亿级数据从 MySQL 到 Hbase 的三种同步方案与实践
Posted Java编程指南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了亿级数据从 MySQL 到 Hbase 的三种同步方案与实践相关的知识,希望对你有一定的参考价值。
2.工欲善其事,必先利其器
2.1 环境需知
实验的环境有:
-
MySQL -
Hadoop伪分布式/完全分布式 -
HBase -
Phoenix -
Zookeeper -
Kafka -
Maxwell -
Flink
2.2 伪分布式环境部署
2.2.1.准备工作
【JAVA】
★https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
”

【用户】
sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
vi /etc/sudoers
编辑上述文件:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL # 添加此行
light@city:~$ sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
useradd:“hadoop”组不存在
light@city:/home$ sudo groupadd hadoop
再次执行即可:
light@city:~$ sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
设置或修改密码:
sudo passwd hadoop
【SSH】
安装ssh
sudo apt-get install openssh-server
配置免密登陆
su - hadoop
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
然后输入
ssh localhost
此时不需要输入密码,说明成功!
注意:关于ssh免秘登陆失败问题,大家可以通过以下方法进行尝试,大部分问题在于目录及文件权限!
sudo chmod 755 $HOME
sudo chmod 600 id_rsa
sudo chmod 600 id_rsa.pub
sudo chmod 644 authorized_keys
2.2.2 伪分布式
【Hadoop】
下载及安装
在下列镜像中下载Hadoop版本,我下载的3.0.2。
★https://mirrors.cnnic.cn/apache/hadoop/common/
”
wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.0.2/hadoop-3.0.2.tar.gz
tar zxvf hadoop-3.0.2.tar.gz
sudo mv hadoop-3.0.2 /usr/local/hadoop
配置
编辑etc/hadoop/core-site.xml,configuration配置为
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
sudo netstat -alnp | grep 9000

会发现9000端口被php-fpm给占用了,所以这里得修改为其他端口,比如我修改为9012,然后可以再次执行这个命令,会发现没被占用,说明可行!
编辑etc/hadoop/hdfs-site.xml,configuration配置为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
初始化
格式化HDFS
bin/hdfs namenode -format
注意:格式化执行一次即可!
启动NameNode和DataNode
sbin/start-dfs.sh
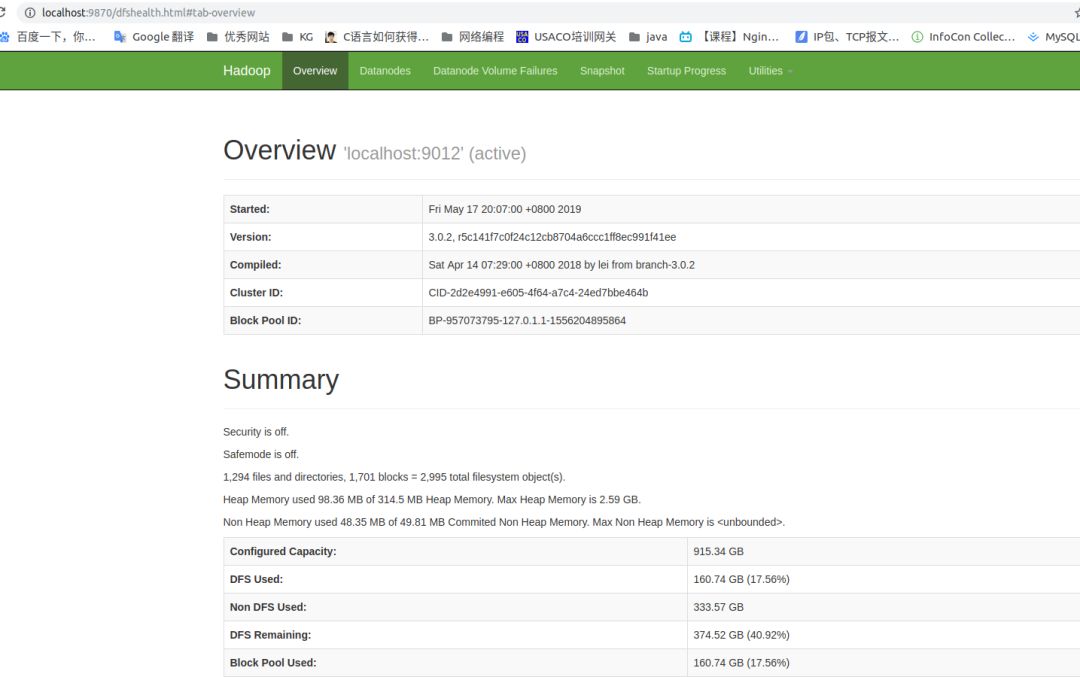
这时在浏览器中访问http://localhost:9870/,可以看到NameNode相关信息。
http://localhost:9864/查看DataNode相关信息。
由于hadoop3.x版本与2.x版本监听端口不一样,所以如果还是原先的50070便访问不到相关信息,不知道上述9870或者9864,没关系,可以通过下面命令查看!
