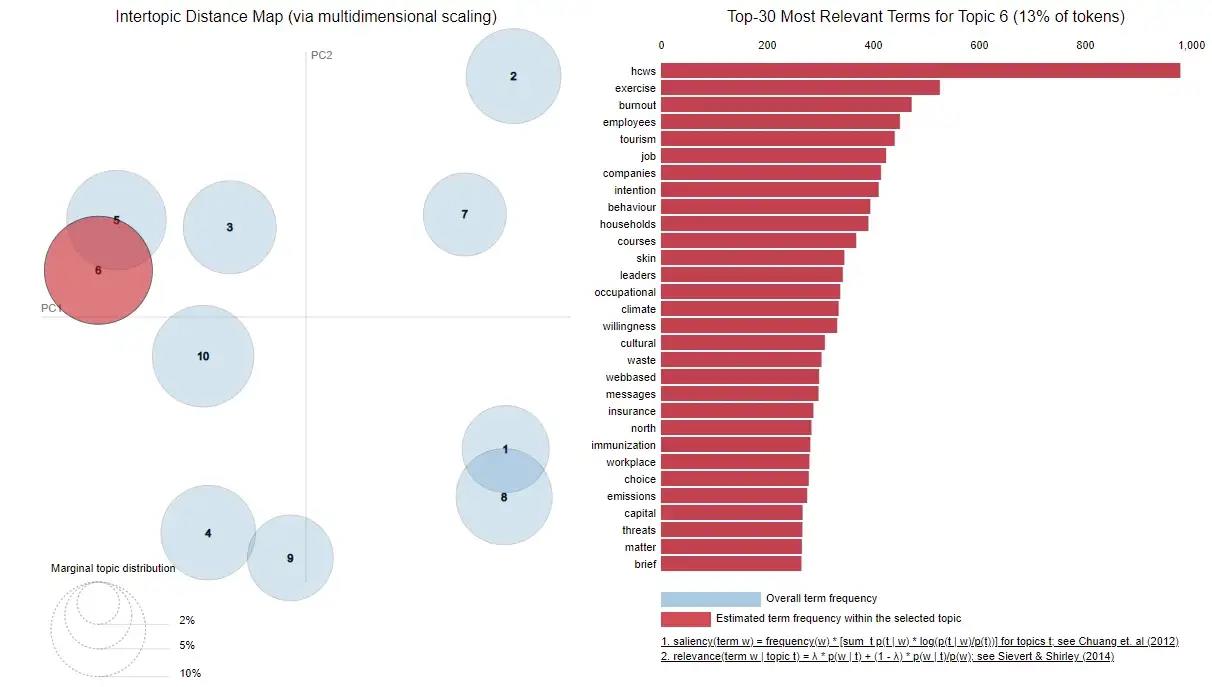
识别出社科 COVID-19 论文样本后,就该发现该数据集中的子主题了!
起初,我尝试运行另一个 LDA 模型,但集群并不是特别有意义。这可能是由于 LDA 模型缺乏将领域特定词概括为更高级别潜在主题的能力。为了克服这个问题,我决定使用一种基于迁移学习的替代主题建模方法,称为 BERTopic。
BERTopic 方法使用预训练的语言模型(例如 BERT)来识别无监督主题集群。这些迁移学习模型通常拥有比从头开始训练的传统模型更好的性能,因为它使模型能够合并文本关系和相似性。此处使用的是 BERTopic Python 包。在社科论文摘要上训练 BERTopic 模型后,得到了一个非常好的结果!如下图所示(在线查看):

使用 BERTopic 的一个好处是,无需一开始就确定模型要预测多少主题。在这些社科论文摘要上训练 BERTtopic 模型后,最终得到了 500 500 500 多个主题。人工检查表明某些主题重叠并代表同一事物。为了解决这个问题,可以强制 BERTopic 将主题数量减少到固定的 100 100 100 来对相似的主题进行分组。可以查看生成的集群的热门关键词:
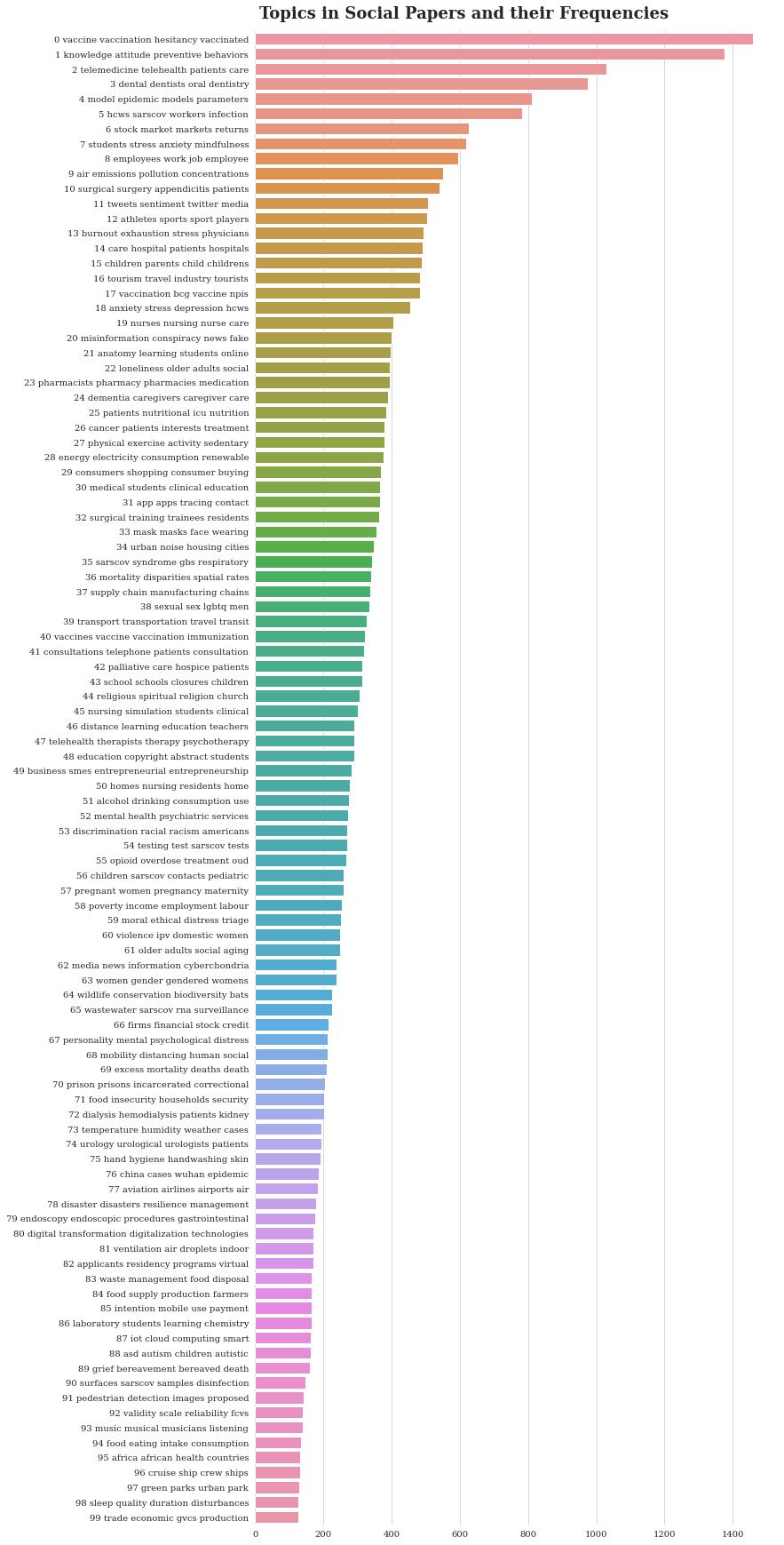
