Hbase的应用场景原理及架构分析
Posted yunpiao123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase的应用场景原理及架构分析相关的知识,希望对你有一定的参考价值。
HBase概述
HBase是一个构建在HDFS上的分布式列存储系统。HBase是Apache Hadoop生态系统中的重要 一员,主要用于海量结构化数据存储。从逻辑上讲,HBase将数据按照表、行和列进行存储。
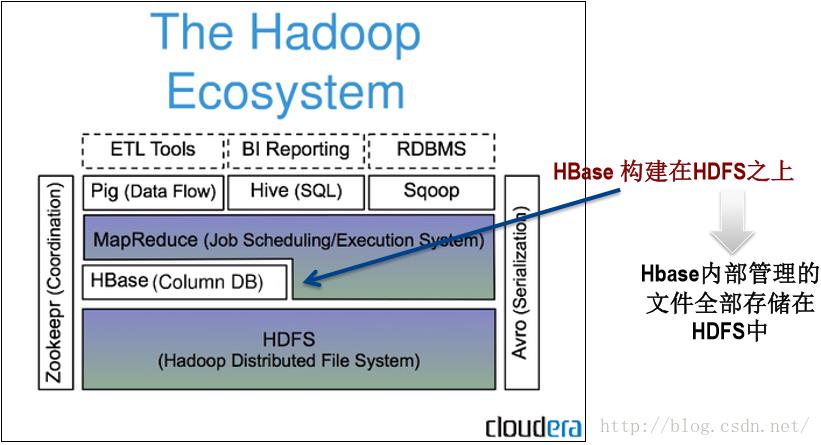
如图所示,Hbase构建在HDFS之上,Hadoop之下。其内部管理的文件全部存储在HDFS中。与HDFS相比两者都具有良好的容错性和扩展性,都可以 扩展到成百上千个节点。但HDFS适合批处理场景,不支持数据随机查找,不适合增量数据处理且不支持数据更新。
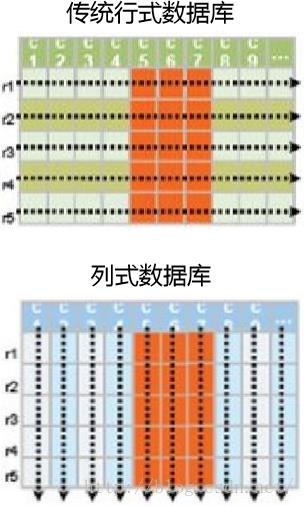
Hbase是列存储的非关系数据库。传统数据库mysql等,数据是按行存储的。其没有索引的查询将消耗大量I/O 并且建立索引和物化视图需要花费大量时间和资源。因此,为了满足面向查询的需求,数据库必须被大量膨胀才能满 足性能要求。
Hbase数据是按列存储-每一列单独存放。列存储的优点是数据即是索引。访问查询涉及的列-大量降低系统I/O 。并且每一列由一个线索来处理,可以实现查询的并发处理。基于Hbase数据类型一致性,可以实现数据库的高效压缩。
HBase数据模型
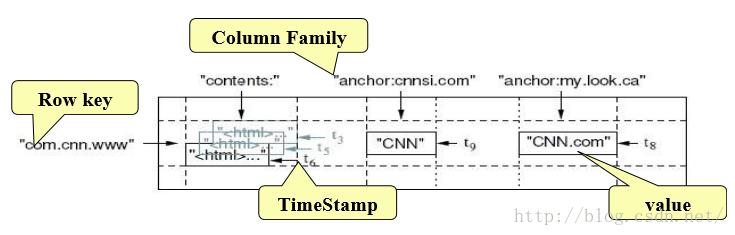
