深度分析HBase架构
Posted 电商与管理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度分析HBase架构相关的知识,希望对你有一定的参考价值。
HBase的架构
物理上看, HBase系统有3种类型的后台服务程序, 分别是Region server, Master server 和 zookeeper.
Region server负责实际数据的读写. 当访问数据时, 客户端与HBase的Region server直接通信.
Master server管理Region的位置, DDL(新增和删除表结构)
Zookeeper负责维护和记录整个HBase集群的状态.
所有的HBase数据都存储在HDFS中. 每个 Region server都把自己的数据存储在HDFS中. 如果一个服务器既是Region server又是HDFS的Datanode. 那么这个Region server的数据会在把其中一个副本存储在本地的HDFS中, 加速访问速度.
但是, 如果是一个新迁移来的Region server, 这个region server的数据并没有本地副本. 直到HBase运行compaction, 才会把一个副本迁移到本地的Datanode上面.
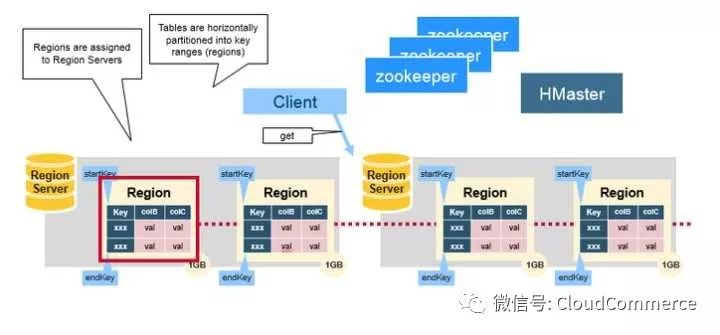
HBase Region server
HBase的表根据Row Key的区域分成多个Region, 一个Region包含这这个区域内所有数据. 而Region server负责管理多个Region, 负责在这个Region server上的所有region的读写操作. 一个Region server最多可以管理1000个region.
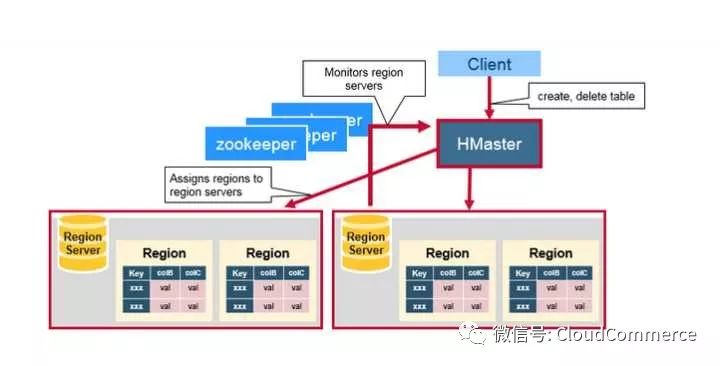
HBase Master server
HBase Maste主要负责分配region和操作DDL(如新建和删除表)等,
HBase Master的功能:
协调Region server
在集群处于数据恢复或者动态调整负载时,分配Region到某一个Region Server中
管控集群, 监控所有RegionServer的状态
提供DDL相关的API, 新建(create),删除(delete)和更新(update)表结构.
ZooKeeper: 集群"物业"管理员
Zookeepper是一个分布式的无中心的元数据存储服务. zookeeper探测和记录HBase集群中服务器的状态信息. 如果zookeeper发现服务器宕机, 它会通知Hbase的master节点. 在生产环境部署zookeeper至少需要3台服务器, 用来满足zookeeper的核心算法Paxos的最低要求.