输入netstat命令即可查看tcp监听端口:
sudo netstat -ntlp
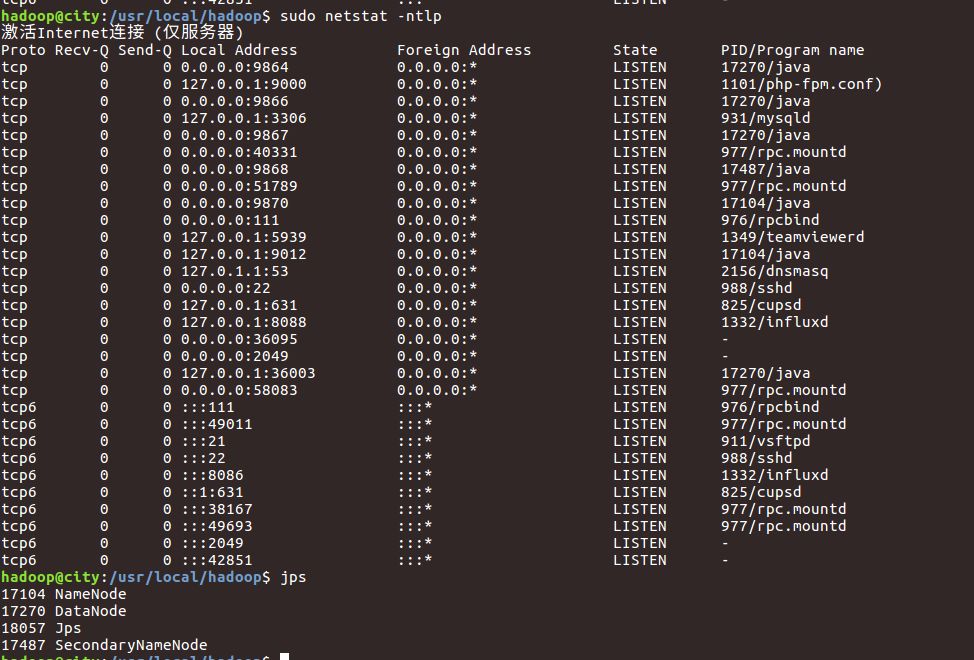
上述两个重要端口,9864后面可以看到进程ID为17270,通过JPS查看可以看到对应DataNode,9870类似方法。
配置YARN
编辑etc/hadoop/mapred-site.xml,configuration配置为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑etc/hadoop/yarn-site.xml,configuration配置为
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动YARN
sbin/start-yarn.sh
查看进程:
Jps
NodeManager
SecondaryNameNode
NameNode
ResourceManager
DataNode
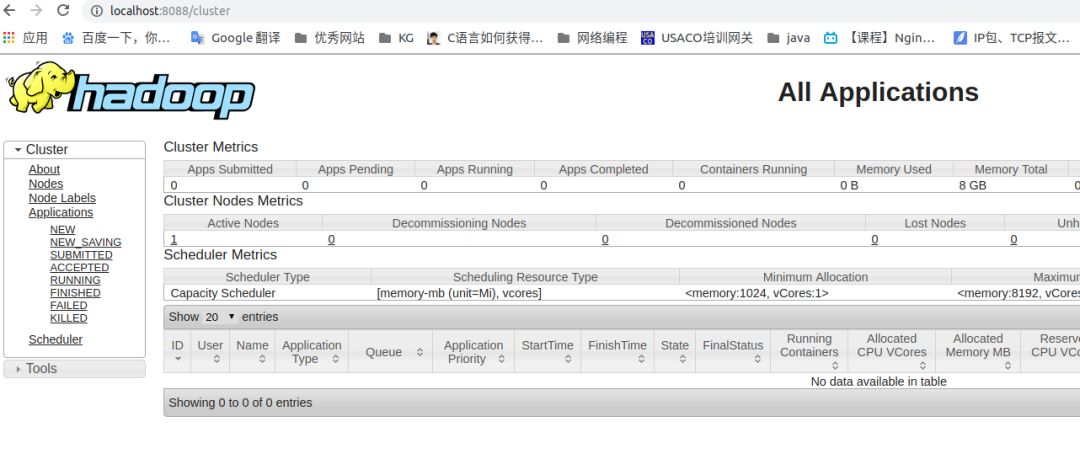
YARN就是上述的资源管理:ResourceManager。
同理,可以通过上述方法查看ResourceManager的端口,默认为8088。
浏览器输入:http://localhost:8088/cluster
启动与停止
启动:
sbin/start-dfs.sh
sbin/start-yarn.sh
停止:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
至此,伪分布式搭建完毕!后面开始HBase与Phoenix搭建!
【HBase】
下载安装
★https://mirrors.cnnic.cn/apache/hbase/
”
wget https://mirrors.cnnic.cn/apache/hbase/stable/hbase-1.4.9-bin.tar.gz
tar zxvf hbase-1.4.9-bin.tar.gz
sudo mv zxvf hbase-1.4.9-bin /usr/local/hbase
单机HBase配置
编辑conf/hbase-site.xml,configuration配置为
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9012/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>
-
启动
bin/start-hbase.sh
jps查看进程:
HMaster
Jps
-
终端
bin/hbase shell
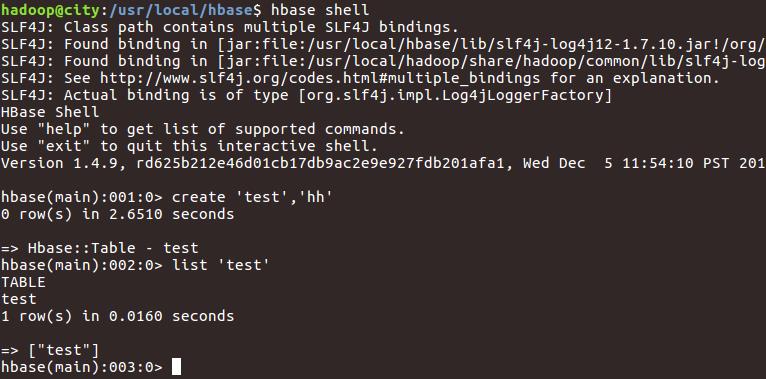
如果想要关闭HBase,则输入:
bin/stop-hbase.sh
HBase伪分布式配置
编辑conf/hbase-site.xml,configuration中添加
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
然后修改root由本地文件系统到HDFS,编辑conf/hbase-site.xml,hbase.rootdir值由
file:///home/hadoop/hbase
修改为
hdfs://localhost:9012/hbase
★注意后面的端口号9012,需要保证与Hadoop DFS配置中的fs.defaultFS相同!
”
这样子修改后,会在hdfs文件系统中看到HBase目录,当然你也可以不用配置此项!
上述配置完毕后,保存后,重启HBase即可!
【封装】
每次启动这些输入太多命令,太繁琐,直接一个bash脚本搞定,首先进入/usr/local,然后再运行这个脚本!
启动脚本:
#!/bin/bash
hadoop/sbin/start-dfs.shkuangjia
hadoop/sbin/start-yarn.sh
hbase/bin/start-hbase.sh
停止脚本:
#!/bin/bash
hadoop/sbin/stop-dfs.sh
hadoop/sbin/stop-yarn.sh
hbase/bin/stop-hbase.sh
【zookeeper】
由于Hbase自带了zookeeper,一开始使用自带的,后来发现出了很多问题,换成自己配置zookeeper,配置方法如下:
最近做的数据迁移,当上游数据流向下游过大的时候,HBase就会崩溃。HBase自带的Zookeeper出了问题,就尝试自己安装独立的Zookeeper。
(1)禁用HBase自带的Zookeeper
修改 ./conf/hbase-env.sh
export HBASE_MANAGES_ZK=false(如果值为true,则使用自带的Zookeeper,会随着HBase一起启动)
(2)安装及配置独立Zookeeper
Zookeeper最新的版本可以通过官网获取
wget http://apache.fayea.com/zookeeper/zookeeper-xxx/zookeeper-xxx.tar.gz
tar xfz zookeeper-xxx.tar.gz
mv zookeeper-xxx /usr/local/zookeeper
★拷贝配置文件
”
cd zookeeper-xxx/conf/
cp zoo_sample.cfg zoo.cfg
★修改配置项
”
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
dataDir:Zookeeper保存节点数据的目录。dataLogDir:Zookeeper保存节点数据的日志。
如果没有这个目录,就创建一下。
(3)HBase配置
★拷贝 zoo.cfg 到 hbase/conf/ 目录下
”
cp zoo.cfg /usr/local/hbase/conf/
这是官方文档推荐的做法,如果不拷贝 zoo.cfg,在 hbase-site.xml 中也可以对Zookeeper进行相关配置,但HBase会优先使用 zoo.cfg(如果有的话)的配置
★修改 hbase-site.xml
”
在原文件上加入:
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
如果不加的话,在启动独立安装的Zookeeper后,HBase不能正常启动。
(4)启动Zookeeper
./bin/zkServer.sh start
(5)检查服务是否启动
ps -ef | grep zookeeper
(6)启动HBase
在成功启动Zookeeper后,就可以启动HBase了:
./bin/start-hbase.sh
【Phoenix】
版本要与HBase相匹配!
