从MySQL到HBase:数据存储方案转型的演进
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从MySQL到HBase:数据存储方案转型的演进相关的知识,希望对你有一定的参考价值。
作者介绍
杨宏志,知乎首页架构负责人,主要负责首页工程化建设、工程架构优化、性能提升等工作。知乎专栏:https://zhuanlan.zhihu.com/c_195355141
本文大致会从以下几个方面入手,谈谈笔者对数据存储方案选型的看法:
从mysql到HBase集群化方案的演化
MySQL与HBase的性能取舍
不同方案的优化思路
总结
一、集群化方案
MySQL与HBase说到最核心的点,是一种数据存储方案。方案本身没有对错、没有好坏,只有合适与否。相信多数公司都与MySQL有着不解之缘,部分学校的课程甚至直接以SQL语言作为数据库讲解。我想借自身经历,先来谈谈MySQL应用的演化。
只有MySQL
笔者之前曾在一家O2O创业公司工作,公司所有数据都存储在同一个MySQL里,而且没有任何主备方案。相信这是很多初创公司会用到的一个典型解决办法,当时这台MySQL为用户、订单、物流服务,同时也为线下分析服务。
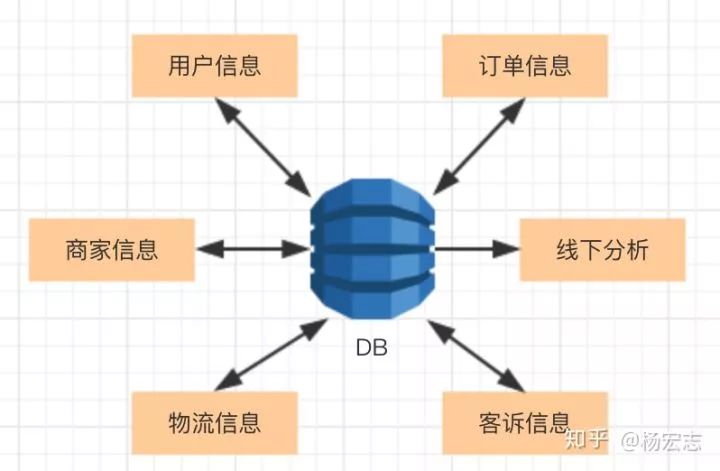
单实例的问题:
一旦MySQL挂了,服务全部停止;
一旦MySQL的磁盘坏了,公司的所有服务都没有了 (一般会定时备份数据文件)。
主从方案
随着业务增加,单个DB是无法承载这么多请求的。于是就有了主从复制、读写分离的解决方案。
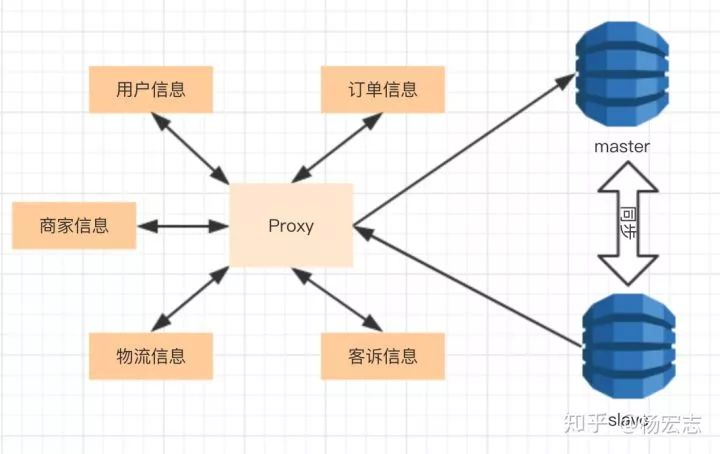
master只负责写请求,slave同步master用来服务读请求:
为了扩展读能力可以增加多个slave;
允许slave同步有一定的延迟;
一致性要求严格的,可以指定读主库。
主从功能的问题:
需要增加管理Proxy层,分配写请求、读请求;
节点故障:其它节点应该快速接管故障节点的功能。
垂直拆分
业务继续增长,master甚至无法承载所有的写请求,数据库需要按业务拆分。
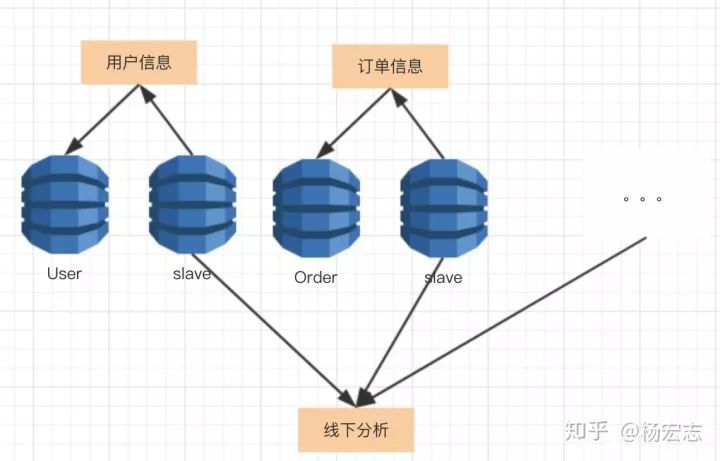
垂直拆分的问题:
线下分析,需要在业务代码里join各个表。因为拆成多个库,已经无法join了。
不容易做数据库的事务性,用户余额减少与下单成功的情况下无法使用MySQL的事务功能。
水平拆分
业务继续增长,订单表有大量的并发写入,而且已经有了几千万行数据。
单个库无法承载大量的并发写入;
上千万行的大表,数据写入可能需要调整一棵巨大的B+树;
上千万行,B+树过深,读写需要更多的磁盘IO;
很多老数据访问较少,B+树上层缓存的部分信息无用;
……
参考:大众点评订单系统分库分表实践
https://zhuanlan.zhihu.com/p/24036067
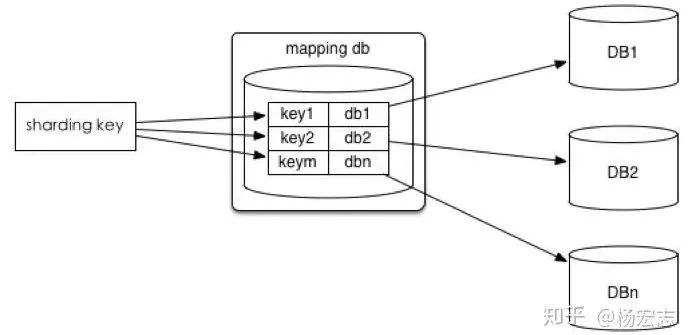
水平分库/分表带来的问题:
维护map方案;
辅助索引只能局部有效;
由于分库,无法使用join等函数;由于分表count、order、group等聚合函数也无法做了;
扩容:需要再次水平拆分的:修改map,迁移数据……
MySQL的主要瓶颈,单机单进程。CPU有限、内存/磁盘功能、连接数有限、网卡吞吐有限……
集群的限制点:
关系型数据库,纵向的外键相互join;
范式参考链接:https://zhuanlan.zhihu.com/p/20028672
数据库事务性,基于单机的锁机制,无法扩展到集群中使用;
全局有序列性基于B+树,数据有序聚合存储,集群化后无法保证;
数据本地存储,扩容需要迁移数据。
集群的方案:
放弃部分功能,辅助索引检索、join、全局事务性、聚合函数等;
水平拆分:存储KV化,用机械的map思路实现集群;
扩容方案:手动导数据,开发数据迁移脚本;
事务性:两阶段事务、paxos、单库事务……
备份容灾:从节点同步主节点,但有一定的数据延迟;
服务稳定性:主节点挂了,Proxy会将从节点升级为主节点;从节点挂了会被其它从节点替换。
水平拆分:
region:拆分后的子表;
Region Server:管理这些数据的server,相当于一个MySQL实例;
.META.表存储拆分信息map<row, server>。
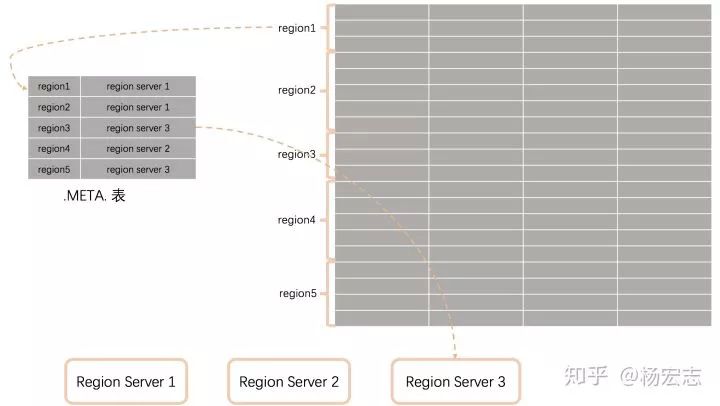
单个region过大,RegionServer会将region均分为两个(自动、手工)。然后更新.META.表。
扩容方案:
RegionServer向HMaster汇报状态。HMaster为RegionServer负载均衡,调整其负责的region 。
增/删RegionServer后,会为重新调整region的分配方式。
服务稳定性:
RegionServer只是计算单元,挂掉后Hmaster可以随便再找一个节点代替坏节点服务。
事务性:
HBase只保证行级事务,单行数据肯定存在同一台机器(单机事务很好做)。
备份容灾:
数据使用HDFS存储,多复本,任何一个复本挂掉都不影响功能;
RegionServer只是计算单元,挂掉后不影响服务。
二、性能取舍
HBase:
Client会通过Zookeeper定位到 .META. 表;
根据 .META. 查找需要服务的RegionServer,连接RegionServer进行读写;
Client会缓存 .META. 表信息,下次可以直接连到RegionServer 。
MySQL:
Client通过Proxy,查找需要连接的MySQL实例,连接并进行读写。
Rquest的路由流程,MySQL与HBase基本一致,那么RegionServer与MySQL的性能差异如何呢?
新增
为什么MySQL建议自增主键?(MySQL随机插入的代价)
主键索引是有序的B+树结构,新增条目的ID肯定是最大的,新增给B+结构带来的调整最小;
主键索引是聚簇的:新增条目,ID是最大的。其data追加在上一次插入的后面,磁盘更容易顺序写。