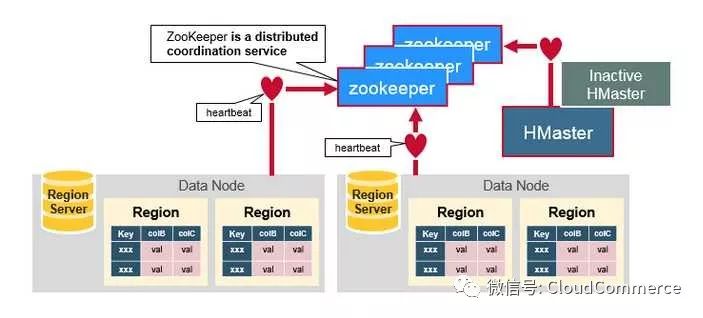
ZooKeeper, Master和 Region server协同工作
Zookeepr负责维护集群的memberlist, 哪台服务器在线,哪台服务器宕机都由zookeeper探测和管理. Region server, 主备Master节点主动连接Zookeeper, 维护一个Session连接,
这个session要求定时发送heartbeat, 向zookeeper说明自己在线, 并没有宕机.
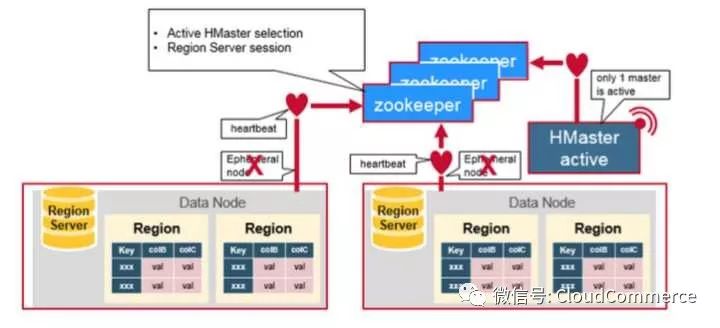
ZooKeeper有一个Ephemeral Node(临时节点)的概念, session连接在zookeeper中建立一个临时节点(Ephemeral Node), 如果这个session断开, 临时节点被自动删除.
所有Region server都尝试连接Zookeeper, 并在这个session中建立一个临时节点(Ephemeral node). HBase的master节点监控这些临时节点的是否存在, 可以发现新加入region server和判断已经存在的region server宕机.
为了高可用需求, HBase的master也有多个, 这些master节点也同时向Zookeeper注册临时节点(Ephemeral Node). Zookeeper把第一个成功注册的master节点设置成active状态, 而其他master node处于inactive状态.
如果zookeeper规定时间内, 没有收到active的master节点的heartbeat, 连接session超时, 对应的临时节也自动删除. 之前处于Inactive的master节点得到通知, 马上变成active状态, 立即提供服务.
同样, 如果zookeeper没有及时收到region server的heartbeat, session过期, 临时节点删除. HBase master得知region server宕机, 启动数据恢复方案.
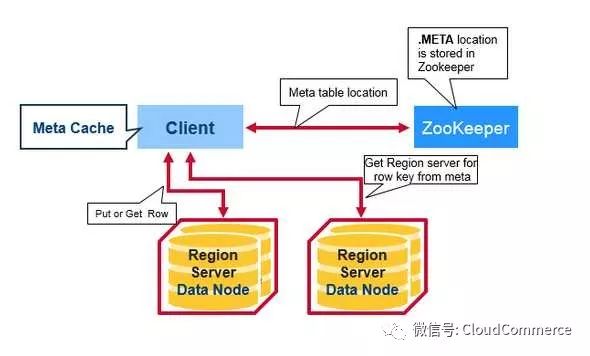
HBase的第一次读写流程
HBase的第一次读写流程
HBase把各个region的位置信息存储在一个特殊的表中, 这个表叫做Meta table.
Zookeeper里面存储了这个Meta table的位置信息.
HBase的访问流程:
1. 客户端访问Zookeep, 得到了具体Meta table的位置
2. 客户端再访问真正的Meta table, 从Meta table里面得到row key所在的region server
3. 访问rowkey所在的region server, 得到需要的真正数据.
客户端缓存meta table的位置和row key的位置信息, 这样就不用每次访问都读zookeeper.
如果region server由于宕机等原因迁移到其他服务器. Hbase客户端访问失败, 客户端缓存过期, 再重新访问zookeeper, 得到最新的meta table位置, 更新缓存.
