深入浅出MapReduce
Posted 刘元涛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出MapReduce相关的知识,希望对你有一定的参考价值。
本文是基于CentOS 7.3系统环境,进行MapReduce的学习和使用本文是基于CentOS 7.3系统环境,进行MapReduce的学习和使用
1. MapReduce简介
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是基于Hadoop的数据分析计算的核心框架
1.2 MapReduce处理过程
主要分为两个阶段:Map和Reduce
- Map负责把一个任务分解成多个任务
- Reduce负责把分解后多任务处理的结果进行汇总
1.3 MapReduce的优点
- MapReduce易于编程 只需要实现一些简单接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,就跟写一个简单的串行程序是一模一样的。
- 良好的扩展性(hadoop的特点) 当你的计算资源不能满足的时候,你可以通过简单的增加机器(nodemanager)来扩展它的计算能力
- 高容错性 MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性,比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于整个任务运行失败。
- 适合PB级以上海量数据的离线处理 可以实现上千台服务器集群并发工作,提供数据处理能力
1.4 MapReduce的缺点
- 不擅长实时计算 MapReduce无法像mysql一样,在毫秒或者秒级内返回结果
- 不擅长流式计算 流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的
- 不擅长DAG有向图计算 多个应用程序之间存在依赖关系,后一个应用程序的输入为前一个程序的输出。在这种情况下,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常低下
1.5 MapReduce核心编程思想
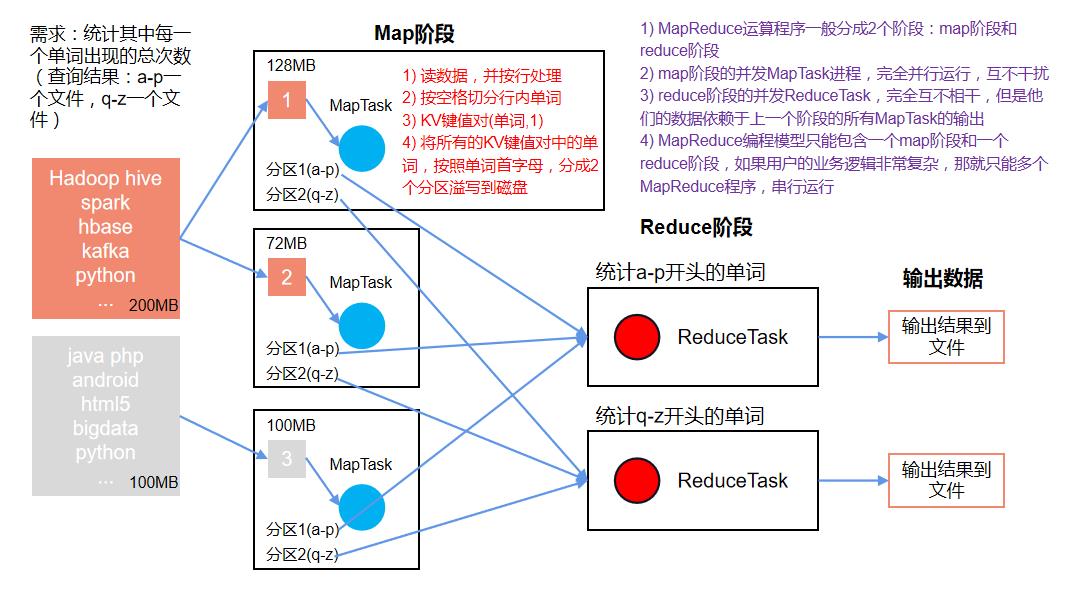
分布式的运算程序往往需要分成至少2个阶段。 第一个阶段的MapTask并发实例,完全并行运行,互不相干。 第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。 MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
1.6 MapReduce进程
- MrAppMaster 负责整个程序的过程调度及状态协调
- MapTask 负责Map阶段的整个数据处理流程
- ReduceTask 负责Reduce阶段的整个数据处理流程
1.7 数据切片与MapTask并行度机制
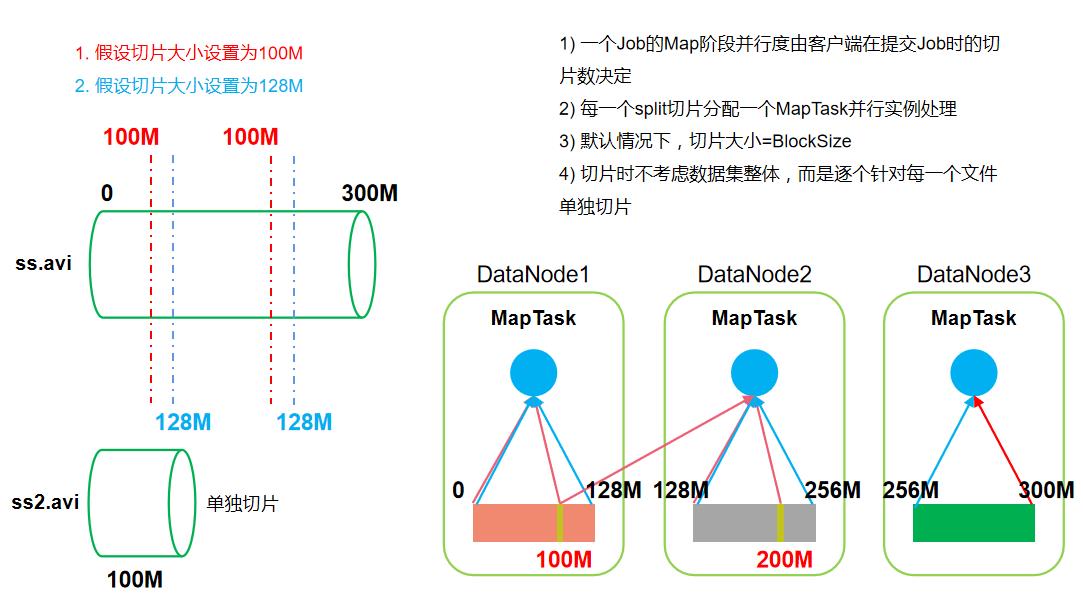
1.8 FileInputFormat切片机制
- 切片机制
简单地安装文件的内容长度进行切片 切片大小,默认等于Block大小 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
- 案例分析
