技术丨深入浅出聊聊MapReduce
Posted BitTiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术丨深入浅出聊聊MapReduce相关的知识,希望对你有一定的参考价值。
欢迎回看本文原始视频
http://t.cn/Rj5XZgV
今天我们来一起聊一聊MapReduce,这是Google三剑客其中一篇,是Google大神Jeffrey的文章。

那我们再看一下这三个在一起是什么层次呢?最底层是文件系统GFS,往上是对文件的抽象,KeyValue以及上面逻辑层的推向就是Bigtable,我们今天讲的就是上面的算法MapReduce。

MapReduce
到底是什么呢?它用来做什么呢?
比如我们有1TB的数据,如何统计单词数?如何建立倒排索引?这其实是很复杂的过程,如果有10TB,或者1PB数据怎么办呢?这时候单机就没办法做,变得很复杂需要想办法来解决。很多人说这些可以自己单机写,单机写的过程甚至构建了一个MapReduce的系统,那怎么把它做的很通用就是文章所讲的事情。
什么是Map和什么是Reduce
Map的本质实际上是拆解,比如说有辆红色的小汽车,有一群工人,把它拆成零件了,这就是Map。
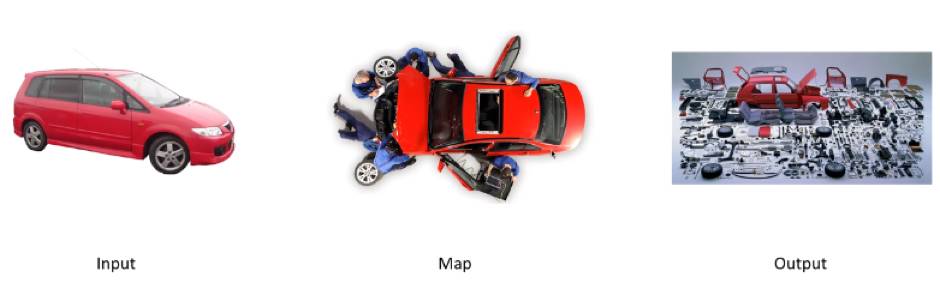
那什么是Reduce呢?Reduce就是组合,我们有很多汽车零件,还有很多其他各种装置零件,把他们一阵拼装,变成变形金刚,这就是Reduce。

