超详细!教你一步一步搭建 Apache HBase 完全分布式集群
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细!教你一步一步搭建 Apache HBase 完全分布式集群相关的知识,希望对你有一定的参考价值。
#扫描上方二维码进入报名#
文章链接:https://my.oschina.net/u/876354/blog/1163018
Apache HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存储集群,利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase海量数据,使用Zookeeper协调服务器集群。Apache HBase官网有详细的介绍文档。
Apache HBase的完全分布式集群安装部署并不复杂,下面是部署的详细过程:
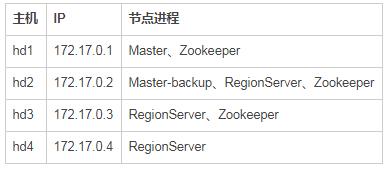
1、规划HBase集群节点
本实验有4个节点,要配置HBase Master、Master-backup、RegionServer,节点主机操作系统为Centos 6.9,各节点的进程规划如下:
2、安装 JDK、Zookeeper、Hadoop
各服务器节点关闭防火墙、设置selinux为disabled
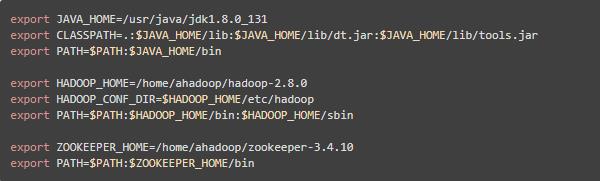
安装 JDK、Zookeeper、Apache Hadoop 分布式集群(具体过程详见我另一篇博文:Apache Hadoop 2.8分布式集群搭建超详细过程)
安装后设置环境变量,这些变量在安装配置HBase时需要用到
3、安装NTP,实现服务器节点间的时间一致
如果服务器节点之间时间不一致,可能会引发HBase的异常,这一点在HBase官网上有特别强调。在这里,设置第1个节点hd1为NTP的服务端节点,也即该节点(hd1)从国家授时中心同步时间,然后其它节点(hd2、hd3、hd4)作为客户端从hd1同步时间
(1)安装 NTP

启动 NTP 服务

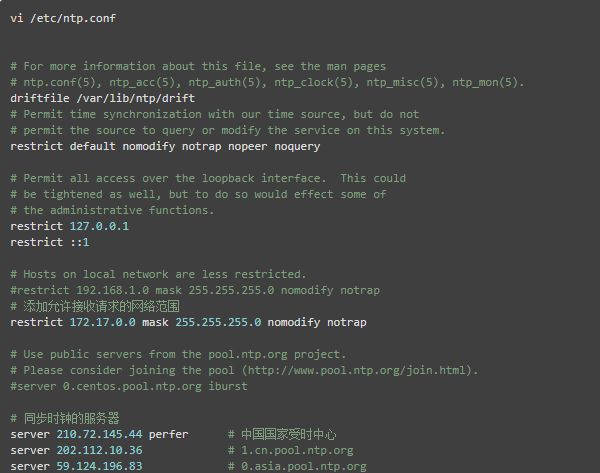
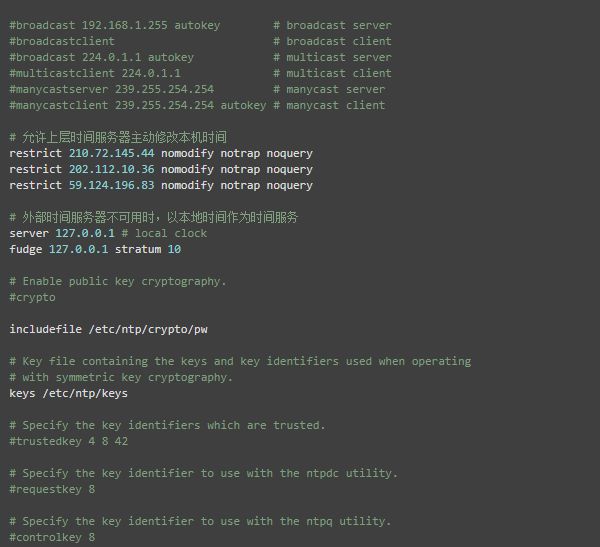
(2)配置NTP服务端
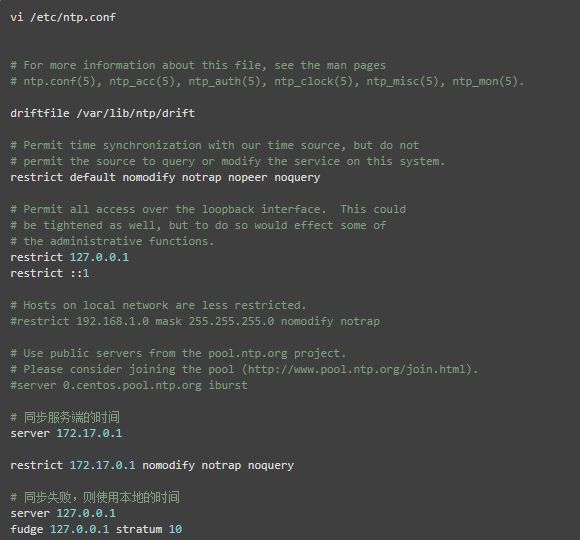
在节点hd1,编辑 /etc/ntp.conf 文件,配置NTP服务,具体的配置改动项见以下中文注释
重启 NTP 服务