下载apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz
★安装
”
tar -xvf apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz
mv apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz /usr/local/phoenix
★配置
”
将hbase-site.xml配置文件拷贝到phoenix的bin目录下
★启动
”
首先启动zookeeper与hbase。
hadoop@city: ./start_zk.sh
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@city: ./start_hbase.sh
running master, logging to /usr/local/hbase/logs/hbase-hadoop-master-city.out
: running regionserver, logging to /usr/local/hbase/logs/hbase-hadoop-regionserver-city.out
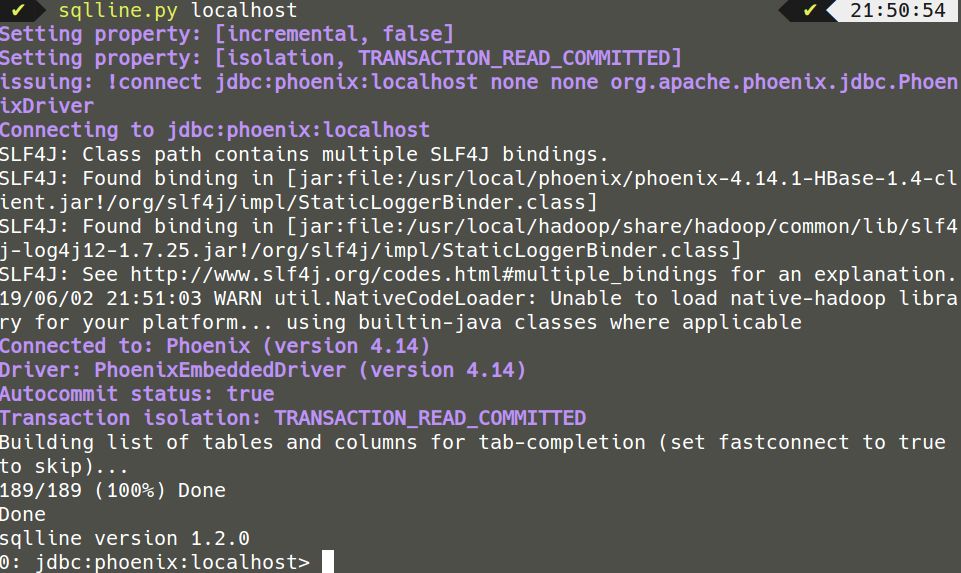
启动phoenix:
sqlline.py localhost
【Kafka】
★什么是Kafka?
”
Kafka 是一种分布式的,基于发布 / 订阅的消息系统。在这里可以把Kafka理解为生产消费者模式。
Kafka是使用Java开发的应用程序,Kafka需要运行Zookeeper,两者都需要Java,所以在需要安装Zookeeper和Kafka之前,先安装Java环境。
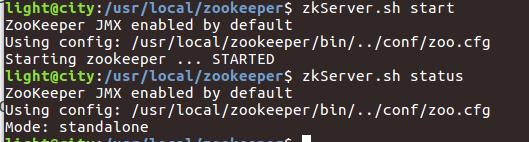
★启动Zookeeper
”
直接输入zkServer.sh start即可!
★Kafka安装及配置
”
★http://kafka.apache.org/downloads
”
同上述安装,这里下载.tgz文件,也是解压后移动到/usr/local即可!
关于配置文件可以直接采用默认的即可。
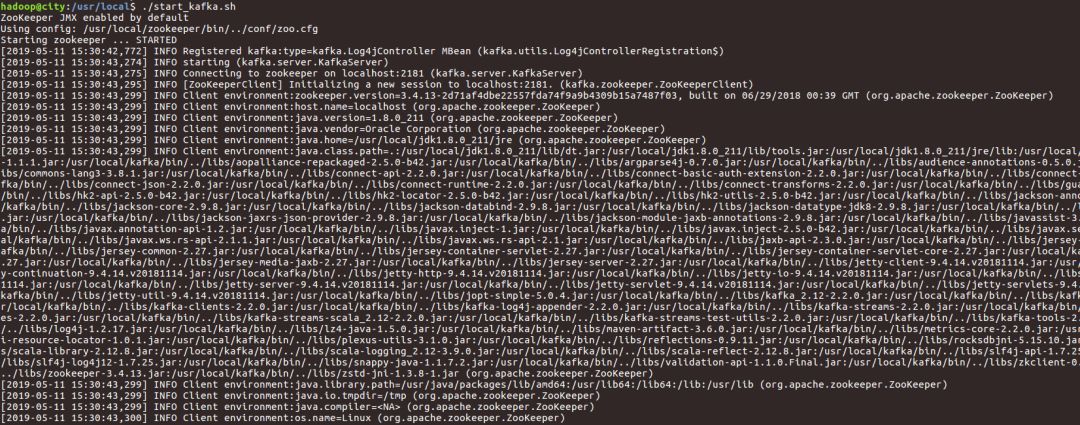
★启动Kafka
”
./bin/kafka-server-start.sh ./config/server.properties
★Topic创建
”
当使用下面maxwell提取出来的binlog信息的时候,默认使用kafka进行消费。
./kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
★发布与订阅
”
向Topic上发布消息,按Ctrl+D结束:
./kafka-console-producer.sh --broker-list localhost:9092 --topic test

从Topic上接收消息,按Ctrl+C结束:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

【Maxwell】
★Maxwell是什么?
