初探 HBase 复制
Posted 魅族开放平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初探 HBase 复制相关的知识,希望对你有一定的参考价值。
前言
魅族云服务在内地有北京、无锡、广东三个机房,2016年之前三个机房分别就近为用户提供服务,用户通过一个叫做GSLB的路由组件将请求路由到对应的机房,用户数据采用mysql主备存储,由于云服务用户量、用户数据量庞大,而MySQL服务器采用SSD磁盘,费用较高,为了应对用户量的增长,MySQL需要拆库扩容,而且扩容需要在凌晨非用户高峰期进行以免影响服务,2016年底云服务经过多重评估,决定将存储层从MySQL迁移到HBase,一方面可以大大降低服务器成本,另一方面期望通过三个机房数据的实时同步最终做到异地多活。
一
复制初始化
当使用Shell脚本启动HBase HRegionServer进程的时候,HBase复制相关类就开始初始化了,初始化完成后,每个从集群复制连接(Peer)都对应一个ReplicationSoure线程,ReplicationSource内部又会为每个WAL Group创建一个后台线程ReplicationSourceWorkThread,该后台线程一直扫描对应的WAL,只要WAL有数据变更(如HBase Client调用PUT,DELETE等操作写入数据)就会读取WAL内容进行复制,图1描述了这一初始化过程:
图1 HBase复制初始化过程
1. 初始化复制
新建与初始化类ReplicationQueues replicationQueues,实现类为ReplicationQueuesZKImpl,该类用于控制RegionServer需要复制的WAL队列,在ZK中会创建一个regionserver name的znode用来保存这个需要复制的WAL文件队列。
新建与初始化类ReplicationPeers replicationPeers,实现类为ReplicationPeersZKImpl,用于管理复制的状态,在ZK中会创建一个例如”/hbase/replication/peers/1”的znode用来保存这个从集群连接(peer)复制的状态(ENABLED or DISABLED)以及需要复制的表、列族。
新建类ReplicationTracker replicationTracker,实现类为ReplicationTrackerZKImpl,该类监听ZK 节点变化导致复制状态变更的事件,比如某台RegionServer宕机需要容灾(failover)。
新建类ReplicationSourceManager replicationManager,用来管理所有的ReplicationSource。
2. 将Replication类注册为WALActionListener
这样当WAL有滚动(Roll)的时候,会转调到ReplicationSource将WAL log添加到walGroup queue Map,以便ReplicationSourceWorkThread后台扫描并发送WAL内容到从集群。
3. RegionServer 复制容灾(replication faiover)处理。
检查是否有replicationQueues所属的RegionServer已经宕机(dead),如果有,则当前RegionServer接管宕机的RegionServer的复制
二
WAL复制
WAL复制是HBase复制核心步骤,数据变更将在这一步从主集群复制到从集群,图2描述了这一复制过程:
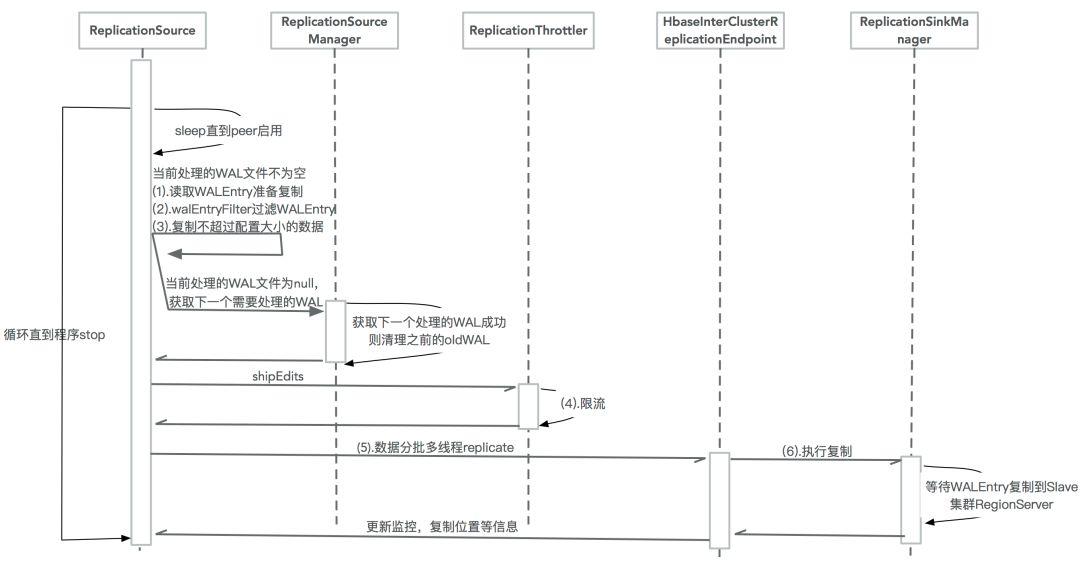
图2 HBase WAL复制
1. 读取WALEntry准备复制
WAL文件复制读取进度保存在Zookeeper。
WALEntry由WALEdit跟WALKey组成。
WALEdit是真实需要复制的数据。
WALKey记下了复制过的从集群的唯一标示符clusterId防止循环复制。
2. walEntryFilter过滤WALEntry
SystemTableWALEntryFilter过滤系统表的WALEntry。
ScopeWALEntryFilter过滤主集群列族REPLICATION_SCOPE!=1的键值对(KeyValue)。
TableCfWALEntryFilter过滤从集群没有开启复制的列族下的键值对。
3. 复制不超过配置大小的数据
每次读取的数据量大小不超过replication.source.size.capacity配置的值(默认64M)。
每次读取的WALEntry数量不超过replication.source.nb.capacity配置的值(默认25000)。
4. 限流
如果限流周期(100ms)内复制了超过带宽限制的数据量,则休眠 复制数据量/带宽*100 ms。
如果限流周期内复制的数据+该次需要复制的数据量>限流带宽,则休眠到下一个周期再复制。
5. 数据分批多线程复制
分批数为A (hbase.replication.source.maxthreads配置的值,默认10), B (WALEntry/100+1), C (slave集群regionServer数*replication.source.ratio配置的比例) 三者的最小值。
按RegionName分批,每批启动一个Replicator(callable线程)提交到线程池开始执行复制。
6. 执行复制
随机获取从集群的一台RegionServer执行复制。
调用ReplicationProtbufUtil.replicateWALEntry发送RPC请求执行复制。
三
RegionServer复制容灾
RegionServer由于硬件的故障或者负载过高宕机是很常见的,HBase复制使用Zookeeper来保证高可用,当一台RegionsServer故障离线时,Zookeeper会负责协调管理复制队列的转移。
以一个主集群包含3台RegionServer复制到一个peer_id=1的从集群为例,图3描述了正常情况下某个时间点上Zookeeper的znode层次结构,所有的RegionServer的znode都包含一个peer_id=1的znode,这个znode包含一系列需要复制的WAL文件HDFS路径(格式是 host,port,timestamp.XXX如master1,16010, 1514193806746.default.1514193808901 注意‘,’会被编码成‘%2C’)。