然后查看ntp状态

这时发现有报错,原来ntpd服务有一个限制,ntpd仅同步更改与ntp server时差在1000s内的时间,而查了服务器节点的时间与实际时间差已超过了1000s,因此,必须先手动修改下操作系统时间与ntp server相差时间在1000s以内,然后再去同步服务
其实还有另外一个小技巧,就是在安装好NTP服务后,先通过授时服务器获得准确的时间,这样也不用手工修改了,命令如下:

【注意】如果是在docker里面执行同步时间操作,系统会报错

如果出现这个错误,说明系统不允许自行设置时间。在docker里面,由于docker容器共享的是宿主机的内核,而修改系统时间是内核层面的功能,因此,在 docker 里面是无法修改时间
(3)配置NTP客户端
在节点hd2、hd3、hd4编辑 /etc/ntp.conf 文件,配置 NPT 客户端,具体的配置改动项,见以下的中文注释
重启NTP服务

启动后,查看时间的同步情况

4、修改ulimit
在Apache HBase官网的介绍中有提到,使用 HBase 推荐修改ulimit,以增加同时打开文件的数量,推荐 nofile 至少 10,000 但最好 10,240 (It is recommended to raise the ulimit to at least 10,000, but more likely 10,240, because the value is usually expressed in multiples of 1024.)
修改 /etc/security/limits.conf 文件,在最后加上nofile(文件数量)、nproc(进程数量)属性,如下:

修改后,重启服务器生效

5、安装配置Apache HBase
Apache HBase 官网提供了默认配置说明、参考的配置例子,建议在配置之前先阅读一下。
在本实验中,采用了独立的zookeeper配置,也hadoop共用,zookeeper具体配置方法可参考我的另一篇博客。其实在HBase中,还支持使用内置的zookeeper服务,但如果是在生产环境中,建议单独部署,方便日常的管理。
(1)下载Apache HBase
从官网上面下载最新的二进制版本:hbase-1.2.6-bin.tar.gz
然后解压

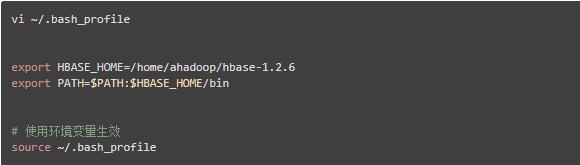
配置环境变量
(2)复制hdfs-site.xml配置文件
复制$HADOOP_HOME/etc/hadoop/hdfs-site.xml到$HBASE_HOME/conf目录下,这样以保证hdfs与hbase两边一致,这也是官网所推荐的方式。在官网中提到一个例子,例如hdfs中配置的副本数量为5,而默认为3,如果没有将最新的hdfs-site.xml复制到$HBASE_HOME/conf目录下,则hbase将会按3份备份,从而两边不一致,导致会出现异常。

