设计思想赏析-MapReduce环形缓冲区
Posted 大数据架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计思想赏析-MapReduce环形缓冲区相关的知识,希望对你有一定的参考价值。
这是我的第27篇原创
上次一张MapReduce流程图画了我两天,始终不够满意,不够简洁。等有灵感了,再重新试试。
在MR、Storm、Spark、Flink这4种大数据计算引擎中,MR是当之无愧的开创者,甚至比后来的Storm都还要更稳定。其原因就是环形缓冲区,今天咱就来解剖这个环形缓冲区。
让我们回顾一下MapReduce的大致流程:
1、input组件从HDFS读取数据;
2、按照规则进行分片,形成若干个spilt;
3、进行Map
4、打上分区标签(patition)
5、数据入环形缓冲区(KVbuffer)
6、原地排序,并溢写(sort+spill)
7、combiner+merge,落地到磁盘
8、shuffle到reduce缓存
9、继续归并排序(mergesotr)
10、reduce
11、输出到HDFS
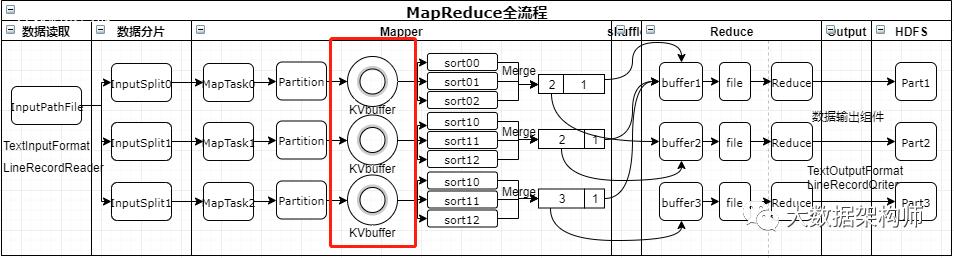
如上图所示,环形缓冲区是在溢写到磁盘之前的操作。
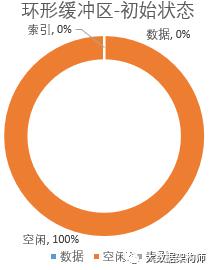
环形缓冲区分为三块,空闲区、数据区、索引区。初始位置取名叫做“赤道”,就是圆环上的白线那个位置。初始状态的时候,数据和索引都为0,所有空间都是空闲状态。
tips:这里有一个调优参数,可以设置环形缓冲区的大小:
mapreduce.task.io.sort.mb,默认100M,可以稍微设置大一些,但不要太大,因为每个spilt就128M。
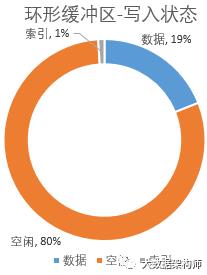
环形缓冲区写入的时候,有个细节:数据是从赤道的右边开始写入,索引(每次申请4kb)是从赤道是左边开始写。这个设计很有意思,这样两个文件各是各的,互不干涉。
在数据和索引的大小到了mapreduce.map.sort.spill.percent参数设置的比例时(默认80%,这个是调优的参数),会有两个动作:
1、对写入的数据进行原地排序,并把排序好的数据和索引spill到磁盘上去;
2、在空闲的20%区域中,重新算一个新的赤道,然后在新赤道的右边写入数据,左边写入索引;
3、当20%写满了,但是上一次80%的数据还没写到磁盘的时候,程序就会panding一下,等80%空间腾出来之后再继续写。
如此循环往复,永不停歇,直到所有任务全部结束。整个操作都在内存,形状像一个环,所以才叫环形缓冲区。
我们读取到文件,直接排序,然后写到HDFS里不就好了吗?为啥还要整一个环形缓冲区呢?
那从架构的角度看环形缓冲区,他这么设计有什么用呢?解决什么问题呢?
思路广的朋友应该已经反应过来了。环形缓冲区不需要重新申请新的内存,始终用的都是这个内存空间。大家知道MR是用java写的,而Java有一个最讨厌的机制就是Full GC。Full GC总是会出来捣乱,这个bug也非常隐蔽,发现了也不好处理。环形缓冲区从头到尾都在用那一个内存,不断重复利用,因此完美的规避了Full GC导致的各种问题,同时也规避了频繁申请内存引发的其他问题。
另外呢,环形缓冲区同时做了两件事情:1、排序;2、索引。在这里一次排序,将无序的数据变为有序,写磁盘的时候顺序写,读数据的时候顺序读,效率高非常多!
在这里设置索引区也是为了能够持续的处理任务。每读取一段数据,就往索引文件里也写一段,这样在排序的时候能加快速度。
有意思的是在Map阶段,是有索引文件的,但是在Reduce的时候就没有索引文件了,你知道是为什么吗?
我们理解一件事情,有三个层次:第一层看表面,第二层看原理,第三层看架构。
看表面的,是观众,是规则的顺从者;
看原理的,是导演,是规则的利用者;
看架构的,是作者,是规则的创造者,也就是我最喜欢的上帝视角。
无论在哪个领域,一旦你开启了上帝视角,你将无往而不利!
以上,与诸位共勉!
以上是关于设计思想赏析-MapReduce环形缓冲区的主要内容,如果未能解决你的问题,请参考以下文章