HBase是基于Google BigTable模型开发的, 典型的key/value系统。一个Row key对应很多Column Family,Column Family中有很多Column。其中,保存了不同时间戳的数据。
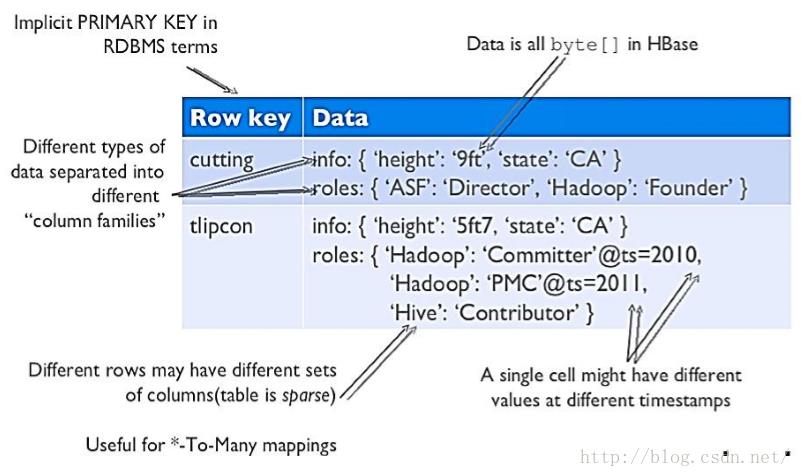
如图所示,Rowkey cutting对应列簇info和roles。其中,info中有key-value对hight-9ft,state-CA。更清晰的结构如下图所:
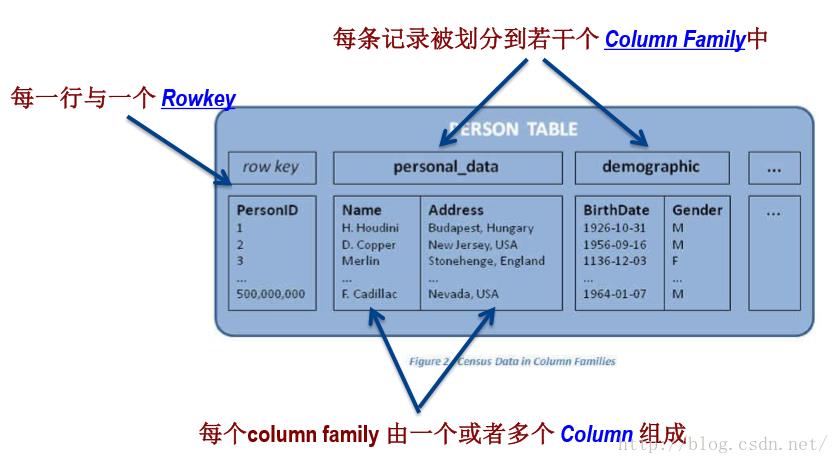
Hbase的所有操作均是基于rowkey的。支持CRUD(Create、Read、Update和Delete)和 Scan操作。 包括单行操作Put 、Get、Scan。多行操作包括Scan和MultiPut。但没有内置join操作,可使用MapReduce解决。
HBase物理模型
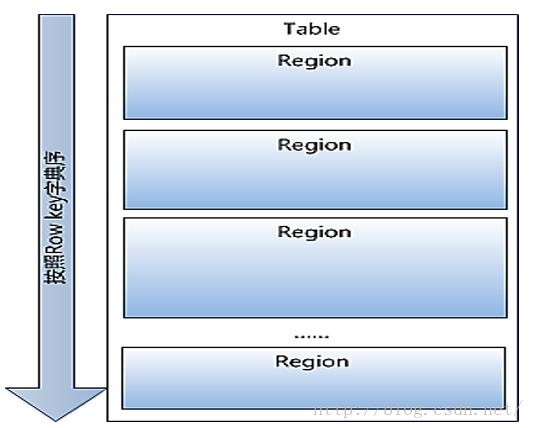
Hbase的Table中的所有行都按照row key的字典序排列。Table 在行的方向上分割为多个Region。、Region按大小分割的,每个表开始只有一个region,随 着数据增多,region不断增大,当增大到一个阀值的时候, region就会等分会两个新的region,之后会有越来越多的 region。
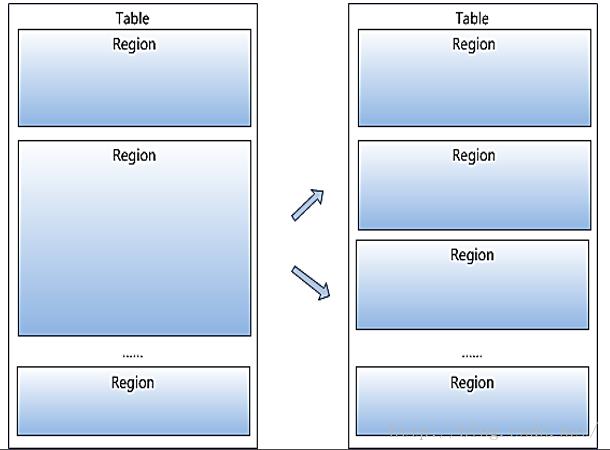
Region是HBase中分布式存储和负载均衡的最小单元。 不同Region分布到不同RegionServer上。
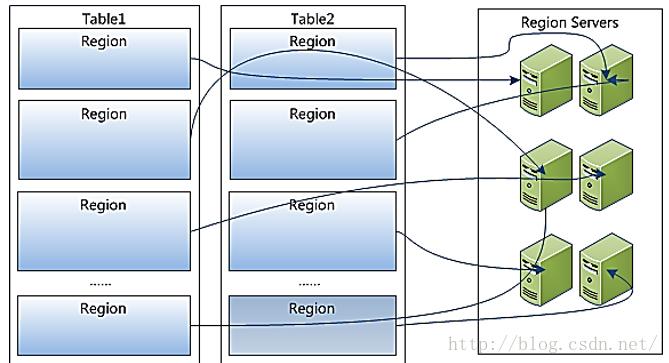