”
官网原语:Maxwell's daemon, a mysql-to-json kafka producer。
这里解释一下Maxwell是将mysql binlog中的insert、update等操作提取出来,并以json数据返回作为kafka生产者。
当然自己也可以用编程实现binlog数据提取,并返回一个json数据。
★ ”
安装方式同上。
★mysql配置Maxwell
”
Maxwell配置文件中默认用户名密码均为maxwell,所以需要在mysql中做相应的授权。
mysql> GRANT ALL on maxwell.* to'maxwell'@'%' identified by 'maxwell';
mysql> GRANT SELECT, REPLICATION CLIENT,REPLICATION SLAVE on *.* to 'maxwell'@'%';
mysql> flush privileges;
★配置Maxwell
”
cp config.properties.example config.properties
vi config.properties
maxwell配置:
log_level=info
# 默认生产者
producer=kafka
kafka.bootstrap.servers=localhost:9092
# mysql login info
host=localhost
user=maxwell
password=maxwell
# kafka配置
kafka_topic=test
kafka.compression.type=snappy
kafka.acks=all
kinesis_stream=test
★启动maxwell
”
./maxwell/bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=test
当然也可以把上述封装成一个启动脚本:
#!/bin/bash
./maxwell/bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=test
直接启动:
./start_maxwell.sh
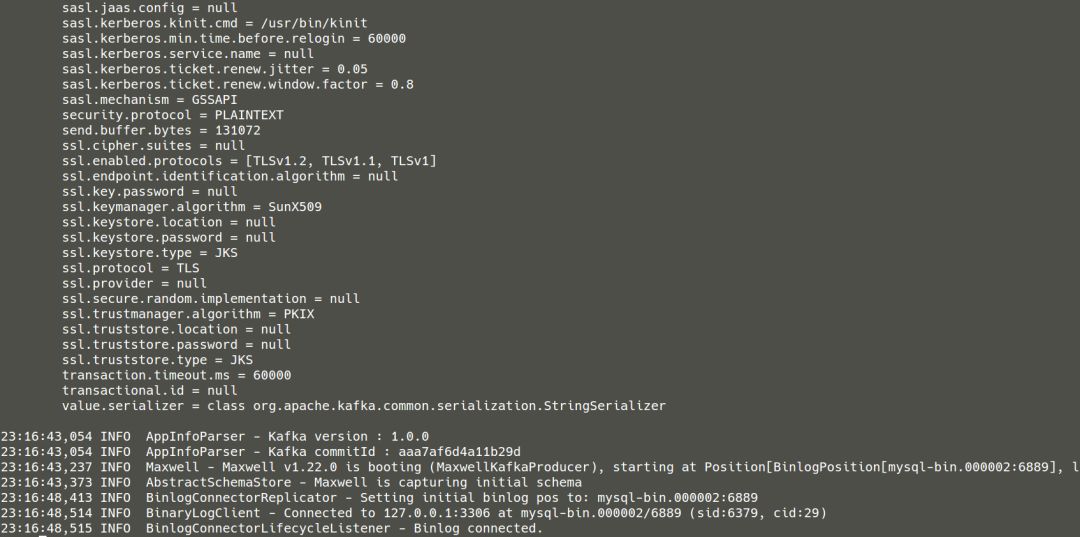
【Flink】
★什么是Flink?
”
干说Flink比较抽象,直接举个例子吧,就拿本节的同步来说,本节使用的Flink就是做实时流计算的一个场景ETL,数据仓库的实时同步,当上游下发数据到Kafka队列中,然后通过Flink程序做window的收集,并将数据sink到Hbase中。
★下载:https://flink.apache.org/
”
安装的时候,直接进行解压缩并配置path环境即可!
★解压缩
”
tar -zxf xxx.tgz
mv xxx /usr/local
★配置环境变量
”
vim ~/.bashrc
export FLNK_HOME=/usr/local/flink
export PATH=$FLINK_HOME/bin:$PATH
使上述生效:
source ~/.bashrc
★启动与关闭flink
”
cd flink/bin
./start-cluster.sh # 启动
stop-cluster.sh # 关闭
3.亿级MySQL数据插入
本节题目为:亿级数据从 MySQL 到 Hbase 的三种同步方案与实践,首先需要了解如何快速插入MySQL。
那么MySQL数据插入将会从以下几个方法入手:
load data infilePython 单条插入
Python 多线程插入
当然也可以使用其他语言进行实现!!!
下面来逐步谈谈数据插入!
数据插入之前,需要了解我们的数据,先来看一下数据字段描述:
数据以ASCII文本表示,以逗号为分隔符,以回车换行符(0x0D 0x0A)结尾。数据项及顺序:车辆标识、触发事件、运营状态、GPS时间、GPS经度、GPS纬度,、GPS速度、GPS方向、GPS状态
车辆标识:6个字符
触发事件:0=变空车,1=变载客,2=设防,3=撤防,4=其它
运营状态:0=空车,1=载客,2=驻车,3=停运,4=其它
GPS时间:格式yyyymmddhhnnss,北京时间
GPS经度:格式ddd.ddddddd,以度为单位。
GPS纬度:格式dd.ddddddd,以度为单位。
GPS速度:格式ddd,取值000-255内整数,以公里/小时为单位。
GPS方位:格式ddd,取值000-360内整数,以度为单位。
GPS状态:0=无效,1=有效
结束串:回车符+换行符
154747,4,2,20121130001607,116.6999512,39.9006233,0,128,1
078245,4,0,20121130001610,116.3590469,39.9909782,0,92,1
194086,4,1,20121130001610,116.5017776,40.0047951,25,220,1
那么只需要将上述的数据字段与数据对上就行了,一行为一条数据记录。
首先编写创建数据库与表命令:
create database loaddb;
CREATE TABLE loadTable(id int primary key not null auto_increment,
carflag VARCHAR(6),touchevent CHAR(1),opstatus CHAR(1),gpstime DATETIME,
gpslongitude DECIMAL(10,7),gpslatitude DECIMAL(9,7),gpsspeed TINYINT,
gpsorientation SMALLINT,gpsstatus CHAR(1))engine=MyISAM;
注意:上述选择了MyISAM引擎是因为load命令使用的时候,保证数据插入的效率!
3.1 load data infile
load data infile在导入大数据场景下非常的快!具体的说明后面会在比较的时候详细说,这里说一下使用语法,如下:
load data local infile "/home/light/mysql/gps1.txt" into table loadTable fields terminated by ',' lines terminated by "
" (carflag, touchevent, opstatus,gpstime,gpslongitude,gpslatitude,gpsspeed,gpsorientation,gpsstatus);
在使用这个命令的时候,是在MySQL的clinet端使用,登陆后敲这个命令即可!在数据字段描述中大家会看到几个关键点:以逗号为分隔符,以回车换行符,对应于上述代码是:
fields terminated by ',' lines terminated by "
"
注意:更换自己的数据集路径!
3.2 Python 批量插入
Python单条插入使用的是pymysql库。下面是部分代码,完整代码见:
批量提交源码
with open('/home/light/mysql/gps1.txt', 'r') as fp:
for line in fp:
...
...
...
count += 1
if count and count%70000==0:
# 执行多行插入,executemany(sql语句,数据(需一个元组类型))
self.cur.executemany(sql, data_list)
# 提交数据,必须提交,不然数据不会保存
self.conn.commit()
data_list = []
print("提交了:" + str(count) + "条数据")
if data_list:
# 执行多行插入,executemany(sql语句,数据(需一个元组类型))
self.cur.executemany(sql, data_list)
# 提交数据,必须提交,不然数据不会保存
self.conn.commit()
print("提交了:" + str(count) + "条数据")
self.cur.close() # 关闭游标
self.conn.close() # 关闭pymysql连接
上述有个关键点需要说明一下:
(1)使用executemany而非execute,这个提交速度要快!(2)使用批量插入,而非单条插入提交,这样会提升效率!