上面的条形图显示 BERTopic 模型识别的主题与我们在日常大流行病对话中谈论的主题非常吻合。例如,最常见的两个话题与疫苗和其他预防措施有关。一个有趣的结果是,第 4 4 4 大热门话题与牙科护理有关。与经济相关的主题经常被研究,如主题 6 6 6 涉及股票市场,主题 8 8 8 涉及就业。压力和心理健康也经常被研究(主题 7 7 7 和 13 13 13)。在线学习和育儿在主题 15 15 15 和 21 21 21 中进行了讨论。该图表还强调了一些关键但未被充分研究的主题,例如 COVID-19 对非洲国家(主题 95 95 95)和自闭症儿童(主题 88 88 88)的影响。
除了 COVID-19 论文中涵盖的主题外,以国家作为研究对象也很有趣。预计会有更多关于受 COVID-19 大流行影响更严重的国家的论文。为了评估这种期望,我创建了一个国家名称列表,并计算每个国家在论文摘要中被提及的次数。为了代表 COVID-19 大流行的影响,我使用该国家 / 地区累计的 COVID-19 病例数和人均病例数。 COVID-19 病例数据取自 世界卫生组织。调查结果如下图所示(在线查看):

上面的可视化显示了基于除 China 以外的六个世卫组织(WHO)区域的树状图。有超过 14000 14000 14000 篇论文在摘要中提到了 China,但人工检查表明,其中许多提及仅是指出 COVID-19 的首次爆发发生在 China,而不是以 China 为研究对象。所以,为了避免错误分类,并未将 China 考虑进来。