Region虽然是分布式存储的最小单元,但并不是存储 的最小单元。Region由一个或者多个Store组成,每个store保存一个 columns family。每个Strore又由一个memStore和0至多个StoreFile组成。memStore存储在内存中,StoreFile存储在HDFS上。

HBase基本架构
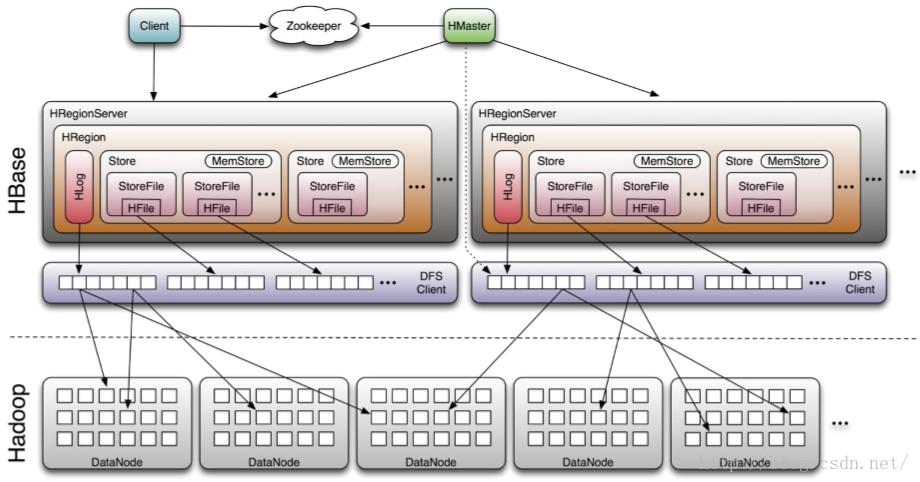
HBase构建在HDFS之上,其组件包括 Client、zookeeper、HDFS、Hmaster以及HRegionServer。Client包含访问HBase的接口,并维护cache来加快对HBase的访问。Zookeeper用来保证任何时候,集群中只有一个master,存贮所有Region的寻址入口以及实时监控Region server的上线和下线信息。并实时通知给Master存储HBase的schema和table元数据。HMaster负责为Region server分配region和Region server的负载均衡。如果发现失效的Region server并重新分配其上的region。同时,管理用户对table的增删改查操作。Region Server 负责维护region,处理对这些region的IO请求并且切分在运行过程中变得过大的region。
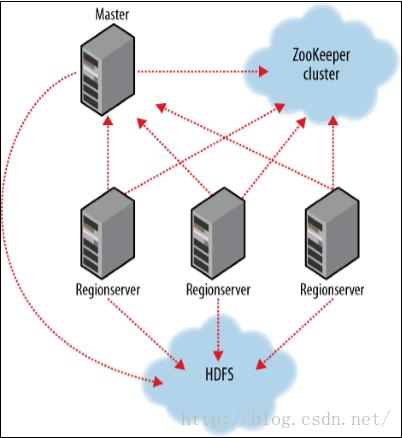
HBase 依赖ZooKeeper,默认情况下,HBase 管理ZooKeeper 实例。比如, 启动或者停止ZooKeeper。Master与RegionServers 启动时会向ZooKeeper注册。因此,Zookeeper的引入使得 Master不再是单点故障。
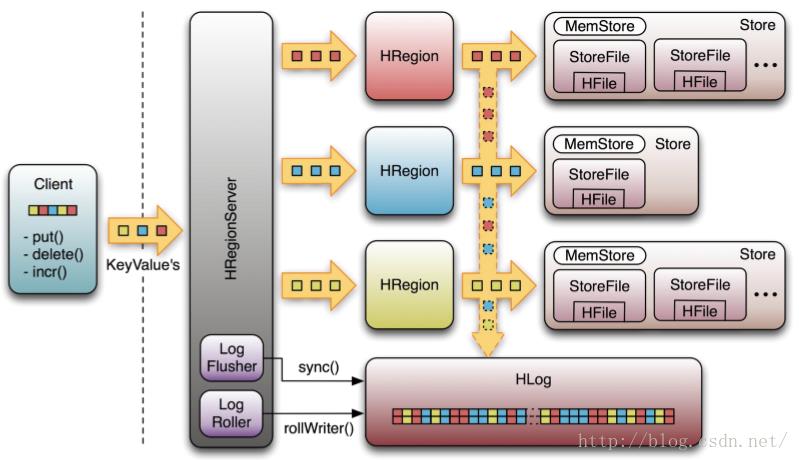