3.3 Python 多线程插入
原始数据为一个gps1.txt文件,这个数据太大,如果直接使用多线程插入,不太方便,所以先使用文件切分方法,然后进行多线程的插入。
关于文件切分,可以点击这里:文件切分源码。
Python中使用多线程源码
def multicore(self):
file_list = [1,2324,4648,6972,9298]
m1 = mp.Process(target=self.run, args=(file_list[0],file_list[1],'m1',))
m2 = mp.Process(target=self.run, args=(file_list[1]+1,file_list[2],'m2',))
m3 = mp.Process(target=self.run, args=(file_list[2]+1,file_list[3],'m3',))
m4 = mp.Process(target=self.run, args=(file_list[3]+1,file_list[4],'m4',))
m1.start()
m2.start()
m3.start()
m4.start()
m1.join()
m2.join()
m3.join()
m4.join()
具体插入思路是使用四个线程分别读取每个区间段的数据,然后再对数据进行批量插入!如果这一块不懂的伙伴,欢迎留言哈~
3.4 MySQL数据导入方法对比
★load命令与普通的insert区别
”
| 相同点 | 不同点 |
|---|---|
| 两者都是通过读取本地txt文件,按照相同的分隔来读取进行插入。 | 程序插入法实质为insert语句间接执行。load data设计用于在单个操作中大量加载表格数据。 |
★效率比较
”
两者耗时如下:
第一种:load data (这里截取的是Innodb引擎表的插入结果,当使用MyISAM时,会比现在还快!)

用时1h11分。
第二种:程序插入法(这里只截取了批量插入的!)
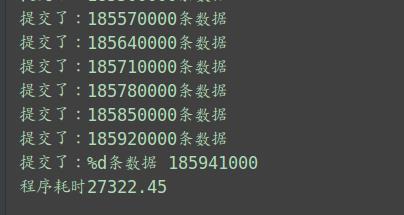
用时:27322.45/36=7.58h
上述对比可知,load data效率非常高,原因在于使用的是load data infile方式,而第二种则为传统的insert方式。
究其根源主要是MySQL内部对于load 和 insert的处理机制不同。
Load的处理机制是:在执行load之前,会关掉索引,当load全部执行完成后,再重新创建索引.
Insert的处理机制是:每插入一条则更新一次数据库,更新一次索引.
4.同步利器
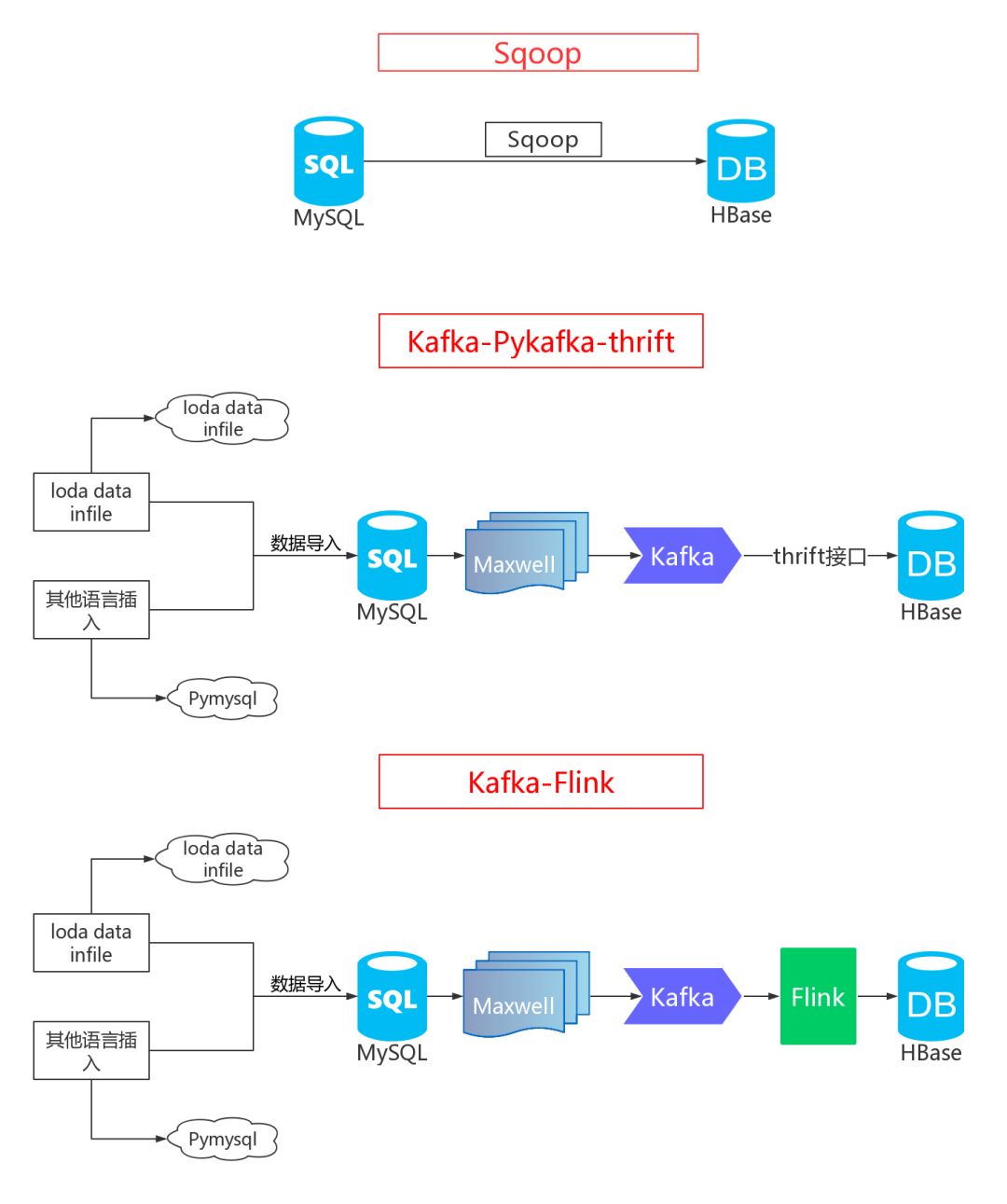
4.1 简单粗暴Sqoop
首先来回顾一下Sqoop架构图:

这里大家记住一个规则:大数据需要切分!如果不切分,这个亿级数据直接导入会崩溃!!!
★什么是Sqoop?
