HBase集群间的主从复制原理
Posted 有心有梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase集群间的主从复制原理相关的知识,希望对你有一定的参考价值。
本文非原创,转载于小米运维的HBase复制详解一文。
复制,指的是持续的将同一份数据拷贝到多个地方进行存储,是各种存储系统中常见而又重要的一个概念,可以指数据库中主库和从库的复制,也可以指分布式集群中多个集群之间的复制,还可以指分布式系统中多个副本之间的复制。它的难点在于数据通常是不断变化的,需要持续的将变化也反映到多个数据拷贝上,并保证这些拷贝是完全一致的。
通常来说,数据复制到多个拷贝上有如下好处:
- 多个备份提高了数据的可靠性
- 通过主从数据库/主备集群之间的复制,来分离OLTP和OLAP请求
- 提高可用性,即使在单副本挂掉的情况下,依然可以有其他副本来提供读写服务
- 可扩展,通过增加副本来服务更多的读写请求
- 跨地域数据中心之间的复制,Client通过读写最近的数据中心来降低请求延迟
HBase中的Replication指的是主备集群间的复制,用于将主集群的写入记录复制到备集群。HBase目前共支持3种Replication:
- 异步Replication
- 串行Replication
- 同步Replication
在HBase中,集群之间的主从复制主要是基于WAL技术来实现的。WAL(Write-ahead logging)是数据库中的常用技术,主要用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入WAL中,这样即使缓存数据丢失,仍然可以通过WAL日志进行恢复。
异步复制
在主集群的每个RegionServer进程内部起了一个叫做ReplicationSource的线程来负责Replication,同时在备集群的每个RegionServer内部起了一个ReplicationSink的线程来负责接收Replication数据。ReplicationSource记录需要同步的WAL队列,然后不断读取WAL中的内容,同时可以根据Replication的配置做一些过滤,比如是否要复制这个表的数据等,然后通过replicateWALEntry这个RPC调用来发送给备集群的RegionServer,备集群的ReplicationSink线程则负责将收到的数据转换为put/delete操作,以batch的形式写入到备集群中。

因为是后台线程异步的读取WAL并复制到备集群,所以这种Replication方式叫做异步Replication,正常情况下备集群收到最新写入数据的延迟在秒级别。
串行复制
对于某个Region来说,严格按照主集群的写入顺序复制到备集群,其是一种特殊的Replication。同时默认的异步Replication不是串行的,主要原因是Region是可以移动的,比如HBase在进行负载均衡时移动Region。
假设RegionA首先在RegionServer1上,然后其被移动到了RegionServer2上,由于异步Replication是存在延迟的,
所以RegionA的最后一部分写入记录还没有完全复制到备集群上。在Region移动到RegionServer2之后,其开始接收新的写入请求,并由RegionServer2来复制到备集群,所以在这个时候RegionServer1和RegionServer2会同时向备集群进行复制,而且写入记录复制到备集群的顺序是不确定的。

如上图所示这种极端情况下,还会导致主备集群数据的不一致。比如RegionServer1上最后一个未同步的写入操作是Put,而RegionA被移动到RegionServer2上的第一个写入操作是Delete,在主集群上其写入顺序是先Put后Delete,如果RegionServer2上的Delete操作先被复制到了备集群,然后备集群做了一次Major compaction,其会删除掉这个Delete marker,然后Put操作才被同步到了备集群,因为Delete已经被Major compact掉了,这个Put将永远无法被删除,所以备集群的数据将会比主集群多。
解决这个问题的关键在于需要确保RegionServer2上的新写入操作必须在RegionServer1上的写入操作复制完成之后再进行复制。
所以串行Replication引入了一个叫做Barrier的概念,每当Region open的时候,就会写入一个新的Barrier,其值是Region open时读到的最大SequenceId加1。
SequenceId是HBase中的一个重要概念,每个Region都有一个SequenceId,其随着数据写入严格递增,同时SequenceId会随着每次写入操作一起写入到WAL中。