输入数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1 ---- 0~128M
file1.txt.split2 ---- 128M~256M
file1.txt.split1 ---- 256M~320M
file2.txt.split1 ---- 0~10M
1.9 CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,而创建MapTask的开销比较大,处理效率极其低下。
- 应用场景 CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
- 虚拟存储切片最大值设置 CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
- 切片机制 生成切片过程包括:虚拟存储过程和切片过程两部分。
虚拟存储过程: 将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。 切片过程:
- (a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
- (b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
4. 案例分析 
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。 有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为: 1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M) 最终会形成3个切片,大小分别为: (1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
1.10 FileInputFormat实现类
| InputFormat | 切片规则(getSplits) | 把切片分解成KV(createRecordReader) |
|---|---|---|
| FileInputFormat | 按文件->块大小 | 没有实现 |
| TextInputFormat | 继承FileInputFormat | LineRecordReader<偏移量,行数据> |
| CombineTextInputFormat | 重写了getSplit,小块合并切 | CombineFileRecordReader(和LineRecordReader处理一样,只不过跨文件了)<偏移量,行数据> |
| KeyValueTextInputFormat | 继承FileInputFormat | KeyValueLineRecordReader<分隔符前,分隔符后> |
| NLineInputFormat | 重写了getSplit,按行切 | LineRecordReader<偏移量,行数据> |
| 自定义 | 继承FileInputFormat | 自定义RecordReader |
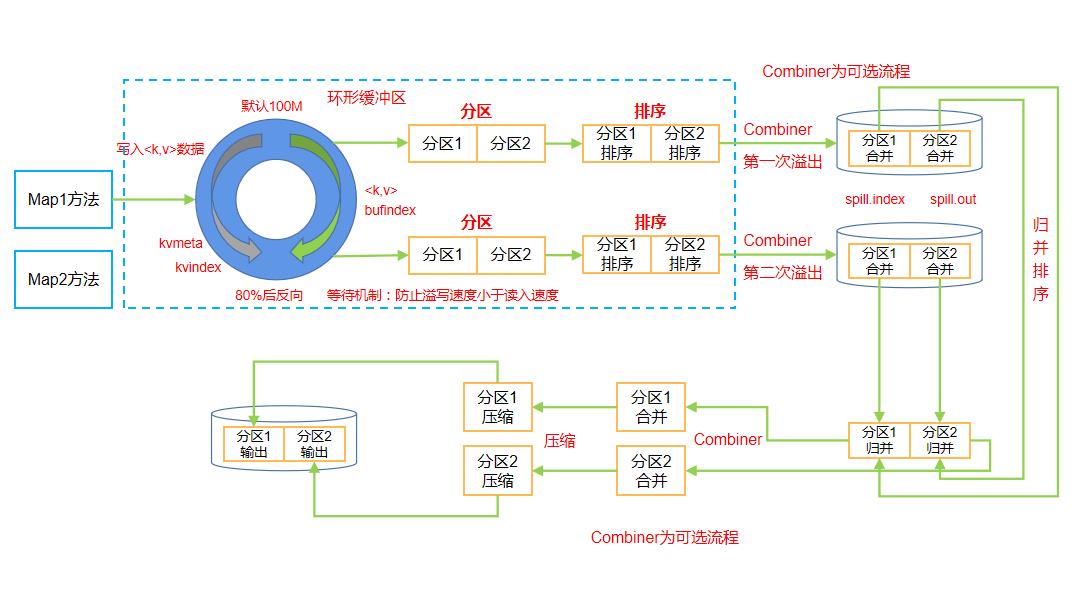
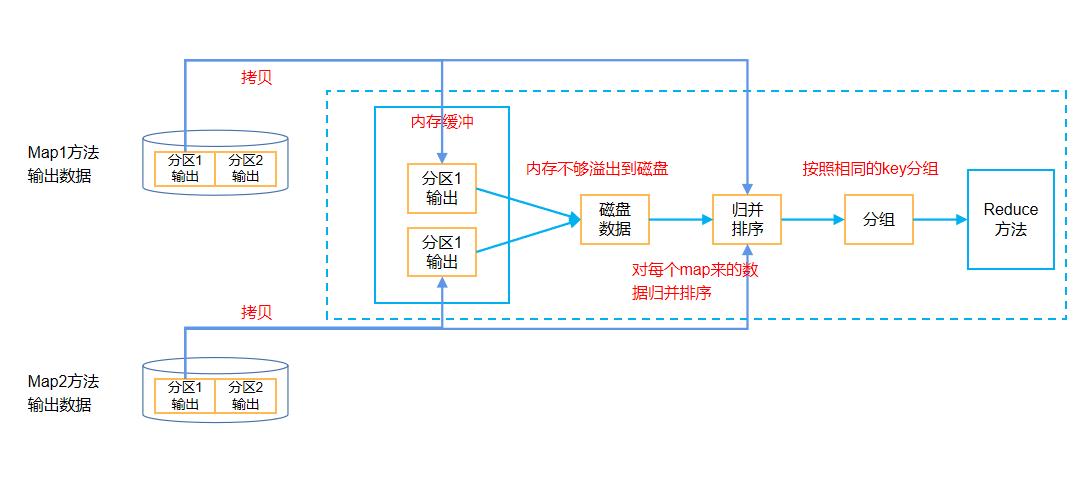
1.11 Shuffle机制
1.12 分区
分区数量等于ReduceTask的进程数