HBase Meta Table
Meta table存储所有region的列表
Meta table用类似于Btree的方式存储
Meta table的结构如下:
- Key: region的开始row key, region id
- Values: Region server
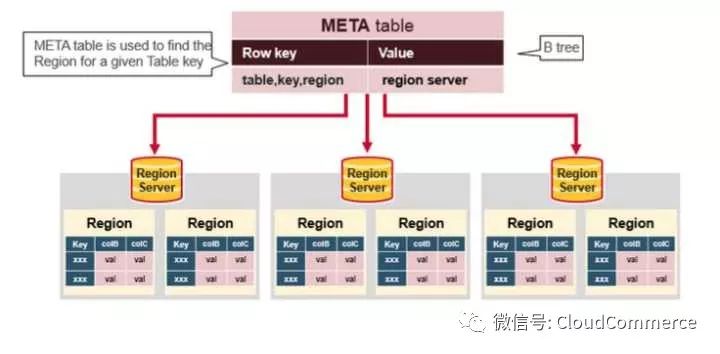
译注: 在google的bigtable论文中, bigtable采用了多级meta table, Hbase的Meta table只有2级
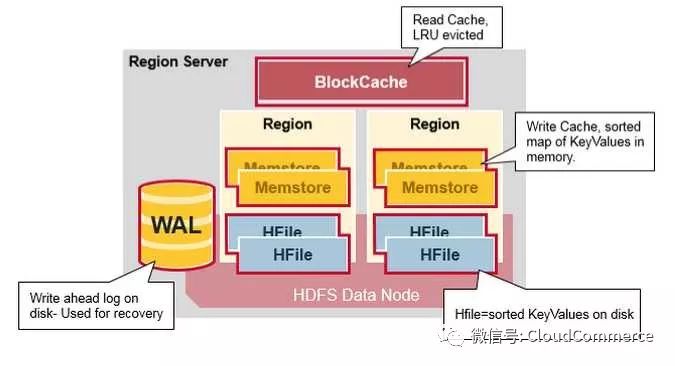
Region Server的结构
Region Server运行在HDFS的data node上面, 它有下面4个部分组成:
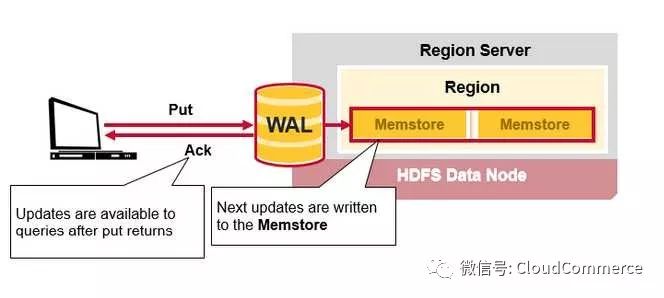
WAL: 预写日志(Write Ahead Log)是一HDFS上的一个文件, 如果region server崩溃后, 日志文件用来恢复新写入的的, 但是还没有存储在硬盘上的数据.
BlockCache: 读取缓存, 在内存里缓存频繁读取的数据, 如果BlockCache满了, 会根据LRU算法(Least Recently Used)选出最不活跃的数据, 然后释放掉
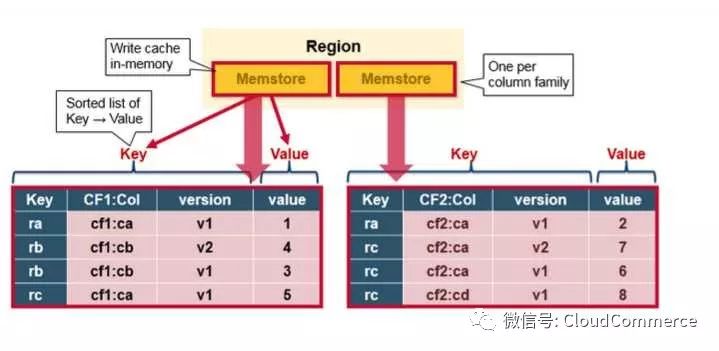
MemStore: 写入缓存, 在数据真正被写入硬盘前, Memstore在内存中缓存新写入的数据. 每个region的每个列簇(column family)都有一个memstore. memstore的数据在写入硬盘前, 会先根据key排序, 然后写入硬盘.