辅助索引,插入基本是随机的:
插入条目,可能会引起B+树结构很大的调整。
HBase可以随机插入:
HBase的所有插入只是写入内存memstore,只保证内存数据的有序即可(很快、很容易);
为防止数据丢失写入memstore前,先写入wal(可以关闭,速度更快);
HBase没有辅助索引需要维护;
memstore写满了,申请一块新的内存,旧的memstore被后台线程刷盘,存入HFile。
修改
MySQL数据变化引起存储变动:
数据块大小变化:磁盘空间不足,可能需要调整磁盘存储结构,引起大量的磁盘随机读写;
辅助索引发生变化:可能需要重新调整辅助索引B+树。
HBase直接将变化写入到memstore,没有其它开销。
删除
MySQL数据删除:
直接操作B+树的节点,肯定需要刷新磁盘;
如果引起树结构变化,甚至可能需要多次刷新磁盘。
HBase只是在memstore记录删除标记,没有其它开销。
HBase写入内存+后台刷盘(最多是WAL,磁盘顺序写);MySQL需要维护B+树,大量的磁盘随机读写。
MySQL要求尽量追加写(自增 ID),速度较慢;HBase可以随机插入,速度很快。
MySQL读得快
MySQL数据是本地存储的,HBase是基于HDFS,有可能数据不在本地。
B+ 树天然的全局有序
根据主键查询,可以快速定位到数据所在磁盘块,只需要极少的磁盘IO即可拿到数据:通过缓存高层节点,主健查询只需要一次磁盘IO就可拿到数据;MySQL单表行数一般建议不会超过2千万,千万行以下的大表,B+树只需2~3层即可;
辅助索引,提供快速定位能力:辅助索引B+树,可以快速定位到最终所需的主键ID,根据主键ID可以快速拿到所需信息。
HBase只有局部信息,没有辅助索引
查询会优先查找memstore,如果没有会查找Hfile(存储结构类似B+树)。如果第一个Hfile中没有所需的信息,则需要去第二、第三个Hfile中查询;如果查询的数据恰好在memstore,第一个Hfile,HBase会优于MySQL;平均下来,HBase读性能一般。减少Hfile数据以提速,小的HFile合并成大的HFile文件。这种存储结构叫LSM树(Log-structured merge-tree);
如果需要检索特定的列,可能需要遍历所有Hfile,成本巨高。
MySQL成也B+,败也B+;HBase成也LSM,败也LSM。
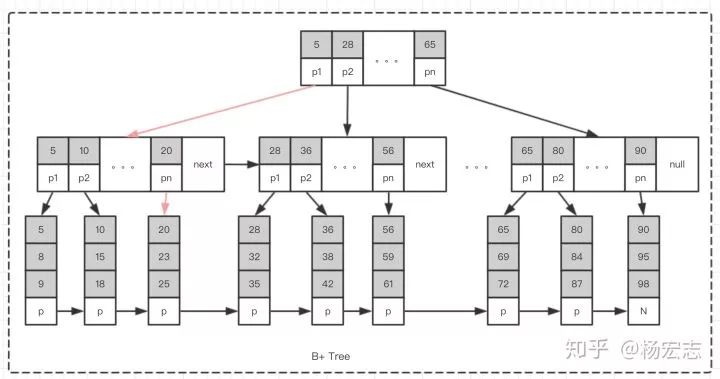
B+ 树
查询“值为25”的节点,只需要2次定位即可。
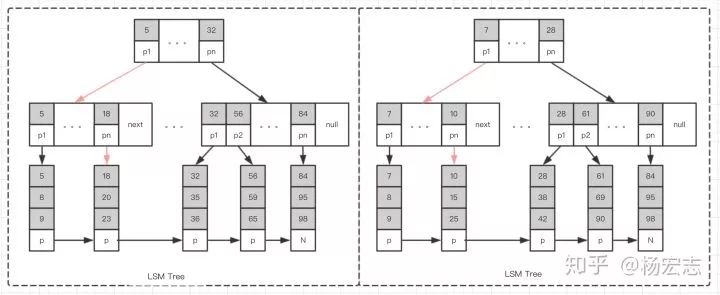
LSM树
查询“值为25”的节点,只需要4次定位即可。
三、优化思路
异步化
后台线程将memstore写入Hfile;
后台线程完成Hfile合并;
wal异步写入(数据有丢失的风险)。
数据就近
blockcache,缓存常用数据块:读请求先到memstore中查数据,查不到就到blockcache中查,再查不到就会到磁盘上读,把最近读的信息放入blockcache,基于LRU淘汰,可以减少磁盘读写,提高性能;