1. 分区机制
- 如果ReduceTask的数量>getPartition的结果数,则会多产生几个空的输出文件part-r-000xxx;
- 如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会报Exception;
- 如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
- 分区号必须从零开始,逐一累加。
2. 案例分析 例如:假设自定义分区数为5,
- job.setNumReduceTasks(6);大于5,程序会正常运行,则会多产生几个空的输出文件
- job.setNumReduceTasks(2);会报Exception;
- job.setNumReduceTasks(1),会正常运行,最终也就只会产生一个输出文件;
1.13 排序
1. 排序概述
- 排序是MapReduce框架中最重要的操作之一
- MapTask和ReduceTask均会对数据按照key进行排序。该操作数据Hadoop的默认行为。任何应用程序中的数据均会被排序,而不是逻辑上是否需要。
- 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
2. 排序分类
- 部分排序:MapReduce根据输入记录的键对数据集排序,保障输出的每个文件内部有序。
- 全排序:最终输出结果只有一个文件,且文件内部有序。
- 辅助排序(GroupingComparator):在Reduce端对key进行分组
- 二次排序:在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
1.14 Combiner合并
- Combiner是MR程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置不同(Combiner是在每一个MapTask所在的节点运行;Reducer是接收全局所有Mapper的输出结果)
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv应用跟Reducer的输入kv类型要对应起来

1.15 MapTask工作机制
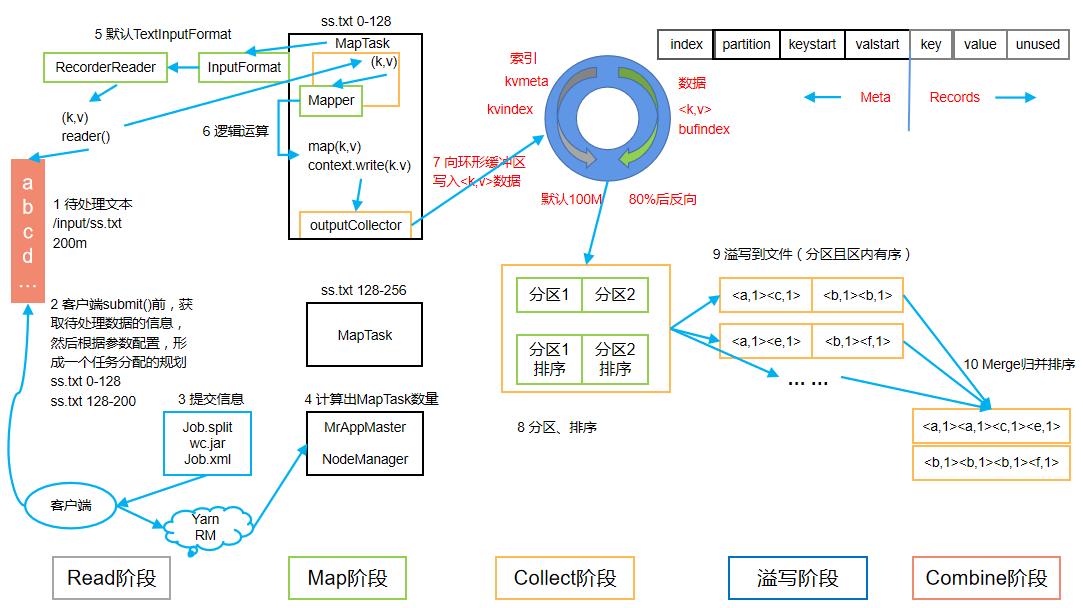
-
Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
-
Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
-
Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
-
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情 **步骤1:**利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。 **步骤2:**按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。 **步骤3:**将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
-
Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