HFiles: HDFS上的数据文件, 里面存储KeyValue对.
HBase的写入流程(1)
当hbase客户端发起Put请求, 第一步是将数据写入预写日志(WAL):
将修改的操作记录在预写日志(WAL)的末尾
预写日志(WAL)被用来在region server崩溃时, 恢复memstore中的数据
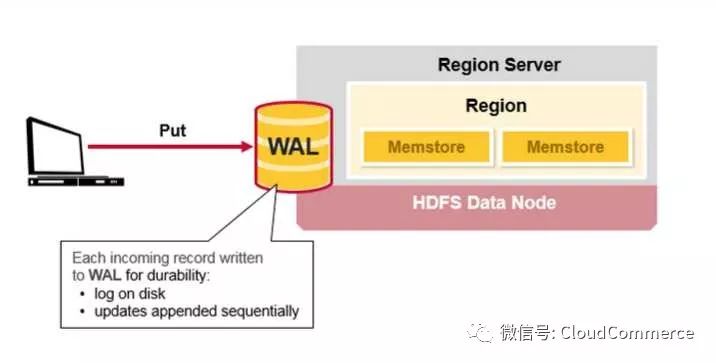
Hbase的写入流程(2)
数据写入预写日志(WAL), 并存储在memstore之后, 向用户返回写成功.
HBase MemStore
MemStore在内存按照Key的顺序, 存储Key-Value对, 一个Memstore对应一个列簇(column family). 同样在HFile里面, 所有的Key-Value对也是根据Key有序存储.
HBase Region Flush
译注: 原文里面Flush的意识是, 把缓冲的数据从内存 转存 到硬盘里, 这就类似与冲厕所(Flush the toilet) , 把数据比作是水, 一下把积攒的水冲到下水道, 想当于把缓存的数据写入硬盘. 和Flush非常类似的英文还有un-plug, 比如有一浴缸的水, 只要un-plug浴缸里面的塞子, 浴缸的水就开始流进下水道, 也类比把缓存数据写入硬盘
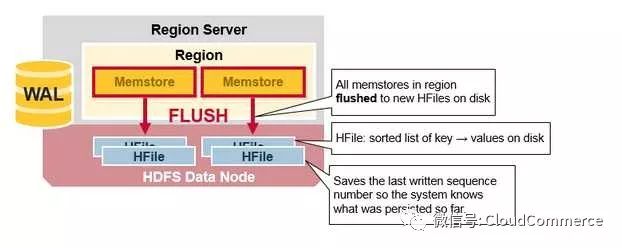
当Memstore累计了足够多的数据, Region server将Memstore中的数据写入HDFS, 存储为一个HFile. 每个列簇(column family)对于多个HFile, 每个HFile里面就是实际存储的数据.
这些HFile都是当Memstore满了以后, Flush到HDFS中的文件. 注意到HBase限制了列簇(column family)的个数. 因为每个列簇(column family)都对应一个Memstore. [译注: 太多的memstore占用过多的内存].
当Memstore的数据Flush到硬盘时, 系统额外保存了最后写入操作的序列号(last written squence number), 所以HBase知道有多少数据已经成功写入硬盘. 每个HFile都记录这个序号, 表明这个HFile记录了多少数据和从哪里继续写入数据.
在region server启动后, 读取所有HFile中最高的序列号, 新的写入序列号从这个最高序列号继续向上累加.