什么是MapReduce
统合来看,MapReduce就是你有很多各种各样的蔬菜水果面包(Input),有很多厨师,不同的厨师分到了不同的蔬菜水果面包,自己主动去拿过来(Split),拿到手上以后切碎(Map),切碎以后给到不同的烤箱里,冷藏机里(Shuffle),冷藏机往往需要主动去拿,拿到这些东西存放好以后会根据不同的顾客需求拿不同的素材拼装成最终的结果,这就是Reduce,产生结果以后会放到顾客那边等待付费(Ticket),这个过程是Finalize。
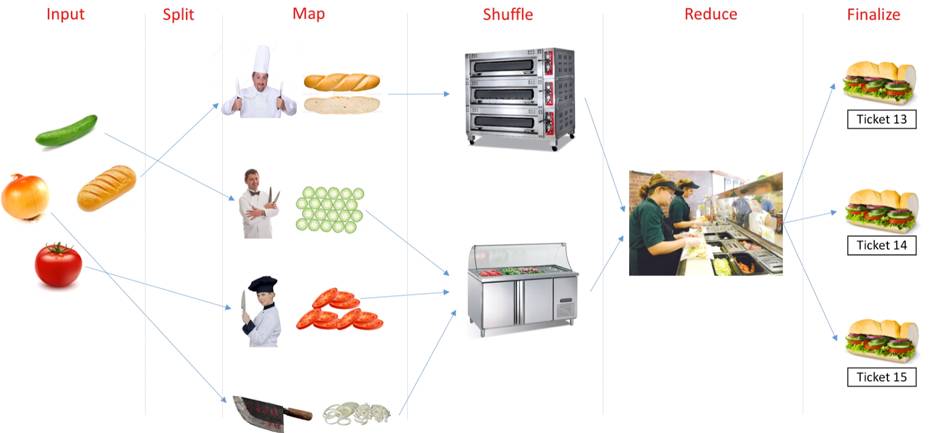
所以MapReduce是六大过程,简单来说:Input, Split, Map, Shuffle, Reduce, Finalize。
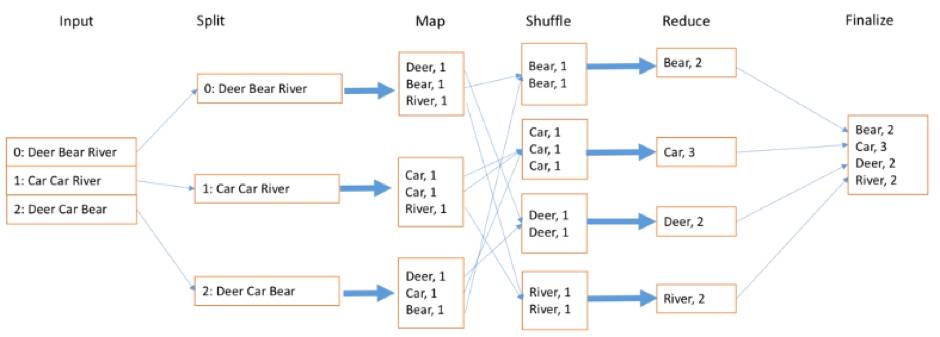
那如何统计1TB或1PB文件里的单词数呢?
我们输入很多文档,文档的每一行有很多不同的单词,我们找不同的worker拿到自己手上,就是Split过程,那怎么切分呢?每一行文档就切分成单词和它出现的次数,每次出现的次数是1,就写1。接下来Shuffle就是把不同的单词继续放到同样的盒子里面,Bear放一起,Car放一起,这可以由Shuffle写的时候算法来决定。当然现在很多智能都不用做了,有时候还需要随机采样的方式来实现。等到这个结果以后,最后一步Reduce,就是把相同的数据放一起,比如Car有3个就写3,River是2个就写2,最后再放到一起,这样便于提供服务,得到最终结果。大家可以看到最后箭头指过来是乱序的,也就是说这个执行过程实际上是高度并行的,也不用等待每个都完成,所以说这是一个很好的优化过程。
写一下代码是怎样的呢?

Map输入每一行的ID是key,value是这一行的单词。有这个结果以后就可以统计每个单词出现的次数。Reduce输入的还是各个单词,但后面跟的是一个串,是在里面出现的次数,1,1,1,我们把1加到一起就是sum的过程,这就是MapReduce的整个过程。输出我们的关键词和它的出现次数。
MapReduce怎么建立倒排索引?
首先输入很多的文档,这里面每一行的不是文档编号了,我们要存它的文档编号。拆解的时候我们加入新的概念,Worker,这里有三个Worker,每个Worker负责1行,当然有很多数据时每个Worker可以负责多行,每个Worker就需要进行Map拆解,把每个单词都拆成单词和出现的文档ID。接着Shuffle有两个新Worker,他们把单词一拆,一部分交个Worker4,一部分交给Worker5,让他们去前面拿数据,拿到以后会排个序,这也是最基本的Shuffle过程。接着就是Reduce,把相同的东西合并到一起去,比如food出现在两个文档里,就是0和2。最终就是把这些结果放到一起去就可以让我们查找了。
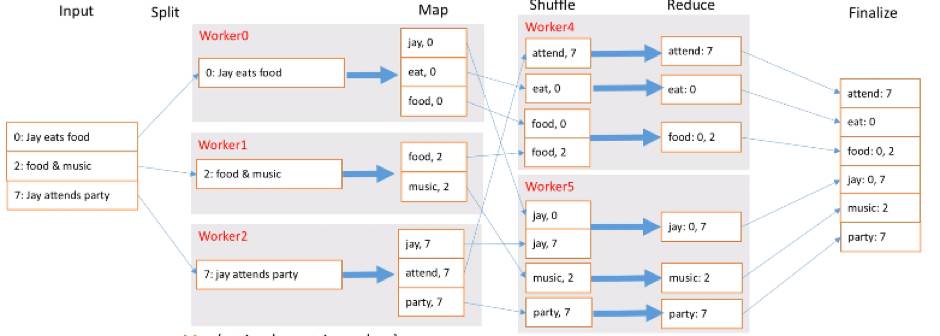
那什么是倒排索引?倒排索引就是每个单词出现在哪些文档里,这样就能快速检索。最终外部输入每行文档的ID及内容,我们可以把它拆解成单词出现在哪个文档里。Reduce过程输入是每个关键词key,输出是key出现在哪些文档里就放到一起。