1.16 ReduceTask工作机制
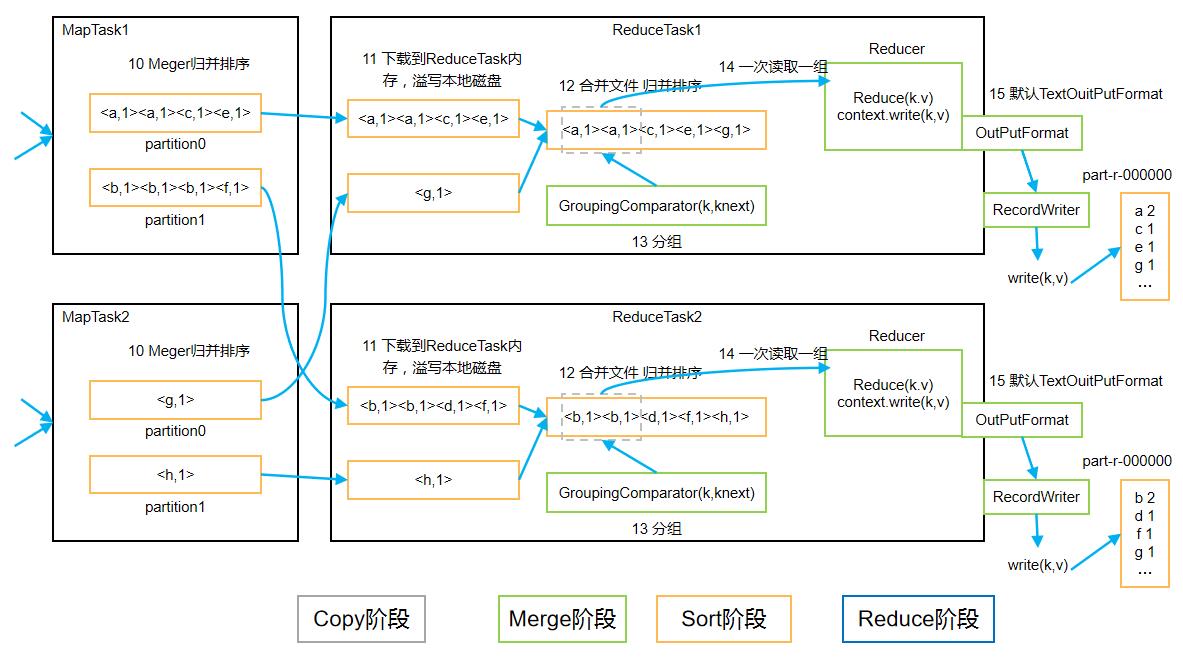
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
- Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
- Reduce阶段:reduce()函数将计算结果写到HDFS上。
1.17 ReduceTask并行度
ReduceTask的并行度影响整个job的执行并发度和执行效率,但与MapTask的并发数有切片数决定不同,ReduceTask数量的决定是可以直接手动设置的
- ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致,在实际开发中,如果可以不用Reduce,可以将值设置为0,因为在整个MR阶段,比较耗时的shuffle,省掉了Reduce,就相当于省掉了shuffle;
- ReduceTask默认值就是1,所以输出文件个数为1;
- 如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜;
- ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask;
- 具体多少个ReduceTask,需要根据集群性能而定;
- 如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程,因为在MapTask的源码中,执行分区的前提就是先判断ReduceNum个数是否大于1,不大于1肯定不执行。
1.18 Reduce Join工作原理
**Map端的主要工作:**为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。 **Reduce端的主要工作:**在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就OK了。 **缺点:**这种方式,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜 **解决方案:**Map端实现数据合并
1.19 Map Join工作原理
**适用场景:**Map Join试验于一张表十分大,一张表十分小的场景 **优点:**在Map端缓存多张表,提前出来业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜
1.20 计数器应用
**定义:**Hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量
计数器API:
采用枚举的方式统计计数 采用计数器组、计数器名称的方式统计
1.21 数据压缩
**定义:**压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率。在运行MR程序时,I/O操作、网络数据传输、shuffle和Merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。因此,使用数据压缩显得非常重要。
**优点:**鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。可以在任意MapReduce阶段启用压缩。
**缺点:**不过,尽管压缩与解压操作的CPU开销不高,其性能的提升和资源的节省并非没有代价
**压缩策略:**压缩是提供Hadoop运行效率的一种优化策略。 通过对mapper、reducer运行过程的数据进行压缩,以减少磁盘I/O,提高MR程序运行速度。
压缩原则:
- 运算密集型的job,少用压缩
- I/O密集型的job,多用压缩
1.22 MR支持的压缩编码
| 压缩格式 | hadoop自带 | 算法文件扩展名 | 是否可切分 | 压缩后,原来的程序是否需要修改 |
|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE.deflate | 否 | 和文本处理一样,不需要修改 |
| gzip | 是,直接使用 | DEFLATE.gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2.bz | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO.lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy.snappy | 否 | 和文本处理一样,不需要修改 |
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3G | 1.8G | 17.5MB/s | 58MB/s |
| bzip | 28.3G | 1.1G | 2.4MB/s | 9.5MB/s |
| gzip | 8.3G | 2.9G | 49.3MB/s | 74.6MB/s |
| snappy | 8.3G | * | 250MB/s | 500MB/s |
1.23 压缩方式选择
- Gzip压缩
**优点:**压缩率比较高,而且压缩/解压速度也比较快;Hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;大部分Linux系统都自带gzip命令,使用方便 **缺点:**不支持split **应用场景:**当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑gzip压缩格式
- Bzip2压缩
**优点:**支持split,具有很高压缩率,比Gzip压缩率高;Hadoop本身支持,使用方便 **缺点:**压缩/解压速度比较慢 **应用场景:**适合对速度要求不高,但需要较高的压缩率的时候;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序的情况
- Lzo压缩
**优点:**压缩/解压速度也比较快,合理的压缩率;支持split,是Hadoop中最流行的压缩格式;可以在Linux系统下安装lzop命令,使用方便 **缺点:**压缩率比Gzip要低一些;Hadoop本身不支持,需要安装;在应用中对Lzo格式的文件需要做一些特殊处理(为了支持split要建索引,还需要指定InputFormat为Lzo格式) **应用场景:**一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,Lzo优点越明显
- snappy压缩