HBase HFile
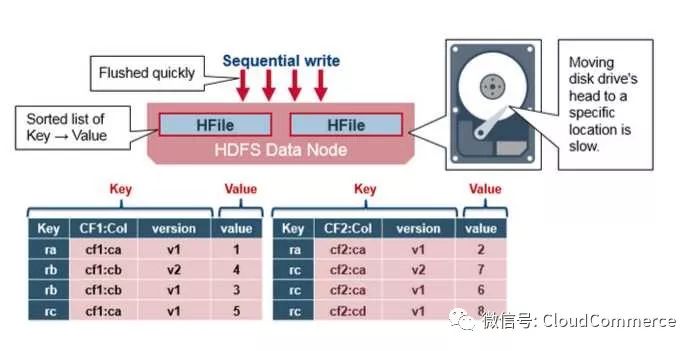
HFile中存储有序的Key-Value对. 当Memstore满了之后, Memstore中的所有数据写入HDFS中,形成一个新的HFile. 这种大文件写入是顺序写, 因为避免了机械硬盘的磁头移动, 所以写入速度非常快.
HBase HFile Structure
HFile存储了一个多级索引(multi-layered index), 查询请求不需要遍历整个HFile查询数据, 通过多级索引就可以快速得到数据(工作机制类似于b+tree)
Key-Value按照升序排列
Key-Value存储在以64KB为单位的Block里
每个Block有一个叶索引(leaf-index), 记录Block的位置
每个Block的最后一个Key(译注: 最后一个key也是最大的key), 放入中间索引(intermediate index)
根索引(root index)指向中间索引
尾部指针(trailer pointer)在HFile的最末尾, 它指向元数据块区(meta block), 布隆过滤器区域和时间范围区域. 查询布隆过滤器可以很快得确定row key是否在HFile内, 时间范围区域也可以帮助查询跳过不在时间区域的读请求.
译注: 布隆过滤器在搜索和文件存储中有广泛用途, 具体算法请参考https://china.googleblog.com/2007/07/bloom-filter_7469.html
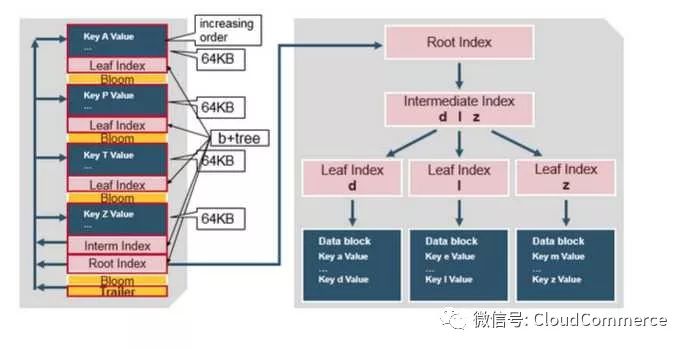
HFile索引
当打开HFile后, 系统自动缓存HFile的索引在Block Cache里, 这样后续查找操作只需要一次硬盘的寻道.
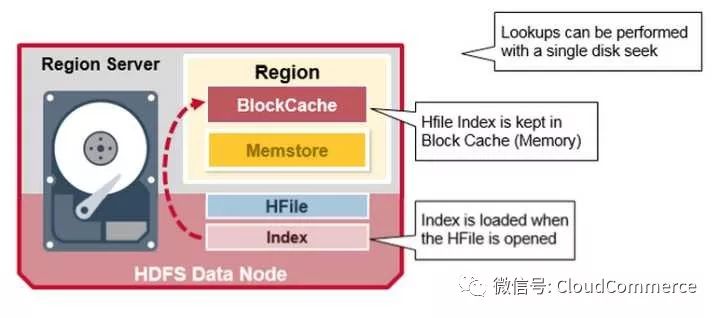
HBase的混合读(Read Merge)
我们发现HBase中的一个row里面的数据, 分配在多个地方. 已经持久化存储的Cell在HFile, 最近写入的Cell在Memstore里, 最近读取的Cell在Block cache里. 所以当你读HBase的一行时, 混合了Block cache, memstore和Hfiles的读操作
首先, 在Block cache(读cache)里面查找cell, 因为最近的读取操作都会缓存在这里. 如果找到就返回, 没有找到就执行下一步
其次, 在memstore(写cache)里查找cell, memstore里面存储里最近的新写入, 如果找到就返回, 没有找到就执行下一步
最后, 在读写cache中都查找失败的情况下, HBase查询Block cache里面的Hfile索引和布隆过滤器, 查询有可能存在这个cell的HFile, 最后在HFile中找到数据.