所以当Region移动的时候,Region会在新的RegionServer重新打开,这时就会写入一个新的Barrier,Region被移动多次之后,就会写入多个Barrier,来将Region的写入操作划分成为多个区间。
同时每个Region都维护了一个lastPushedSequenceId,其代表这个Region当前推送成功的最后一个写操作的SequenceId,这样就可以根据Barrier列表和lastPushedSequenceId来判断WAL中的一个写入操作是否能够复制到备集群了。
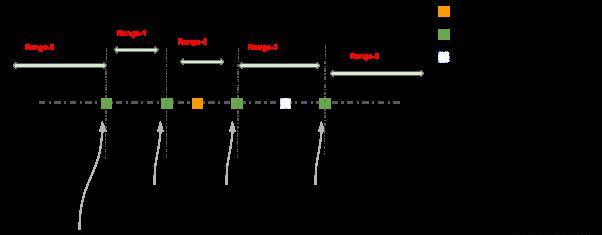
以上图为例,Pending的写入记录就需要等待lastPushedSequenceId推到Barrier2之后才能开始复制。
由于每个区间之间只会有一个RegionServer来负责复制,所以只有和lastPushedSequenceId在同一个区间内的RegionServer才能进行复制,并在复制成功后不断更新lastPushedSequenceId,而在lastPushedSequenceId之后各个区间的RegionServer则需要等待lastPushedSequenceId被推到自己区间的起始Barrier,然后才能开始复制,从而确保了Region的写入操作可以严格按照主集群的写入顺序串行的复制到备集群。
同步复制
同步Replication是和异步Replication对称的概念,其指的是主集群的写入操作必须被同步的写入到备集群中。异步Replication的最大问题在于复制是存在延迟的,所以在主集群整集群挂掉的情况下,备集群是没有已经写入的完整数据的,对于一致性要求较高的业务来说,是不能把读写完全切到备集群的,因为在这个时候可能存在部分最近写入的数据无法从备集群读到。
所以同步Replication的核心思路就是在写入主集群WAL的同时,在备集群上写入一份RemoteWAL,只有同时在主集群的WAL和备集群的RemoteWAL写入成功了,才会返回给Client说写入成功。这样当主集群挂掉的时候,便可以在备集群上根据Remote WAL来回放出来主集群上所有写入记录,从而确保备集群和主集群数据的一致。
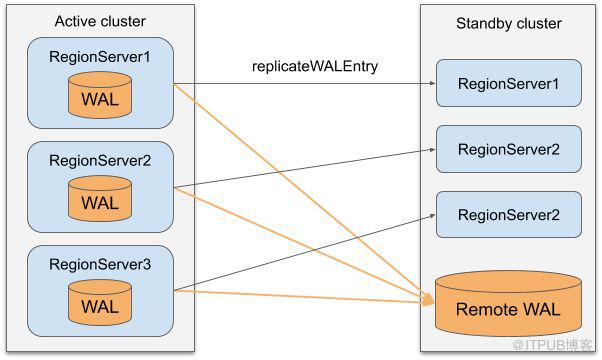
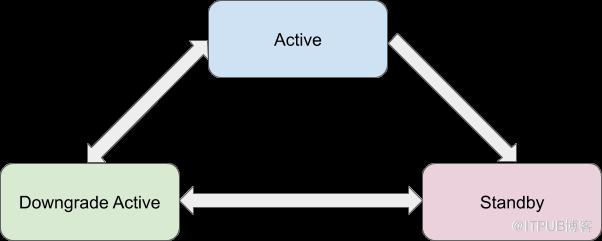
需要注意的是,同步Replication是在异步Replication的基础之上的,也就是说异步Replication的复制链路还会继续保留,同时增加了新的写Remote WAL的步骤。对于具体的实现细节来说,首先是增加了一个Sync replication state的概念,其总共有三个状态, 分别是Active,Downgrade Active和Standby。这几个状态的转换关系如下图所示,Standby在提主的时候需要首先提升为Downgrade Active,然后才能提升为Active。但是Active是可以直接降级为Standby的。目前这个状态是保存在ReplicationPeerConfig中的, 其表示一个集群在这个ReplicationPeer中处于哪个状态。
然后实现了一个DualAsyncFSWAL来同时写主集群的WAL和备份集群的Remote WAL。写WAL的操作是对于HDFS的rpc请求,其会有三种结果: 成功,失败或者超时。
当超时的时候,对于HBase来说结果是不确定的,即数据有可能成功写入到WAL或Remote WAL里了,也有可能没有。只有同时写成功或者同时写失败的时候,主集群和备集群才会有一样的WAL。
如果是主集群写WAL成功,写Remote WAL失败或者超时,这时候主集群WAL里的数据就有可能比备集群的Remote WAL多。相反如果写备集群Remote WAL成功了,而主集群的WAL写失败或者超时了,备集群的Remote WAL里的数据就有可能比主集群多。
当两边都超时的时候, 就不确定那边多了。所以同步复制的关键就在于在上述情况下,如何确保主备集群数据的最终一致。即在切换主备集群的时候,Client应该始终从主备集群看到一致的数据。而且在主备没有达到一致的中间状态时,需要一些限制来确保Client没法读到这种中间不一致的结果。所以总结一下就是主备集群最终一致,但对于Client来说是强一致,即成功写入的数据无论主备集群都要一定能读到。具体的实现细节可以参考HBaseCon Asia 2018:HBase at Xiaomi[1]。
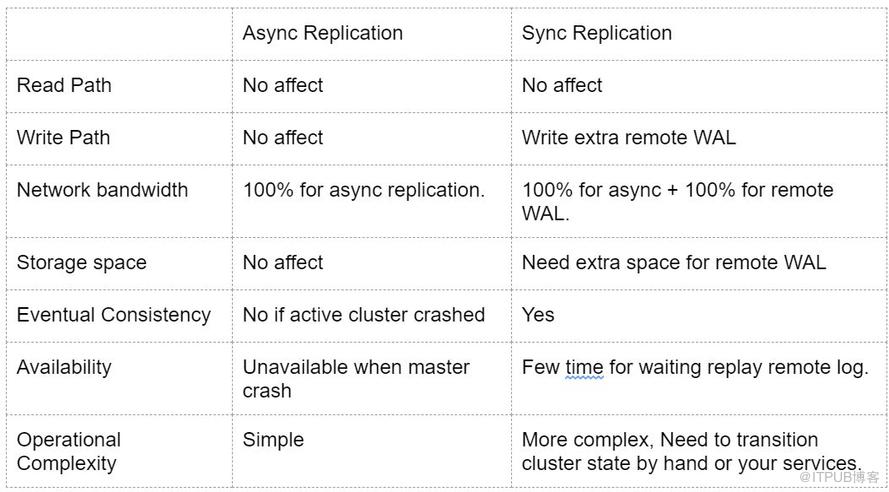
对比异步复制来看,同步复制主要是影响的写路径,从我们的测试结果上来看,大概会有14%的性能下降,后续计划在HBASE-20422[2]中进行优化。
参考链接:
以上是关于HBase集群间的主从复制原理的主要内容,如果未能解决你的问题,请参考以下文章