大数据讲课笔记5.3 MapReduce编程组件
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据讲课笔记5.3 MapReduce编程组件相关的知识,希望对你有一定的参考价值。
文章目录
零、学习目标
- 掌握InputFormat组件和OutputFormat组件
- 掌握Mapper组件和Reducer组件
- 掌握Partitioner组件和Combiner组件
一、导入新课
- 上一节中,主要讲解了MapReduce工作原理,让我们明白了MapReduce分布式计算框架的底层是如何协调工作的。本节将针对MapReduce编程组件进行详细讲解。
二、新课讲解
(一)InputFormat组件
- 主要用于描述输入数据的格式,它提供两个功能,分别是数据切分和为Mapper提供输入数据。定义如何读取和分割输入数据。InputFormat是一个类,定义了InputSplit用于把输入数据拆分到任务,并提供RecordReader对象工厂用于读取文件。InputFormat由作业的驱动器直接调用,基于InputSplit来确定map任务执行的数量和位置。

(二)Mapper组件
- Hadoop提供的Mapper类是实现Map任务的一个抽象基类,该基类提供了一个map()方法。mapper执行MapReduce程序第一阶段的用户自定义工作。从实现角度来看,mapper实现以一系列键值对(k1,v1)的形式接收输入数据,这些数据会用于单个map执行。map通常将输入对转换成输出对(k2,v2),后者会被用作洗牌和排序的输入。对于构成总的作业输入的每个map任务而言,mapper的新实例均运行在独立的JVM实例中。这是特意设计,即不为单独的mapper提供以任何方式与其它mapper进行通信的机制。这使得每个map任务的可靠性仅取决于本地机器的可靠性。

(三)Reducer组件
- Map过程输出的键值对,将由Reducer组件进行合并处理,最终的某种形式的结果输出。reducer负责执行第二阶段作业特定工作的用户提供代码。对于分配给特定reducer的每一个键,reducer的reduce()方法仅被调用一次。该方法接收一个键,以及一个与键关联的所有值的迭代器。迭代器以未定义的顺序返回与键相关的值。典型地,reducer将输入的键值对转换成输出对(k3,v3)。

(四)Partitioner组件
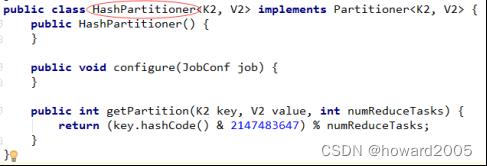
- Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key分发到不同的Reduce中去处理,其目的就是将key均匀分布在ReduceTask上。由每个单独mapper产生的中间键空间(k2,v2)的子集会被分配给每个reducer。这些子集(或分区)是reduce任务的输入。每个map任务可能会向任何分区派发键值对。相同键的所有值总要在一起进行reduce,无论它们来自哪个mapper。其结果是,所有map节点必须达成一致,确定由哪个reducer来处理不同的中间数据片段。Partitioner类确定了一个给定的键值对要去向哪一个reducer。默认的Partitioner为每个键计算散列值,并基于这个结果来分配分区。
- 默认的分区是HashPartitioner
(五)Combiner组件
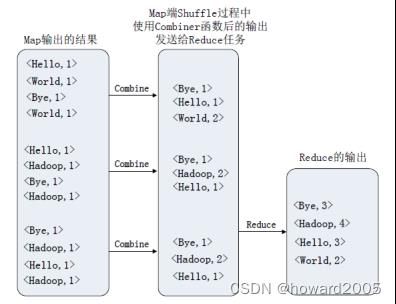
- Combiner组件的作用就是对Map阶段的输出的重复数据先做一次合并计算,然后把新的(key,value)作为Reduce阶段的输入。一个可选的处理步骤,用于优化MapReduce作业执行。如果存在的话,组合器在mapper之后、reducer之前运行。一个Combiner类的实例在每个map任务和部分reduce任务中运行。组合器接收mapper实例派发的所有数据作为输入,并尝试着组合有着相同键的值,从而缩小键空间,同时减少了需要排序的键(不必要的数据)的数量。接下来,组合器的输出会被排序并发送到reducer。
(六)OutputFormat组件
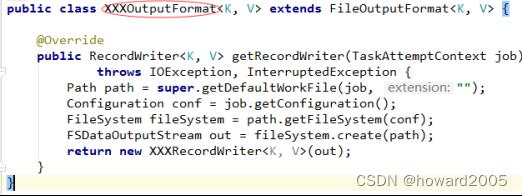
- OutputFormat是一个用于描述MapReduce程序输出格式和规范的抽象类。OutputFormat管理作业输出(作业输出由reducer生成,如果reducer不存在,则由mapper生成)的写方式。OutputFormat的职责是定义输出数据的位置以及用于保存结果数据的RecordWriter。
三、归纳总结
- 回顾本节课所讲的内容,并通过提问的方式引导学生解答问题并给予指导。
四、上机操作
- 形式:单独完成
- 题目:掌握MapReduce编程组件
- 要求:观看尚硅谷大数据视频关于掌握MapReduce编程组件这部分内容,然后写一篇学习报告。
以上是关于大数据讲课笔记5.3 MapReduce编程组件的主要内容,如果未能解决你的问题,请参考以下文章