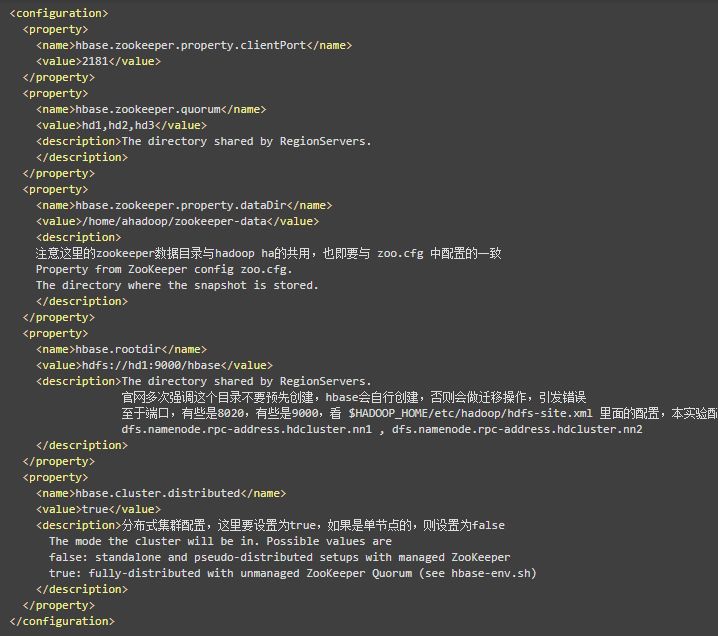
(3)配置hbase-site.xml
编辑 $HBASE_HOME/conf/hbase-site.xml
(4)配置regionserver文件
编辑 $HBASE_HOME/conf/regionservers 文件,输入要运行 regionserver 的主机名

(5)配置 backup-masters 文件(master备用节点)
HBase 支持运行多个 master 节点,因此不会出现单点故障的问题,但只能有一个活动的管理节点(active master),其余为备用节点(backup master),编辑 $HBASE_HOME/conf/backup-masters 文件进行配置备用管理节点的主机名

(6)配置 hbase-env.sh 文件
编辑 $HBASE_HOME/conf/hbase-env.sh 配置环境变量,由于本实验是使用单独配置的zookeeper,因此,将其中的 HBASE_MANAGES_ZK 设置为 false

到此,HBase 配置完毕
6、启动 Apache HBase
可使用 $HBASE_HOME/bin/start-hbase.sh 指令启动整个集群,如果要使用该命令,则集群的节点必须实现ssh的免密码登录,这样才能到不同的节点启动服务
为了更加深入了解HBase启动过程,本实验将对各个节点依次启动进程,经查看 start-hbase.sh 脚本,里面的启动顺序如下
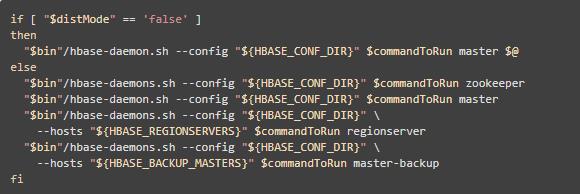
也就是使用 hbase-daemon.sh 命令依次启动 zookeeper、master、regionserver、master-backup
因此,我们也按照这个顺序,在各个节点进行启动
在启动HBase之前,必须先启动Hadoop,以便于HBase初始化、读取存储在hdfs上的数据
(1)启动zookeeper(hd1、hd2、hd3节点)

(2)启动hadoop分布式集群(集群的具体配置和节点规划,见我的另一篇博客)
(3)启动hbase master(hd1)

(4)启动hbase regionserver(hd2、hd3、hd4)

(5)启动hbase backup-master(hd2)

这里很奇怪,在 $HBASE_HOME/bin/start-hbase.sh 写着启动 backup-master 的命令为

但实际按这个指令执行时,却报错提示无法加载类 master-backup
[ahadoop@1620d6ed305d ~]$ hbase-daemon.sh start master-backup &
[5] 1113
[ahadoop@1620d6ed305d ~]$ starting master-backup, logging to /home/ahadoop/hbase-1.2.6/logs/hbase-ahadoop-master-backup-1620d6ed305d.out
Error: Could not find or load main class master-backup
最后经查资料,才改用了以下命令为启动 backup-master