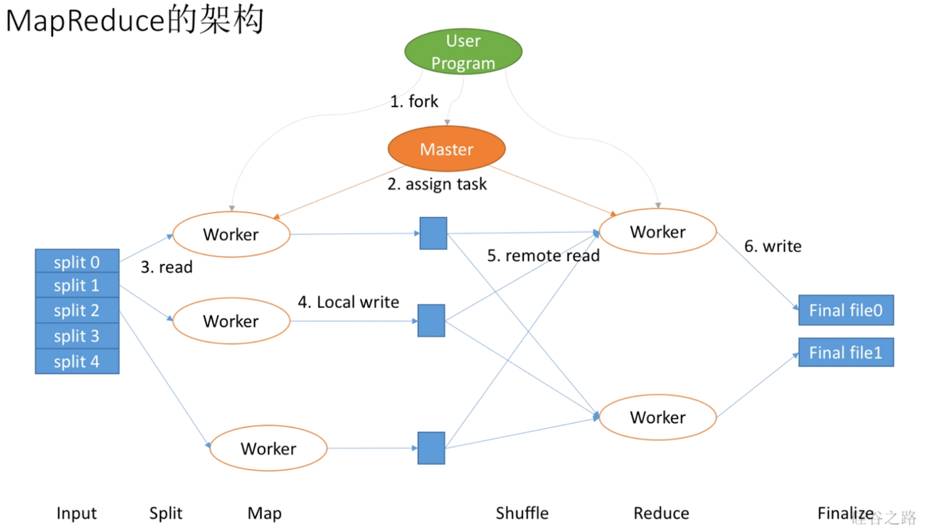
MapReduce架构是什么呢?
首先,我们有用户进程,它需要协调或者定义我们程序怎么运行,当然它不是自己运行,实际上它会先想数据有多少,需要拆解成多少个Mapper,多少个Reducer去做。比如要找5个Mapper去做,就会把数据拆成5份,这样会产生出很多很多Worker,会有Map Worker和Reduce Worker。但最重要的是还会产生一个Master Worker,这个和其他Worker等级是一样的,只不过会做一些特殊事情,它会作为用户的代理来协调整个过程,用户就可以做其他事情。Master Worker会让这个Worker去拿0号数据,一个Worker负责拿1号数据等等,这就是分配数据的过程。每个Worker会在本地把数据切分开吧,写到本地的缓存或者硬盘上行。前面Map Worker做完了,Master让Reduce Worker去拿数据,他们就会从各个Worker里拿到本地需要的数据,在本地做完Reduce以后将结果写到最终的文件里就是Finalize。实际上,这个过程可以看到第一步切数据是Input,第二步是Map拿数据Split,第三步自己切分就是Map,第四步Reduce去拿数据是Shuffle,第五步Reducer自己去做数据的整合是Reduce,第六步输出结果Finalize。
总结
MapReduce本质就是分治法
会刷题也要学会解决生活中的真实问题,成为一个真正解决问题成长的人。
MapReduce六大过程:来洋葱、拿洋葱、切洋葱、放洋葱、拼洋葱、送洋葱
参考资料:
《MapReduce: Simplified Data Processing on Large Clusters》
https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
全面掌握大数据方面的技能点
搭建工业级别大数据工程师项目
欢迎了解BitTiger 大数据工程师直通车
扫码或点击“阅读原文”
BitTiger直通车特色
- 三个月三个工业级别大项目,全面提升编程实力与简历背景
- 硅谷一线IT公司导师、了解痛点的助教,全方位指导及答疑
- 修改简历、模拟面试、职业咨询,Career Service全程护航
- 独家面试题库精讲、上百小时基础及面试视频资源助
以上是关于技术丨深入浅出聊聊MapReduce的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop技术内幕:深入解析YARN架构设计与实现原理pdf
2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理深入解析Hadoop Common和HDFS架构设计与实现原理