图3 HBase 正常复制Zookeeper znode
图4描述了RegionServer master1包含多个WAL日志的情况。

图4 HBase 正常复制master1多个WAL
主集群上的每台RegionServer都会监控集群中其他RegionServer是否宕机,一旦有RegionServer宕机,其他RegionServer都会收到通知,然后这些RegionServer就会竞争去Zookeeper上创建一个名为lock的znode,竞争成功的RegionServer会负责起这个离线RegionServer剩余WAL的复制权,如图5,假设RegionServer master1离线,剩下的2台RegionServer会竞争创建znode,假设RegionServer master2竞争成功,master2会将master1的复制queue迁移到他自己的peer znode下面。
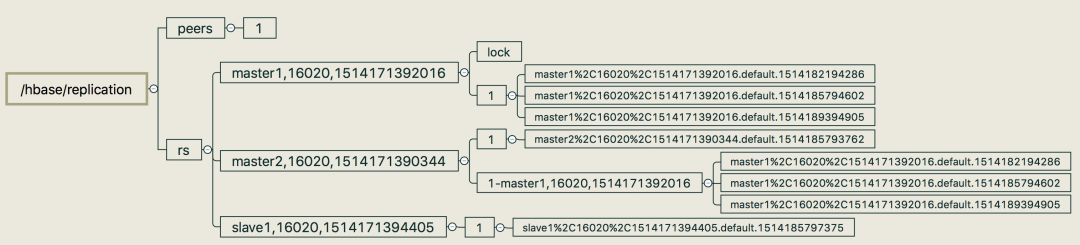

图5 RegionServer master1宕机
接下来RegionServer master2会为复制过来的master1的WAL 复制队列(queue)创建一个ReplicationSourceWorkerThread后台线程复制这些WAL,复制的流程同样如前所述(读取WALEntry过滤WALEntry执行WALEntry复制),当最后一个WAL复制完成后,这个复制队列的znode会被删除,因为这个复制队列所属的RegionServer已经离线,所以肯定不会有WAL再添加到这个复制队列。
假设接下来RegionServer master2也离线了,那么RegionServer slave1也会执行同样的接管过程,最终Zookeeper znode树形结构如图6所示。

图6 RegionServer master2宕机
即使之后RegionServer master1跟master2恢复服务,已经被接管的WAL复制队列仍然会由slave1负责,如图7所示。

图7 RegionServer master1,master2恢复
后记
2017年魅族云服务90%的数据存储已经由MySQL迁移到了HBase,每年节约成本数百万,通过HBase Replication保证了国内三机房间数据互通,上线一年多基本无故障(唯一一次导致复制大量延迟的事故是由于复制的数据量较大导致复制RPC超时)为云服务建设异地多活提供了基础保障。

魅族工程师讲堂:
“魅族开放平台”每周推出一篇魅族工程师的分享,如果觉得文章不错,就请分享给身边的朋友们吧~
魅族开放平台
干货分享 | 平台动态 | 数据报告
以上是关于初探 HBase 复制的主要内容,如果未能解决你的问题,请参考以下文章
将一张表的数据从 HBase 0.94 复制到 HBase 0.98