”
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的开源工具,可以将一个关系型数据库中的数据导进到Hadoop的HDFS或者HBase等。
sqoop核心参数与代码解释:
sqoop import --connect jdbc:mysql://localhost:3306/loaddb --username root --password xxxx --query "${sql}" --hbase-row-key id --hbase-create-table --column-family info --hbase-table mysql_data --split-by id -m 4
注意:当-m 设置的值大于1时,split-by必须设置字段!
由于数据太大,需要分片导入,具体导入代码见仓库:
up=185941000
for((i=1; i>0; i++))
do
start=$(((${i} - 1) * 40000 + 1))
end=$((${i} * 40000))
if [ $end -ge $up ]
then
end=185941000
fi
sql="select id,carflag, touchevent, opstatus,gpstime,gpslongitude,gpslatitude,gpsspeed,gpsorientation,gpsstatus from loaddb.loadTable1 where id>=${start} and id<=${end} and $CONDITIONS";
sqoop import --connect jdbc:mysql://localhost:3306/loaddb --username root --password xxxx --query "${sql}" --hbase-row-key id --hbase-create-table --column-family info --hbase-table mysql_data --split-by id -m 4
echo Sqoop import from: ${start} to: ${end} success....................................
if [ $end -eq $up ]
then
break
fi
done
思路是每隔4万导入一次,当然您也可以修改。
耗时:(使用linux的time统计bash脚本运行时间)

导入结果:
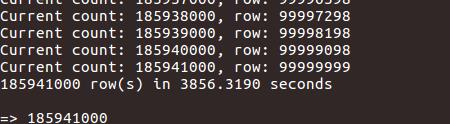
如果遇到问题,显示虚拟内存溢出,不断新开进程,杀死之前的进程,解决方案:关闭虚拟内存。

修改yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
以上就是MySQL同步Hbase方案1。
4.2 Kafka-thrift同步
4.2.1 binlog
binlog是sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志。
可以简单的理解该log记录了sql标中的更新删除插入等操作记录。通常应用在数据恢复、备份等场景。
★开启binlog
”
对于我的mysql的配置文件在下面这个文件夹,当然直接编辑my.cnf也是可以的。
vi /etc/mysql/mysql.conf.d/mysqld.cnf
对配置文件设置如下:

★查看是否启用
”
进入mysql客户端输入:
show variables like '%log_bin%';
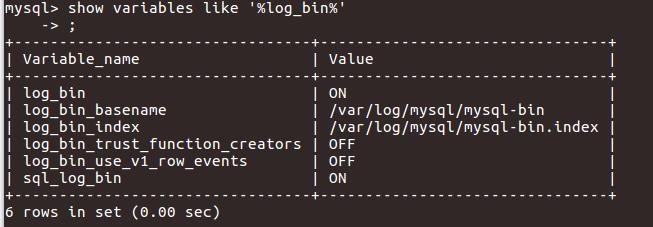
★binlog介绍
”
我的log存放在var下面的log的mysql下面:
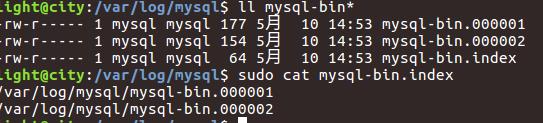
在mysql-bin.index中包含了所有的log文件,比如上述图就是包含了1与2文件,文件长度超过相应大小就会新开一个log文件,索引递增,如上面的000001,000002。
★binlog实战
”
首先创建一个表:
create table house(id int not null primary key,house int,price int);
向表中插入数据:
insert into loaddb.house(id,house,price) values(1,2,3);
上面提到插入数据后,binlog会更新,那么我们去查看上面log文件,应该会看到插入操作。
Mysql binlog日志有ROW,Statement,MiXED三种格式;
set global binlog_format='ROW/STATEMENT/MIXED'
命令行:
show variables like 'binlog_format'
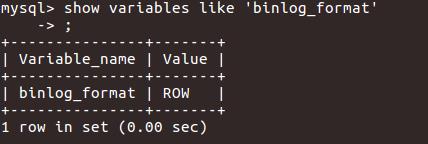
对于mysql5.7的,binlog格式默认为ROW,所以不用修改。
那么为何要了解binlog格式呢,原因很简单,我要查看我的binlog日志,而该日志为二进制文件,打开后是乱码的。对于不同的格式,查看方式不一样!
对于ROW模式生成的sql编码需要解码,不能用常规的办法去生成,需要加上相应的参数,如下代码:
sudo /usr/bin/mysqlbinlog mysql-bin.000002 --base64-output=decode-rows -v
使用mysqlbinlog工具查看日志文件:
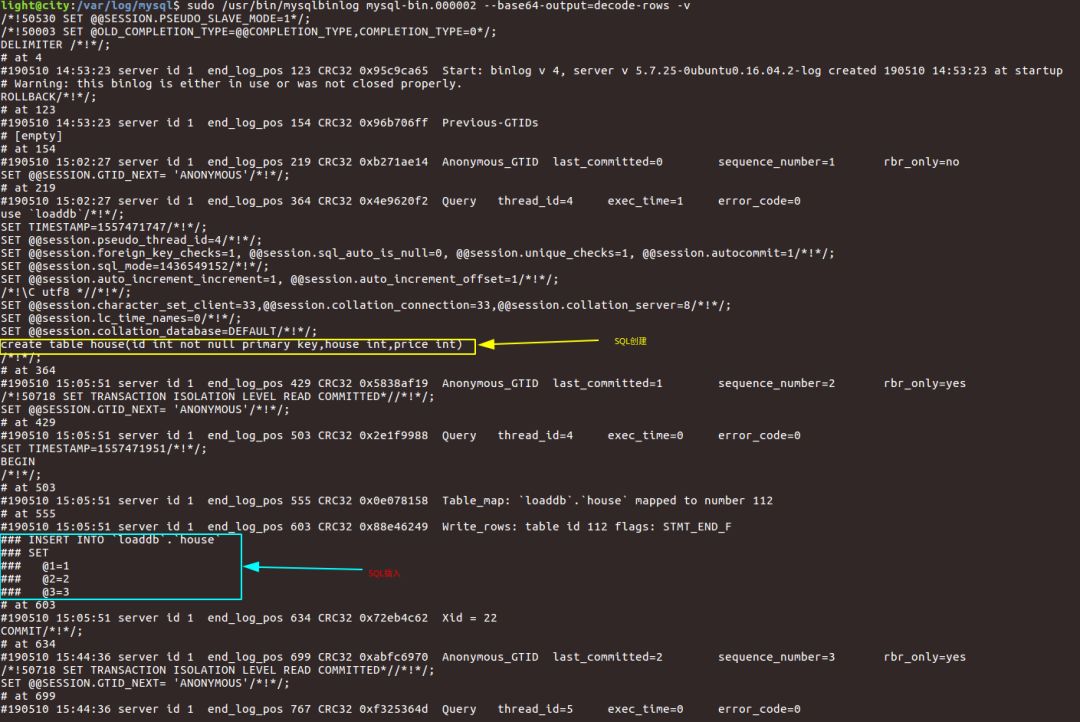
4.2.2 启动thrift接口
thrift为其他语言与hbase操纵接口。启动目的为后面数据插入做准备。

4.2.3 kafka-thrift流程小结
使用github仓库代码将原始数据进行每2w一个文件切分!