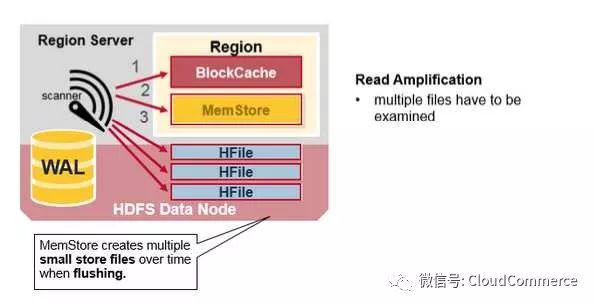
HBase Minor Compaction
HBase自动选择较小的HFile, 将它们合并成更大的HFile. 这个过程叫做minor compaction. Minor compaction通过合并小HFile, 减少HFile的数量.
HFile的合并采用归并排序的算法.
译注: 较少的HFile可以提高HBase的读性能
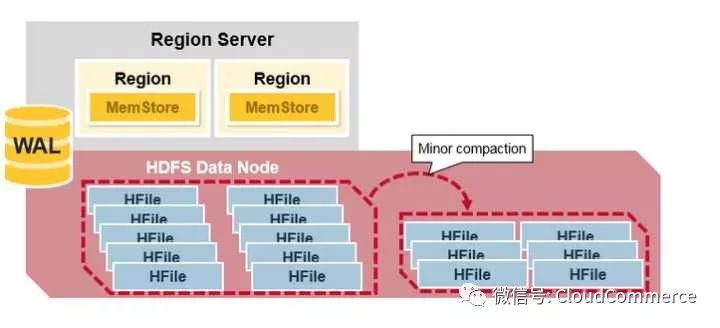
HBase Major Compaction
Major compaction指一个region下的所有HFile做归并排序, 最后形成一个大的HFile. 这可以提高读性能. 但是, major compaction重写所有的Hfile, 占用大量硬盘IO和网络带宽. 这也被称为写放大现象(write amplification)
Major compaction可以被调度成自动运行的模式, 但是由于写放大的问题(write amplification), major compaction通常在一周执行一次或者只在凌晨运行. 此外, major compaction的过程中, 如果发现region server负责的数据不在本地的HDFS datanode上, major compaction除了合并文件外, 还会把其中一份数据转存到本地的data node上.
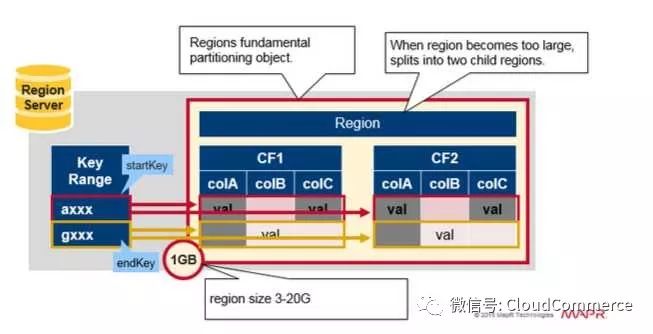
Region = 一组连续key
快速的复习region的概念:
一张表垂直分割成一个或多个region, 一个region包括一组连续并且有序的row key, 每一个row key对应一行的数据.