本地化,如果Region Server恰好是HDFS的data node,Hfile会将其中一个副本放在本地;
就近原则,如果数据没在本地,Region Server会取最近的data node中数据。
快速检索
基于bloomfilter过滤:
正常检索,RegionServer会遍历所有Hfile查询所需数据。其中,需要遍历Hfile的索引块才能判断Hfile中是否有所需数据;
BloomFiler存储HFile的摘要,可以通过极少磁盘IO,快速判断当前HFile是否有所需数据:
行缓存:快速判断Hflie是否有所需要的行,粒度较粗,存储占用少,磁盘IO少,数据较快;
列缓存:快速判断Hfile是否有所需的列,粒度较细,但存储占用较多。
基于timestamp过滤:
HFile基于日志追加、合并,维护了版本信息;
当查询1小时内提交的信息时,可以跳过只包含1小时前数据的文件。
HFile存储结构:
HFile存储格式
参考链接:
https://link.zhihu.com/?target=https%3A//blog.csdn.net/yangbutao/article/details/8394149
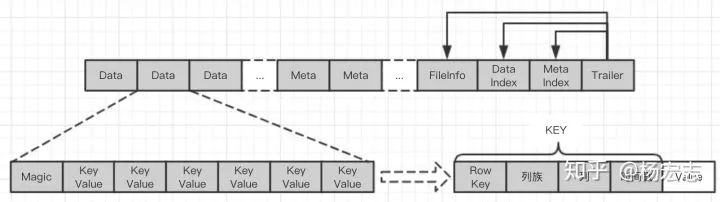
Trailer存储整个Hfile的定位信息;
DataIndex存储Data块的索引信息:Data存储为一组磁盘块,存储数据信息;DataIndex功能类似于B+树的非叶子节点;Data每个磁盘块中的数据按key有序,加载到内存后可以用二分查找定位;Key按行 + 列族 + 列 + 时间戳生成,按字典序排序(最佳查询方式:最左匹配);
MetaIndex存储Meta的索引信息,Meta存储一系列元信息;MetaIndex功能类似于B+树的非叶子节点;Meta存储bloomfiler等辅助信息。
查询缓存
将SQL执行结果放入缓存。
缓存B+高层节点
一千万行的大表,一般只需要一棵3层的B+树,其中索引节点 (非叶子节点) 的大小约20MB。完全可以考虑将大部叶子节点缓存,基于主键查询只需要一次IO。
减少随机写——缓冲:延迟写/批量写
上节提到,B+树通过自增主键大量减少随机插入。由于辅助索引的存在,插入、修改、删除操作,辅助索引可能引起大量的随机IO。
插入缓冲:只是将被插入数据写入insert buffer;定期将其merge到B+树;
修改缓冲:类似于insert buffer的思路。
减少随机读——MRR
SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000;
# 普通操作分解:
key_part1= 1000, key_part2=1000, id = 1
select * from t where id=1
key_part1= 1001, key_part2=1000, id = 10