树图中区域的大小表示截至 2021 2021 2021 年 12 12 12 月 20 20 20 日累计 COVID-19 病例数。区域的颜色表示摘要中提到国家名称的论文数量,颜色越深,数量越多。
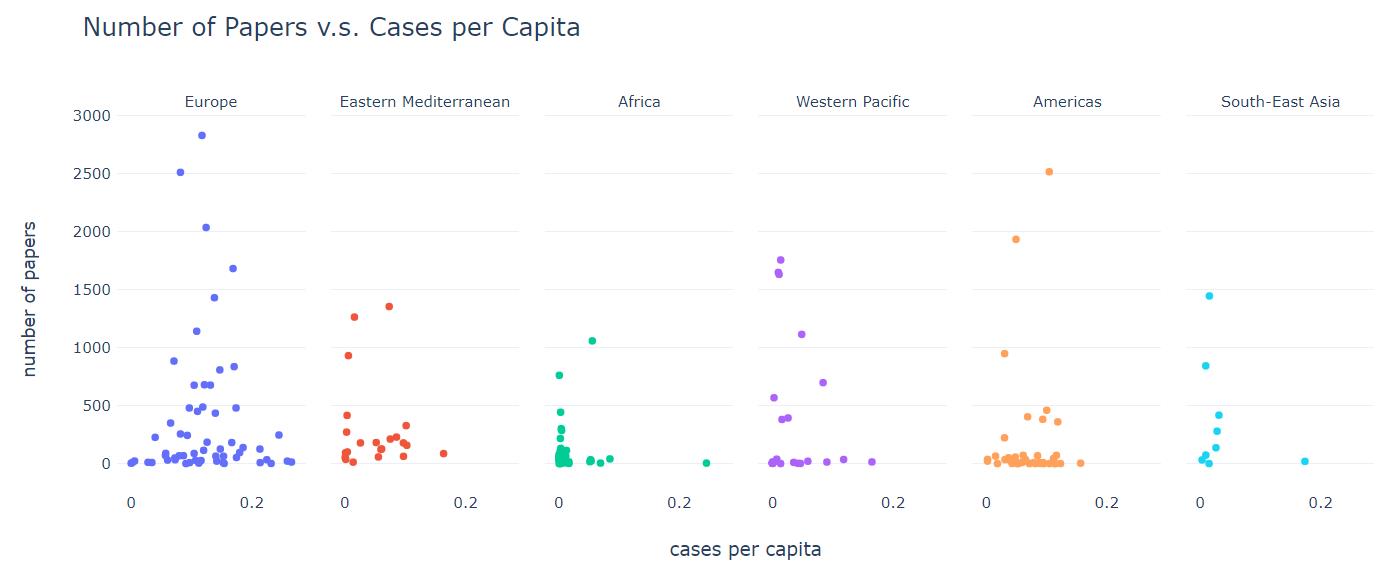
论文最多的国家是美国,并且使用文中的方法甚至可能低估了研究美国的论文数量;大多数没有提到国家主题的论文实际上都是在研究美国数据。意大利和印度的论文数量也很高,其次是巴西、法国、德国和西班牙。该图还表明案例数量与论文数量呈正相关。然而,需要注意的是,一些国家,尤其是较小的发展中国家,可能没有足够的资源来正确确定确诊病例的数量。
下面的散点图表明了论文数量与人均 COVID-19 病例数之间的关系(在线查看)。分别为每个 WHO 区域绘制图表。为了使结果更准确,中国、印度、意大利和美国不在可视化考虑范围内,因为它们都有不成比例的关于它们的论文。散点图的结果类似于树状图。欧洲的散点图大致呈钟形分布,反映了欧洲国家人均病例的多样性。这些欧洲国家的论文也比较多。大多数其他地区的论文数量较少,即使人均案例相对较高。这表明这些国家可能未被充分研究,至少在英国研究文献中是这样。
本文代码已上传至 我的GitHub,需要可自行下载。
以上是关于自然语言处理基于 LDA 和 BERTopic 的 COVID-19 论文内容分析的主要内容,如果未能解决你的问题,请参考以下文章