经过以上步骤,就已成功地启动了hbase集群,可到每个节点里面使用 jps 指令查看 hbase 的启动进程情况。
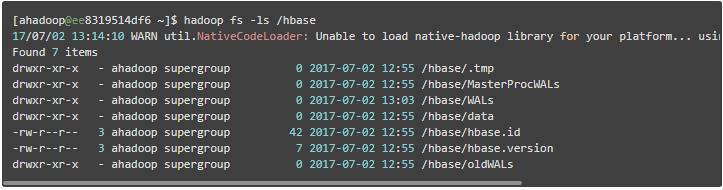
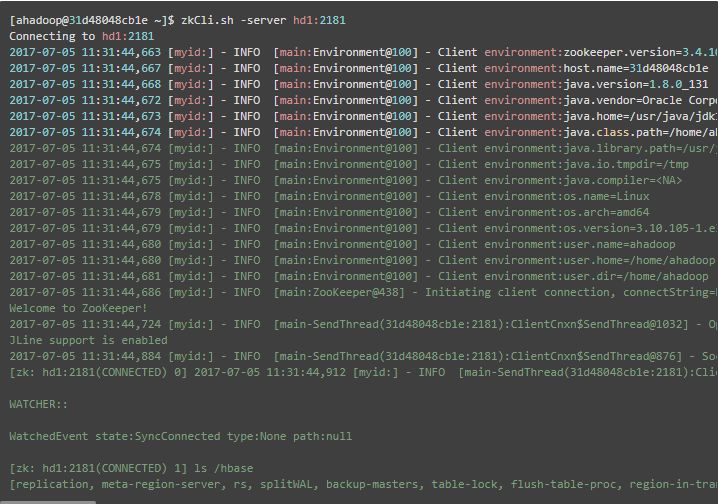
启动后,再查看 hdfs 、zookeeper 的 /hbase 目录,发现均已初始化,并且已写入了相应的文件,如下
7、HBase 测试使用
使用hbase shell进入到 hbase 的交互命令行界面,这时可进行测试使用

(1)查看集群状态和节点数量

(2)创建表

hbase创建表create命令语法为:表名、列名1、列名2、列名3……
(3)查看表

(4)导入数据

导入数据的命令put的语法为表名、行值、列名(列名可加冒号,表示这个列簇下面还有子列)、列数据
(5)全表扫描数据

(6)根据条件查询数据
(7)表失效
使用 disable 命令可将某张表失效,失效后该表将不能使用,例如执行全表扫描操作,会报错,如下

(8)表重新生效
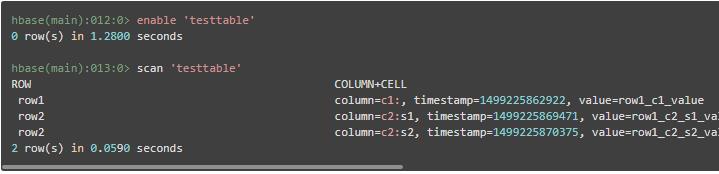
使用 enable 可使表重新生效,表生效后,即可对表进行操作,例如进行全表扫描操作
(9)删除数据表
使用drop命令对表进行删除,但只有表在失效的情况下,才能进行删除,否则会报错,如下
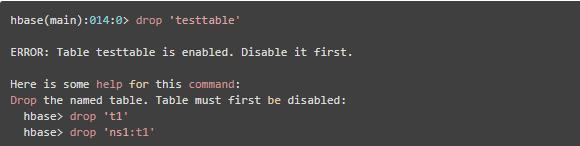
先对表失效,然后再删除,则可顺序删除表