Client每次写数据库之前,都会首先血Hlog日志。记录写操作。如果不做日志记录,一旦发生故障,操作将不可恢复。HMaster一旦故障,Zookeeper将重新选择一个新的Master 。无Master过程中,数据读取仍照常进行。但是,无master过程中,region切分、负载均衡等无法进行。RegionServer出现故障的处理原理是定时向Zookeeper汇报心跳,如果一旦时 间内未出现心跳HMaster将该RegionServer上的Region重新分配到其他RegionServer上。失效服务器上“预写”日志由主服务器进行分割并派送给新的 RegionServer 。Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例。
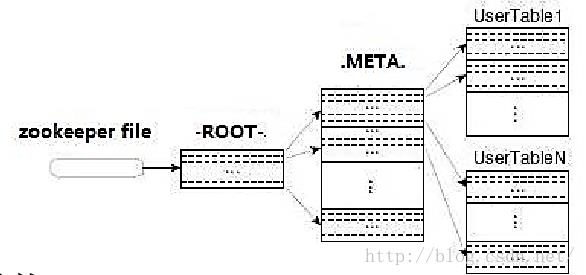
寻找RegionServer定位的顺序是ZooKeeper --ROOT-(单Region) -.META. -用户表 。如上图所示。-ROOT- 表包含.META.表所在的region列表,该表只会有一 个Region。 Zookeeper中记录了-ROOT-表的location。 .META. 表包含所有的用户空间region列表,以及 RegionServer的服务器地址。
HBase应用举例
Hbase适合需对数据进行随机读操作或者随机写操作、大数据上高并发操作,比如每秒对PB级数据进行上千次操作以及读写访问均是非常简单的操作。
淘宝指数是Hbase在淘宝的一个典型应用。交易历史纪录查询很适合用Hbase作为底层数据库。下节将介绍Hbase的编程模型。
以上是关于Hbase的应用场景原理及架构分析的主要内容,如果未能解决你的问题,请参考以下文章