每个region最大1GB(默认)
region由region server管理
一个region server可以管理多个region, 最多大约1000个region(这些region可以属于相同的表,也可以属于不同的表)
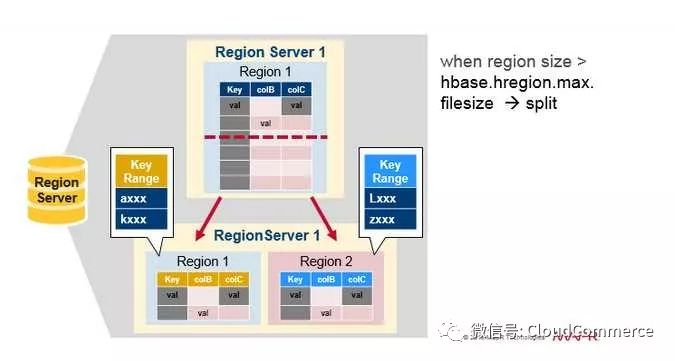
Region的拆分
最初, 每张表只有一个region, 当一个region变得太大时, 它就分裂成2个子region. 2个子region, 各占原始region的一半数据, 仍然被相同的region server管理. Region server向HBase master节点汇报拆分完成.
如果集群内还有其他region server, master节点倾向于做负载均衡, 所以master节点有可能调度新的region到其他region server, 由其他region管理新的分裂出的region.
负载均衡
最初, 一个Region server上的region一分为二, 但是考虑到负载均衡, master node会把新region调度到其他服务器上. 然而, 新region所在的region server在本地data node上没有数据, 所有操作都是操作远程HDFS上面的数据. 直到这个Region server运行了major compaction之后, 才有一份副本落在本地datanode中.
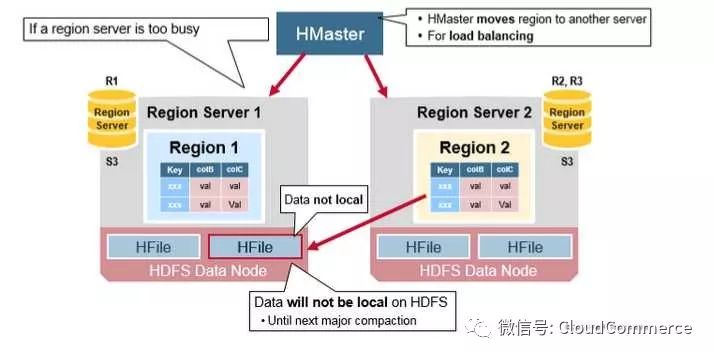
译注: HFile和WAL都是存储在HDFS中, 这里说的把副本存储在本地是指: 由于HDFS是一种聪明的FS, 如果他发现要求写入文件的客户端恰好也是HDFS的data node, 那么在分配哪三台服务器存储副本时, 会优先在发请求的客户端存储数据, 这样就可以让Region server管理的数据虽然是3份, 但是其中一份就在本地服务器上, 优化了访问路径.
具体可以参考这篇文章http://www.larsgeorge.com/2010/05/hbase-file-locality-in-hdfs.html, 里面详述了HDFS如何实现这种本地化的存储. 换句话说, 如果region server没有和HDFS的data node部署在同一台服务器, 就无法实现上面说的本地存储
HDFS的数据复制(1)
所有读写都是操作primary node. HDFS自动复制所有WAL和HFile的数据块到其他节点. HBase依赖HDFS保证数据安全. 当在HDFS里面写入一个文件时, 一份存储在本地节点, 另两份存储到其他节点
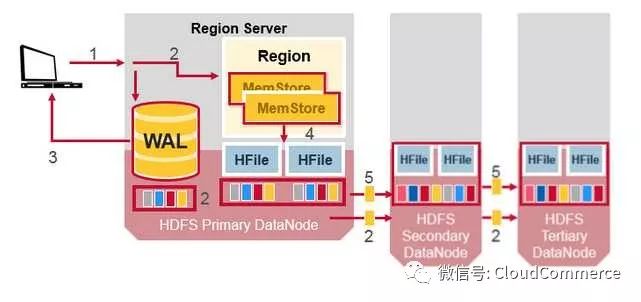
HDFS的数据复制(2)
预写日志(WAL) 和 HFile都存在HDFS里面, 可以保证数据的可靠性, 但是HBase memstore里的数据都在内存中, 如果系统崩溃后重启, Hbase如何恢复Memstore里面的数据?
