教你一步搭建Flume分布式日志系统
Posted 欢醉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教你一步搭建Flume分布式日志系统相关的知识,希望对你有一定的参考价值。
在前篇几十条业务线日志系统如何收集处理?中已经介绍了Flume的众多应用场景,那此篇中先介绍如何搭建单机版日志系统。
环境
CentOS7.0
Java1.8
下载
官网下载 http://flume.apache.org/download.html
当前最新版 apache-flume-1.7.0-bin.tar.gz
下载后上传到CentOS中的/usr/local/ 文件夹中,并解压到当前文件中重命名为flume170 /usr/local/flume170
tar -zxvf apache-flume-1.7.0-bin.tar.gz
安装配置
修改 flume-env.sh 配置文件,主要是添加JAVA_HOME变量设置
JAVA_HOME=/usr/lib/jvm/java8
设置Flume的全局变量
打开profile
vi /etc/profile
添加
export FLUME=/usr/local/flume170
export PATH=$PATH:$FLUME/bin
然后使环境变量生效
source /etc/profile
验证是否安装成功
flume-ng version
测试小实例
参考网上Spool类型的示例
Spool监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:
1) 拷贝到spool目录下的文件不可以再打开编辑。
2) spool目录下不可包含相应的子目录
创建agent配置文件
# vi /usr/local/flume170/conf/spool.conf a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir =/usr/local/flume170/logs a1.sources.r1.fileHeader = true # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Describe the sink a1.sinks.k1.type = logger a1.sinks.k1.channel = c1
spoolDir:设置监控的文件夹,当有文件进入时会读取文件的内容再通过sink发送,发送完成后会在文件名后加上.complete
启动flume agent a1
/usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/spool.conf -n a1 -Dflume.root.logger=INFO,console
追加一个文件到/usr/local/flume170/logs目录
# echo "spool test1" > /usr/local/flume170/logs/spool_text.log
在控制台,可以看到以下相关信息:
14/08/10 11:37:13 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:13 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:14 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /usr/local/flume170/logs/spool_text.log to/usr/local/flume170/logs/spool_text.log.COMPLETED 14/08/10 11:37:14 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:14 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:14 INFO sink.LoggerSink: Event: { headers:{file=/usr/local/flume170/logs/spool_text.log} body: 73 70 6F 6F 6C 20 74 65 73 74 31 spool test1 } 14/08/10 11:37:15 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:15 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:16 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:16 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown. 14/08/10 11:37:17 INFO source.SpoolDirectorySource: Spooling Directory Source runner has shutdown.
出现上面的内容就表明已经可以运行了,整个安装过程很简单,主要是配置。
至于分布式的需要设置source和sink。
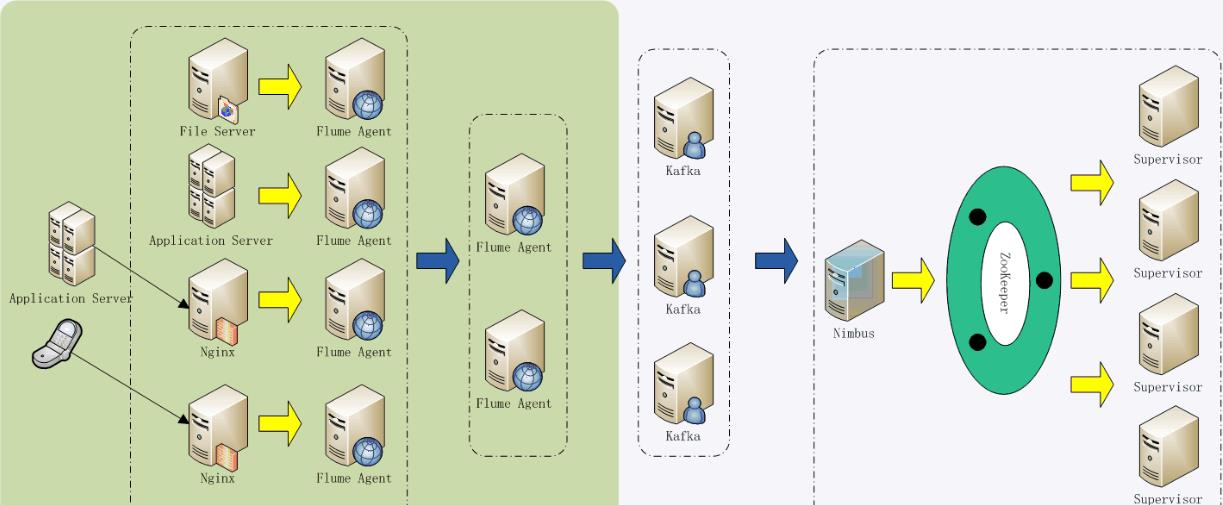
如上图,将每个业务中的Flume产生的日志再用一个Flume来接收汇总,然后将汇总后的日志统一发送给KafKa作统一处理,最后保存到HDFS或HBase中。上图中,每个业务中的Flume可以做负载和主备,由此可以看出有很强的扩展性。
以上是关于教你一步搭建Flume分布式日志系统的主要内容,如果未能解决你的问题,请参考以下文章