使用深度学习建立电影推荐系统,不到10分钟即可进行DIY!
Posted 智榫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用深度学习建立电影推荐系统,不到10分钟即可进行DIY!相关的知识,希望对你有一定的参考价值。
来源丨AI研习社
本文已获授权
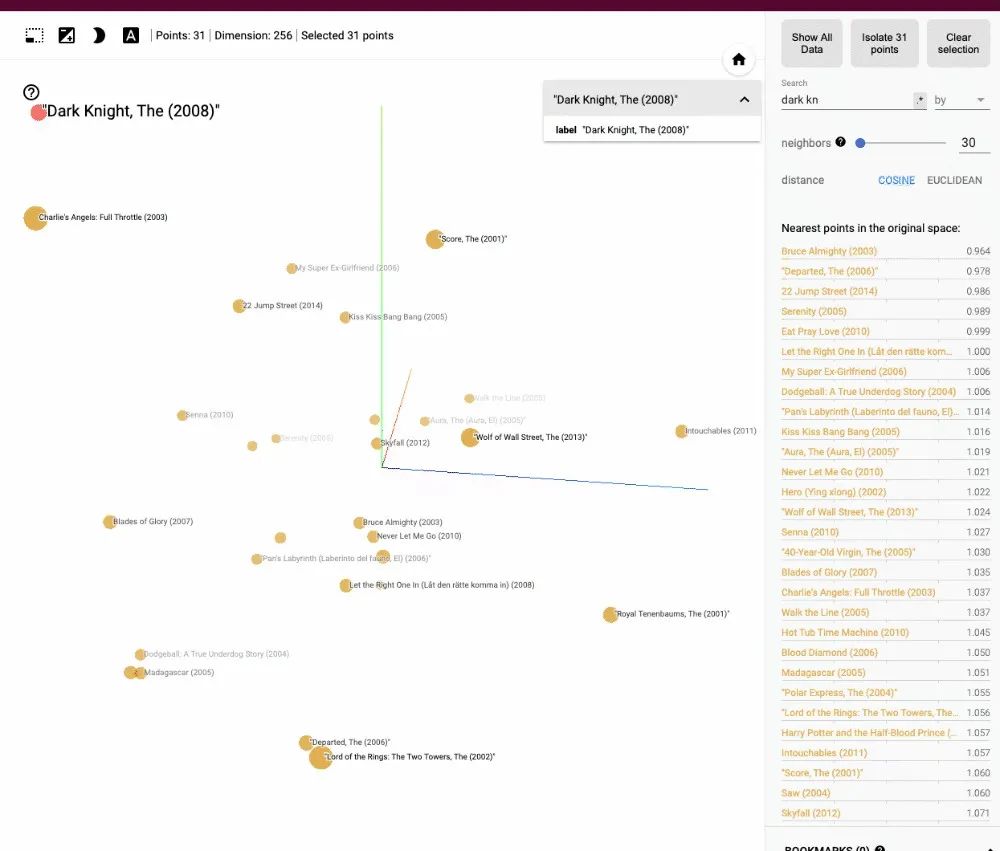
1
Embedding
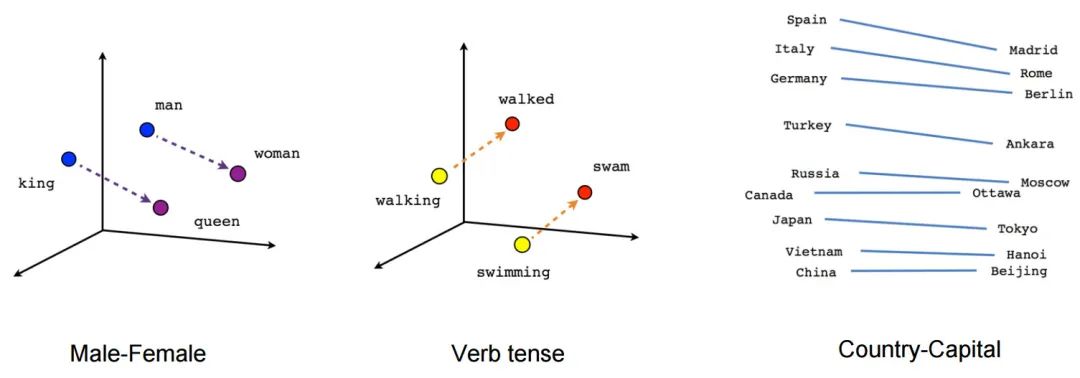
Tensorboard Projector
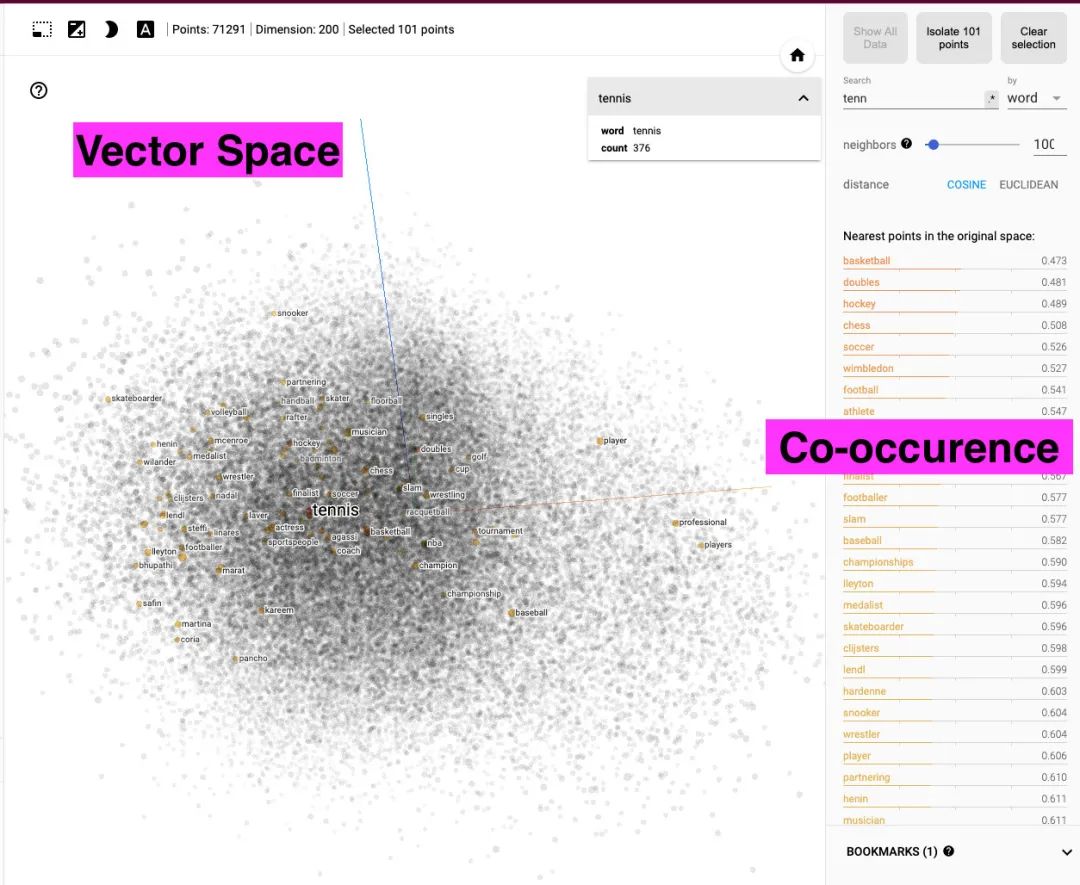
降维算法
MovieLens数据集
基于流行度:标识过去X时段内最受欢迎(观看最多)的电影,将这些电影推荐给所有用户。
基于电影属性:根据电影的元标记(如演员,导演,语言,发行年份等)进行推荐。但这样的缺点是,电影的属性不会随时间改变,无法考虑用户行为进行实时推荐。
基于用户:根据用户的观看模式和喜好,对用户进行分组,为用户推荐同组内其他用户观看的电影。例如,如果我观看了Inception和Dark Knight,其他看过这两部电影的人也喜欢看Prestige,那么推荐给我Prestige是较好的选择。

|
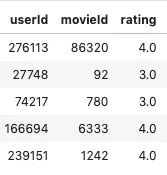