**优点:**高速压缩/解压速度,合理的压缩率; **缺点:**不支持split;压缩率比Gzip要低;Hadoop本身不支持,需要安装 **应用场景:**当MapReduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;或者作为一个MapReduce作业的输出和另一个MapReduce作业的输入。
2. MapReduce编程规范
2.1 编写Mapper类
- 继承org.apache.hadoop.mapreduce.Mapper类
- 设置mapper类的输入类型<LongWritable, Text>
- 设置mapper类的输出类型<Text, IntWritable>
- 将输入类型中的Text转换成String类型,并按照指定分隔符进行分割
- 通过context.write()方法进行输出
package com.lytdev.dw.mapr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
private Text k = new Text();
private IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
String line = value.toString();
String[] words = line.split(" ");
for (String word : words)
k.set(word);
context.write(k, v);
2.2 编写Reducer类
- 继承org.apache.hadoop.mapreduce.Reducer类
- 设置reducer类的输入类型<Text, IntWritable>
- 设置reducer类的输出类型<Text, IntWritable>
- 对values值进行汇总求和
- 通过context.write()方法进行输出
package com.lytdev.dw.mapr.demo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private int sum;
private IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
sum = 0;
for (IntWritable value : values)
sum += value.get();
v.set(sum);
context.write(key, v);
2.3 编写Driver类
- 创建一个org.apache.hadoop.conf.Configuration类对象
- 通过Job.getInstance(conf)获得一个job对象
- 设置job的3个类,driver、mapper、reducer
- 设置job的2个输出类型,map输出和总体输出
- 设置一个输入输出路径
- 调用job.waitForCompletion(true)进行提交任务
package com.lytdev.dw.mapr.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
boolean result = job.waitForCompletion(true);
System.out.println(result);
以上是关于深入浅出MapReduce的主要内容,如果未能解决你的问题,请参考以下文章