切分输出:

编写Kafka数据入Hbase,完整代码见github仓库代码:
def batchTokafka(self,start_time,table_name):
table = self.conn.table(table_name)
i = 1
with table.batch(batch_size=1024*1024) as bat:
for m in self.consumer:
t = time.time()
database = json.loads(m.value.decode('utf-8'))["database"]
name = json.loads(m.value.decode('utf-8'))["table"]
row_data = json.loads(m.value.decode('utf-8'))["data"]
if database=='loaddb'and name == 'sqlbase1':
row_id = row_data["id"]
row = str(row_id)
print(row_data)
del row_data["id"]
data = {}
for each in row_data:
neweach = 'info:' + each
data[neweach] = row_data[each]
data['info:gpslongitude'] = str(data['info:gpslongitude'])
data['info:gpslatitude'] = str(data['info:gpslatitude'])
data['info:gpsspeed'] = str(data['info:gpsspeed'])
data['info:gpsorientation'] = str(data['info:gpsorientation'])
# self.insertData(table_name, row, data)
print(data)
bat.put(row,data)
if i%1000==0:
print("===========插入了" + str(i) + "数据!============")
print("===========累计耗时:" + str(time.time() - start_time) + "s=============")
print("===========距离上次耗时"+ str(time.time() - t) +"=========")
i+=1
上述运行后,开始MySQL数据插入,这里插入采用4个多进程进行程序插入,速度非常快。
当MySQL数据在插入的同时,数据流向如下:
mysql插入->入库mysql->记录binlog->maxwell提取binlog->返回json给kafka->kafka消费端通过thrift接口->写入hbase。
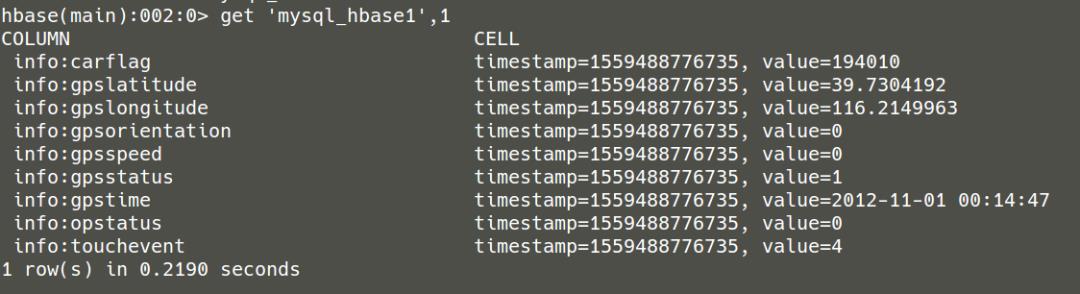
上述同步的结果如下,为了明确是否真正数据同步,只看了一条数据,作为验证。
★多个进程插入图
”
★kafka消费入hbase图
”
★MySQL数据图
”

★Hbase数据图
”
以上就是从Mysql到Hbase的同步方案2。
4.3 Kafka-Flink
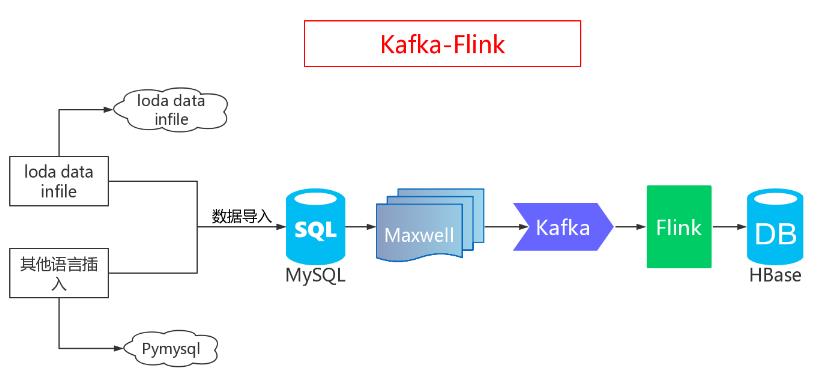
4.3.1 实时同步Flink
方案3为方案2的改进,上述是通过Python写入Hbase,这里改成java,并使用最新的流处理技术:Flink。
Flink在ETL场景中使用频繁,非常适合数据同步,于是在这个方案中采用Flink进行同步。
SingleOutputStreamOperator<Student> student = env.addSource(
new FlinkKafkaConsumer011<>(
"test", //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props)).setParallelism(9)