for i in range(0,size): #print(kw[0][i].split(" ")) string=kw[i].split(",") #print(string) base=base+string if(len(base)>2): base = ','.join(base) return base s_test=links s_test=s_test[['userId','movieId']].drop_duplicates() s_test['keywords_comb']=s_test.groupby(['movieId'])['userId'].transform(combine) print("Start of Word2Vec",datetime.now().strftime('%Y-%m-%d %H:%M:%S')) data=s_test[['movieId','keywords_comb']].drop_duplicates() data['word_count'] = data.keywords_comb.str.count(',')+1 data=data[data['word_count']>5] data['tokenise'] = data['keywords_comb'].astype('str').apply(lambda x: [x for x in x.split(',')]) a1=data['tokenise'].tolist() model_items = Word2Vec(a1, size=100) #data=data.dropna() print("Start of Sentence To vec",datetime.now().strftime('%Y-%m-%d %H:%M:%S')) sent=data['keywords_comb'].astype('str').apply(lambda x: [x for x in x.split(',')]).tolist() s = IndexedList(sent) from fse.models import uSIF model = uSIF(model_items, lang_freq="en") |

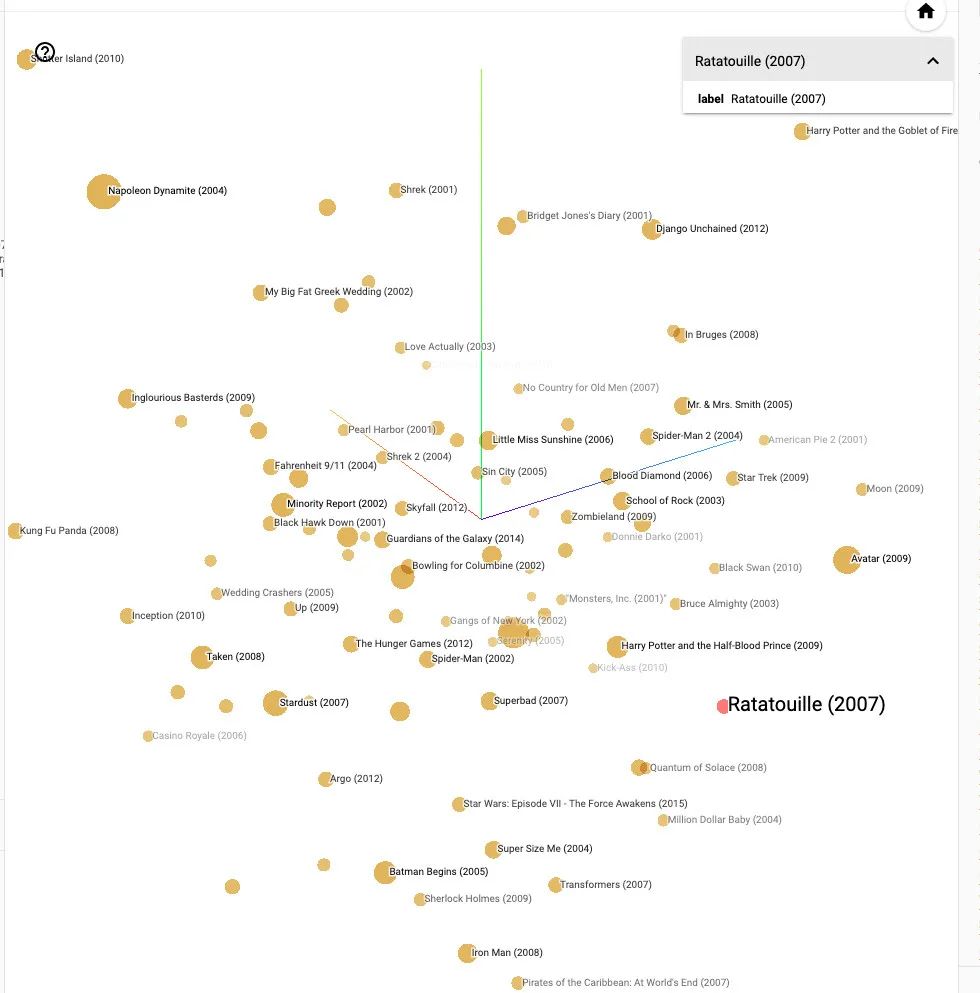
2
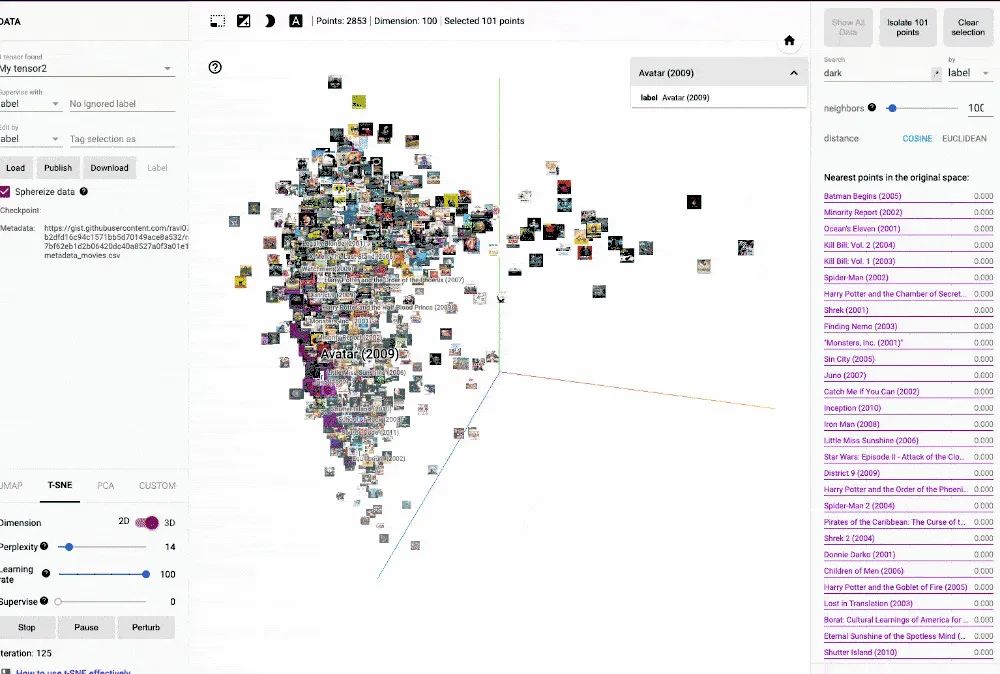
AI研习社双语原文:https://www.yanxishe.com/TextTranslation/2968
更多推荐
以上是关于使用深度学习建立电影推荐系统,不到10分钟即可进行DIY!的主要内容,如果未能解决你的问题,请参考以下文章 资源 | 主要推荐系统算法总结及Youtube深度学习推荐算法实例概括