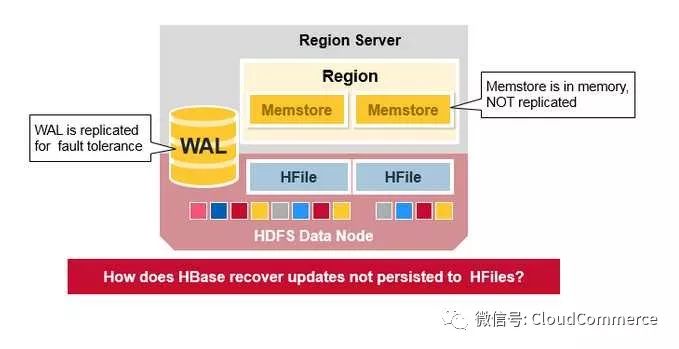
HBase的灾难恢复
当region server宕机, 崩溃的region server管理的region不能再提供服务, HBase监测到异常后, 启动恢复程序, 恢复region.
Zookeeper发现region server的heartbeat停止, 判断region server宕机并通知master节点. Hbase master节点得知该region server停机后, 将崩溃的region server管理的region分配给其他region server. HBase从预写文件(WAL)里恢复memstore里的数据.
HBase master知道老的region被重新分配到哪些新的region server. Master把已经crash的Region server的预写日志(WAL)拆分成多个. 参与故障恢复的每个region server重放的预写日志(WAL), 重新构建出丢失Memstore.
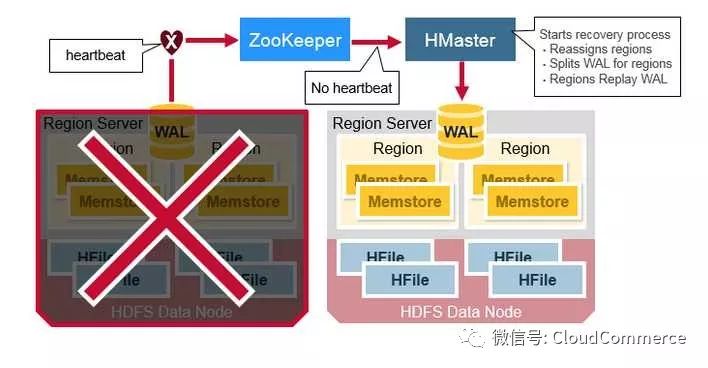
数据恢复
预写日志(WAL)记录了HBase的每个操作, 每个操作代表一个Put或者删除Delete动作. 所有的操作按照时间顺序在预写日志(WAL)排列, 文件头记录最老的操作, 最新的操作处于文件末尾.
如何恢复在memstore里, 但还没有写到HFile的数据? 重新执行预写日志(WAL)就可以. 从前到后依次执行预写日志(WAL)里的操作, 重建memstore数据. 最后, Flush memstore数据到的HFile, 完成恢复.
Apache Hbase架构优点
强一致模型
- 当写返回时, 确保所有读操作读到相同的值
自动扩展
- 数据增长过大时, 自动分裂region
- 利用HFDS分散数据和备份数据
内建自动回复
- 预写日志(WAL)
集成Hadoop生态
- 在HBase上运行map reduce
Apache HBase存在的问题...
Business continuity reliability:
重放预写日志慢
故障恢复既慢又复杂
Major compaction容易引起IO风暴(写放大)
<<<--------------------->>>
B2B2C电子商务与技术及企业管理!
以专业和分享为理念,关注电商、大数据、云计算、技术管理和企业管理!
致力于成为电商与管理领域的观察者、思考者和创新者。
◆手机微信扫描二维码订阅
以上是关于深度分析HBase架构的主要内容,如果未能解决你的问题,请参考以下文章
大数据架构开发 挖掘分析 Hadoop HBase Hive Storm Spark ZooKeeper Redis MongoDB 机器学习 云计算