select * from t where id=10
...
# MRR 操作分解:
SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000;
key_part1= 1000, key_part2=1000, id = 1
buffer.append(1)
key_part1= 1000, key_part2=1000, id = 10
buffer.append(10)
...
sort(buffer)
select * from t where id in (buffer)
索引下推
MySQL的server处理完索引后,会将索引其它部分传给引擎层;
引擎层根据过滤条件过滤掉无用的行,减少数据量,进而优化server的性能。
InnoDB的辅助索引
B+树全局有序,叶子节点存储的是主键。基于辅助索引定位主键,再用主键定位数据。MySQL水平切分后,没办法跨库维持建立全局有序索引:
单实例维护索引,丧失了全局有序性;
再做一个基于新索引分库方案,丧失了辅助索引维护的事务性。
HBase相同问题
仿照InnoDB实现辅助索引,辅助索引可以做成单独的key,其value是被索引行的key;
可以做到全局信息的维护,但没法保证事务性。
TTL:基于后台合并,TTL很容易做;
数据多版本支持:基于“追加”,HBase天然的可以支持多版本;
-
版本数量:基于后台合并,可以将太旧版本干掉。
四、总结
不知道BigTable的前辈们是出于什么思路,本人冒昧揣测一下,多少应该是受到SQL数据库的影响。个人感觉,这些或许就是一脉相承的演进,至少用这种思路学习不显突兀。HBase不是凭空而来,也绝对不是解决所有问题的万能灵丹。
最直接的存储思路肯定是“文件”,当“文件”不能满足需求,就有了数据的组织方式,进而演进到关系数据库如MySQL。
MySQL以其“单机”很好地解决了ACID问题,但是,性能再好的“单机”势必演变成“单点”瓶颈,进而,分布式思路成为必然。
最简单的是扩展读,“无限”挂slave;进而拆分写节点,多点写入:垂直拆库、水平拆库。一旦选择分布式,就涉及如何主从一致、如何发现节点、如何运维、ACID的如何保证等问题。
进而就是一系列分布式方案,而HBase就是其中一种解决思路——只读主库保证一致,水平拆分、zk等机制保证自动运维、单行级ACID。至于性能方面,由于存储思路不同,MySQL与HBase分别取舍了不同的读写性能。继而,就衍生出了如何针对性进行优化。
以这种思路,HBase不是凭空出现。以个人浅显的目光所及,没有完美的架构,也没有绝对厉害的设计。固然SQL类数据库有其独领风骚的场景,NoSQL数据库自然也有纵横驰骋的疆域,无论是哪种架构,都有自己鞭长莫及的角落。
所以,应该说任何一种方案都没有完美,只有合适。而所有的合适都是演变而来,万变不离其宗:更好的解决问题。
近期热文
近期活动
以上是关于从MySQL到HBase:数据存储方案转型的演进的主要内容,如果未能解决你的问题,请参考以下文章