大数据学习笔记—MapReduce
Posted Yihui公众平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习笔记—MapReduce相关的知识,希望对你有一定的参考价值。
MapReduce是一个分布式运算程序的编程框架。核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式程序。
*分布式程序核心思想
注:MapReduce变成模型只能包含一个map阶段和Reduce阶段,如果业务的逻辑非常复杂,那就只能用多个MapReuduce程序,串行运行
*提出问题
1、map task如何进行任务分配?
2、reduce task如何分配要处理的任务
3、maptask和reducetask之间如何衔接?
4、如果maptask运行失败,如何处理?
5、maptask如果都要自己负责输出分区,很麻烦
*提出解决
引入一个主管 MapReduce Application Master,负责调度整个流转过程。
*wordcount实现逻辑及代码实现
1、Mapper
输入输出参数为KeyValue对(KV的类型可自定义)
KEYIN:
默认情况下,是mr框架独到的一行文本的偏移量,Long类型。
但是文件传输需要序列化传输,在hadoop中有更精简的序列化接口,所以不直接使用Long,而是用org.apache.hadoop.io.LongWritable
VALUEIN:默认情况下,是mr框架所读到的一行文本的内容,String类型。序列化原因同上,因此使用org.apache.hadoop.io.Text
KEYOUT:用户自定义逻辑处理完成之后输出数据中的key。此题中为单词,String类型,同上原因用Text。
VALUEOUT:用户自定义逻辑处理完成之后输出数据中的value。此题中为数量,Integer类型,同上原因用IntWritable。
业务逻辑写在自定义的map()方法中

注意:map计算的结果不是直接给reduce立即处理,而是存储在临时文件,计算结束后由reduce进行逻辑处理
2、Reducer
Reducer的输入数据类型对应Mapper的输入数据类型,也是KV对
KEYIN、VALUEIN:
对应mapper输出的KEYOUT,VALUEOUT类型
KEYOUT、VALUEOUT:
是自定义的reduce逻辑处理结果的输出数据类型
业务逻辑reduce()方法中
Text key为入参,此题中是单词
Iterable<IntWritable> values 迭代器,此题为reduce的结果集
reduce()方法对每一组相同key的<k,v>组只调用一次
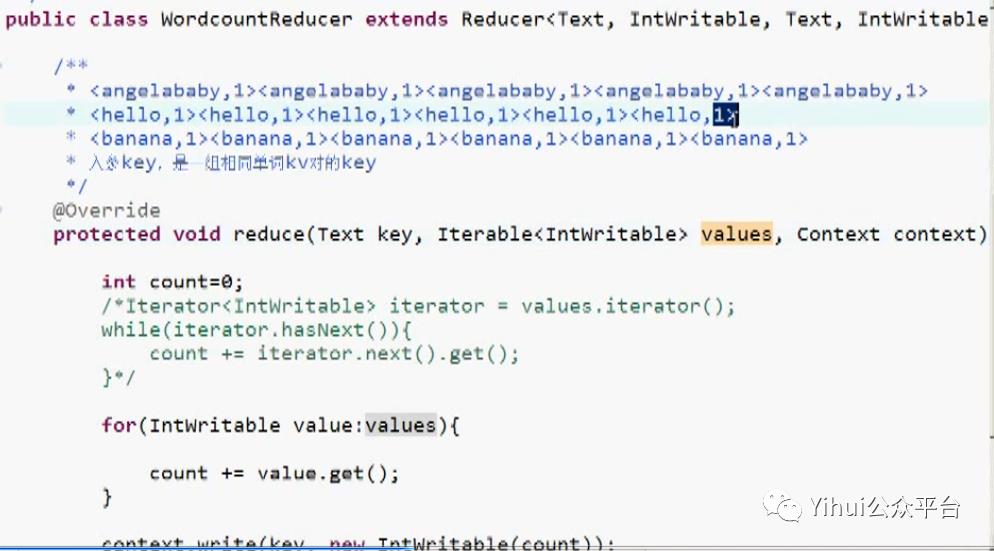
注:·每个reduce的汇总结果会写入hdfs文件中
3、Driver

注:若放在linux跑的服务器上有yarn环境,可以不用声明yarn环境
*wordcount运行流程
1、客户端submit时,会去hdfs中查看文件大小并进行规划分配,得到job.split切片,并将job.split、job.xml、wc.jar打包提交给yarn
2、yarn的ResouceManager找NodeManager服务器的mr appmaster去分配map task任务(以文件就近原则)
3、map task 从hdfs中逐行读取,提交给wordcountMapper的map(k,v)方法,再由context.write(k,v)输出到outputCollector收集结果文件
4、等待map处理完后,由reducetask开始执行wordcountReduce的redice(k,v)方法将结果输出到outputFormat到HDFS中存储
以上是关于大数据学习笔记—MapReduce的主要内容,如果未能解决你的问题,请参考以下文章