(10)退出 hbase shell

以上就是使用hbase shell进行简单的测试和使用
8、HBase 管理页面
HBase 还提供了管理页面,供用户查看,可更加方便地查看集群状态
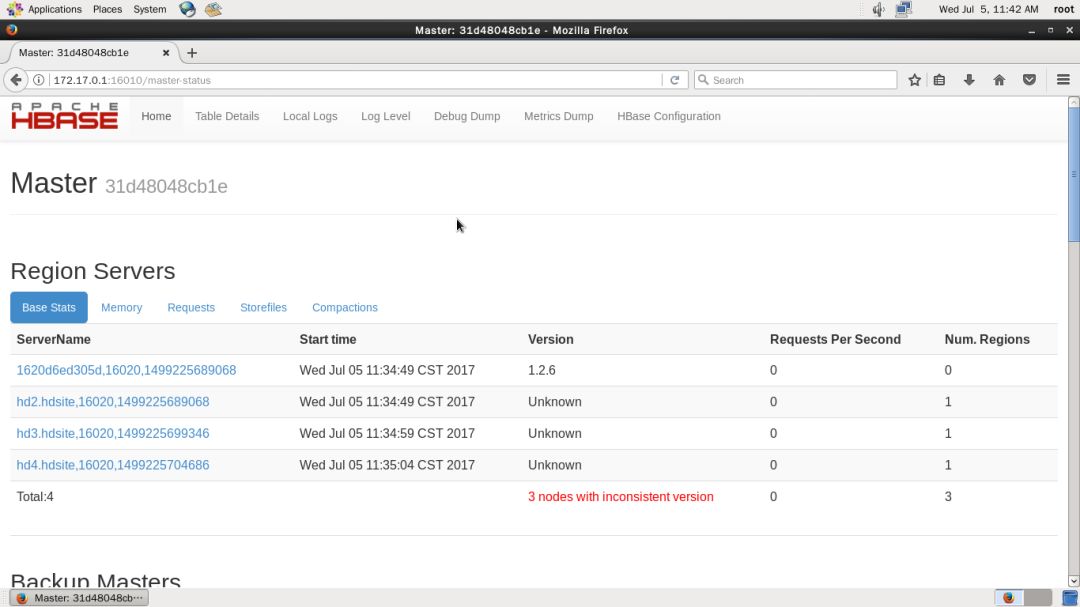
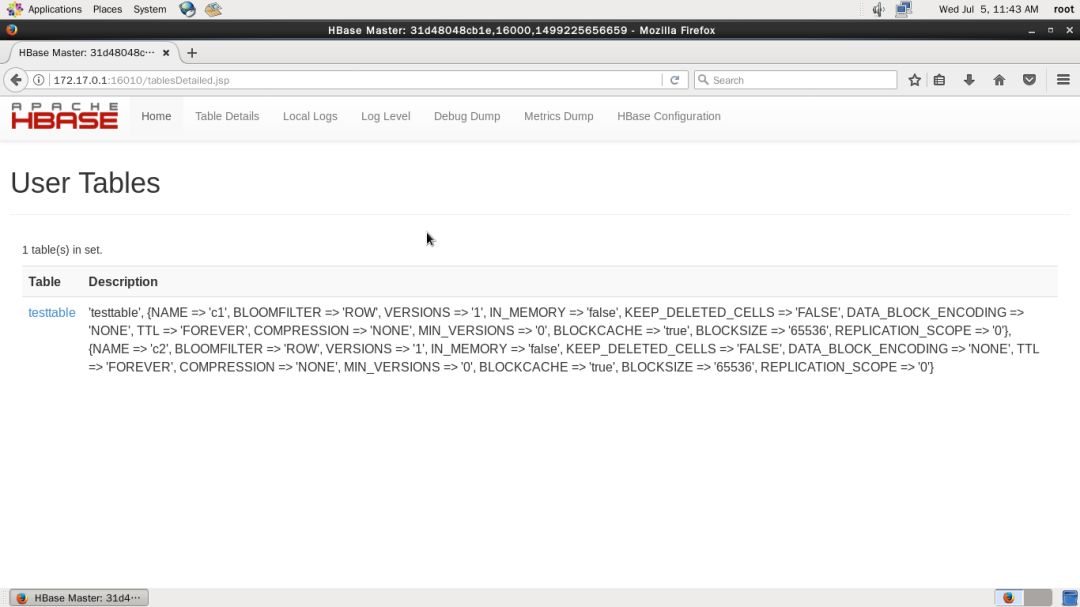
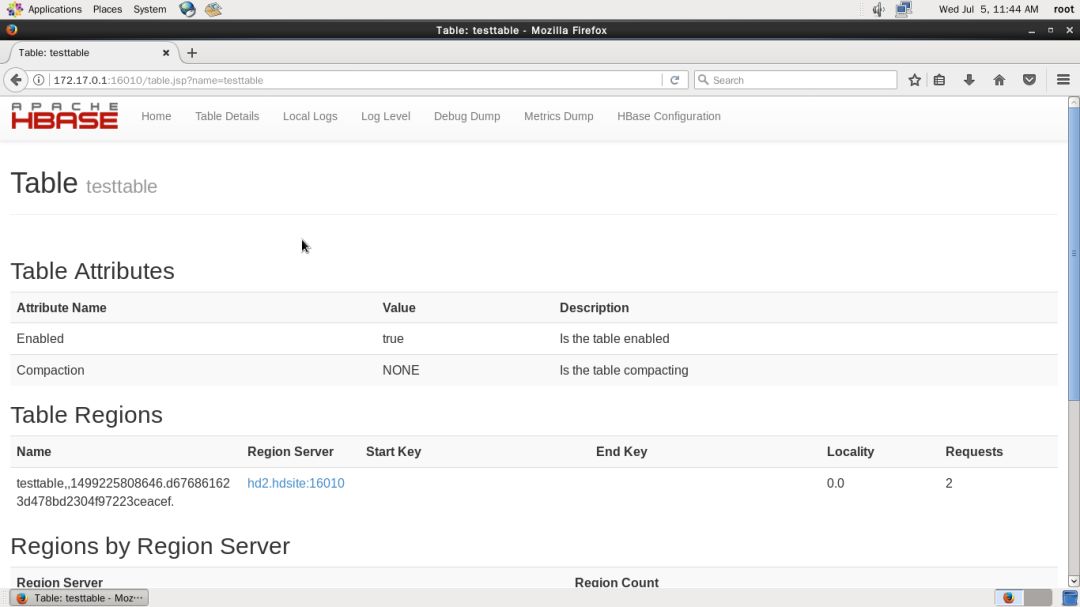