.map(string -> JSON.parseObject(string, Student.class))
.setParallelism(9);
long start =System.currentTimeMillis();
student.timeWindowAll(Time.seconds(3)).apply(new AllWindowFunction<Student,
List<Student>, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<Student> values,
Collector<List<Student>> out) throws Exception {
ArrayList<Student> students = Lists.newArrayList(values);
if (students.size() > 0) {
System.out.println("1s内收集到 mysql表 的数据条数是:"
+ students.size());
long end =System.currentTimeMillis();
System.out.printf("已经用时time:%d
",end-start);
out.collect(students);
}
}
}).addSink(new SinkToHBase()).setParallelism(9);
使用Flink进行批量入Hbase。
4.3.2 Flink小结
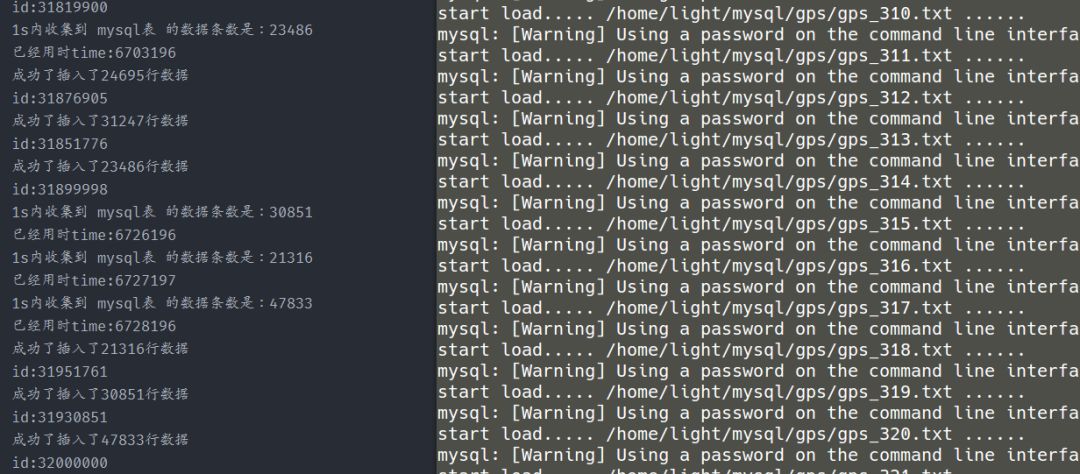
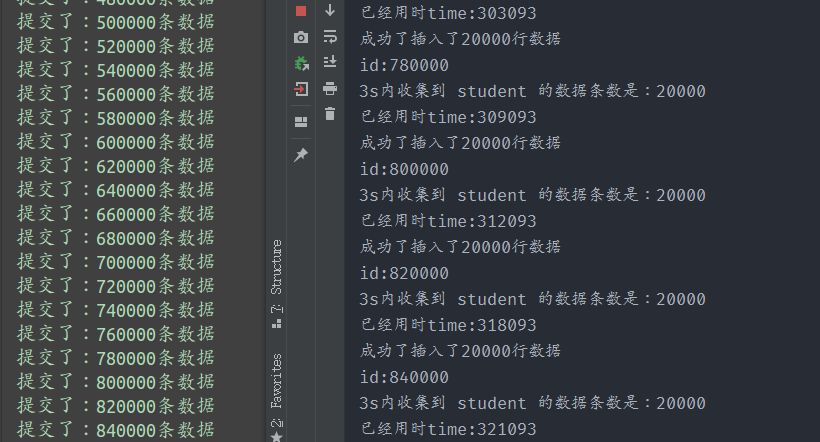
首先启动maxwell与kafka,hbase也要启动,接着在数据写入端,可以采用load data infile或者python程序插入法进行数据插入,数据会通过maxwell到kafka再到Flink,然后sink到Hbase。
★插入端为load data infile的同步
”
★插入端为Python程序的同步
”
5.Phoenix组件和原生Hbase查询的时间性能对比
-
原生Hbase查询时间:
count 'mysql_data'
Hbase查询时间为3856秒大约1小时7分钟
Hbase查询优化
count 'mysql_data', INTERVAL => 10000000
每隔一千万查询一次:
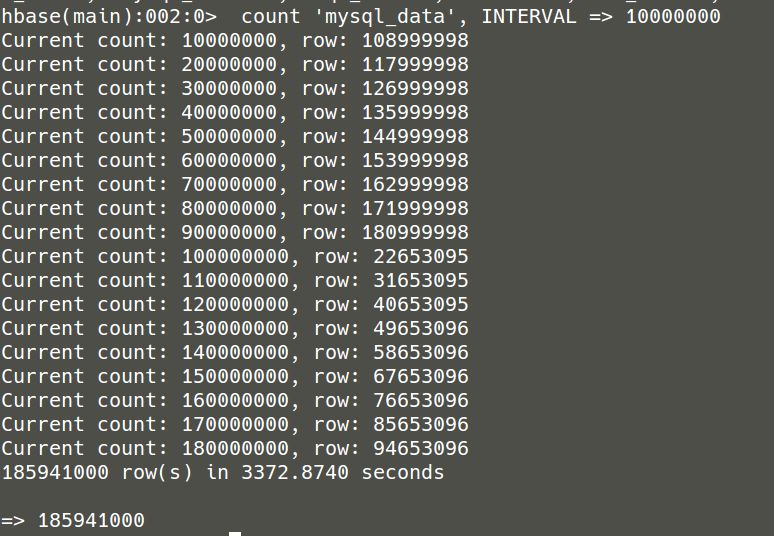
间隔查询3372.5740秒,大约耗时:56分钟。
协处理器
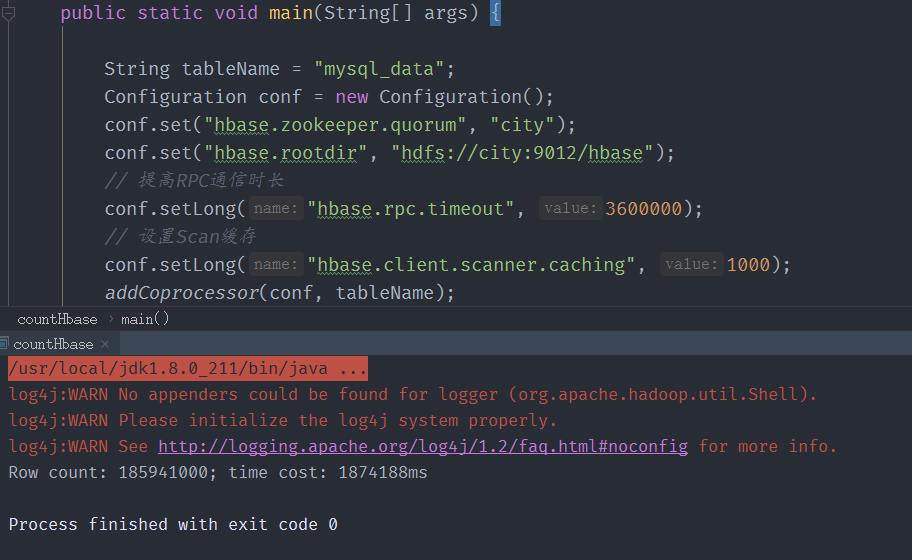
耗时:1874188毫秒=1874.188s秒,大约31分钟。
Phoenix查询时间:
 可以看到Hbase查询时间为3956秒大约1小时多一点。
可以看到Hbase查询时间为3956秒大约1小时多一点。
而Phoenix查询时间为2015.033秒,大约33分钟左右。
sqoop导入,大约50h左右。kafka-thrift单条插入约等于sqoop导入。kafka-thrift批量插入,大约7h。kafka-flink,大约3-7h。
不同的同步方式,大家可以看到效率有着明显的差别,其中使用Flink效率最高,并且如果自己电脑是集群模式,那么效率就会更加的高!
优化点:Flink窗口收集设置,上游插入速度调整,下游接收调整等。
最后,几点策略总结如下:
-
大数据需分割、批量插入 -
插入有序 -
phoenix大数据查询需设超时时间。 -
Flink最稳定、效率最高、根据计算机性能影响。 -
Python thrift,可以批量与单条插入结合。 -
Sqoop需切分、虚拟内存需关闭。 -
HBase若崩溃,赶紧查Zookeeper。
本节到此,就结束了,如果你能坚持看到这里,就表示你学会了很多同步与插入方法,本节比较适合上手实践,欢迎大家与我进行交流!
有热门推荐 以上是关于亿级数据从 MySQL 到 Hbase 的三种同步方案与实践的主要内容,如果未能解决你的问题,请参考以下文章