在主页的 Tables 下面也会列出表名出来,点击可查看某张表的信息,如下图
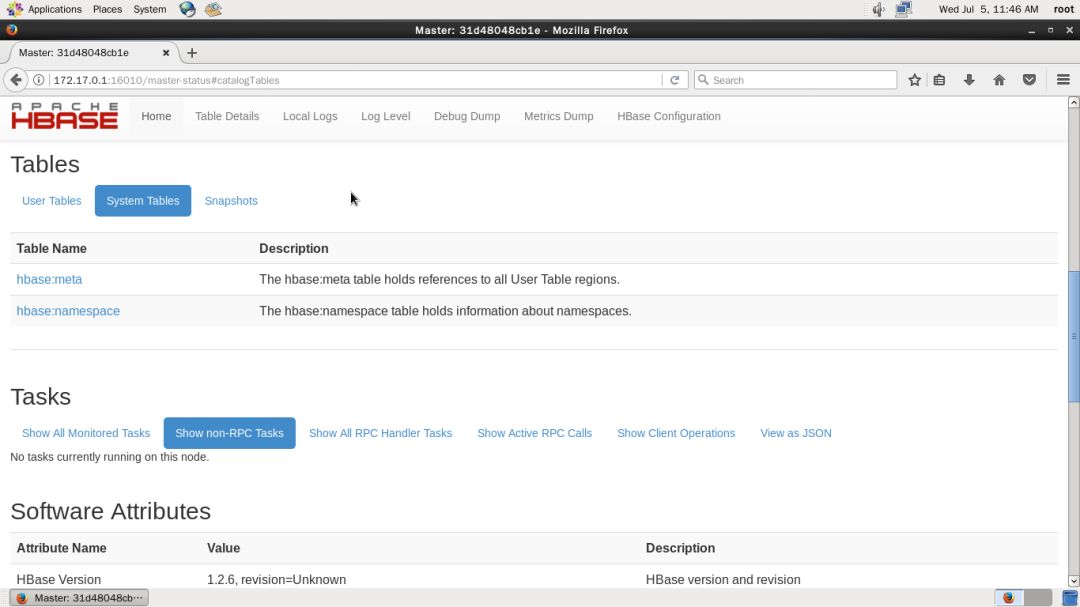
在 Tables 中点击 System Tables 查看系统表,主要是元数据、命名空间,如下图
以上就是Apache HBase集群配置,以及测试使用的详细过程,欢迎大家批评指正,共同交流进。

以上是关于超详细!教你一步一步搭建 Apache HBase 完全分布式集群的主要内容,如果未能解决你的问题,请参考以下文章