「回顾」HBase应用与高可用实践
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「回顾」HBase应用与高可用实践相关的知识,希望对你有一定的参考价值。
本文由DataFun社区根据哥不是小萝莉在中国HBase技术社区第五届MeetUp 中分享的《HBase应用与高可用实践》编辑整理而成。

今天主要从以下几个方面进行分享,首先介绍下平安科技HBase研究使用现状,我们给用户解决了哪些问题。接着介绍如何保证HBase集群的高效和稳定,最后是后续规划。
1.平安科技HBase使用现状

平安科技HBase使用现状可以分为两个方面来介绍,一个是HBase集群规模和数据量,第二个是应用场景,有哪些用户使用。HBase集群规模有数百台物理机,数据量有PB级。上图列举了HBase应用场景,有产险、寿险,信息安全、一账通,还有智能引擎、信贷等一系列应用。
2.解决用户那些问题
在大数据应用中用户面临的问题有海量数据的存储,接着是可能关心性能和可靠性,最后就是数据的迁移。

首先是海量数据存储,有的用户应用的Oracle数据库,后续应用场景会产生多大的数据量无法预估。所以可将数据接入HBase集群中,HBase支持在线扩容,即使在一段时间内数据量呈现出爆炸式增长,可以通过HBase横向扩容来满足用户需求。第二个问题就是用传统DB在维护方面有很多问题,迁移到HBase上来,迁移和维护是非常方便的。
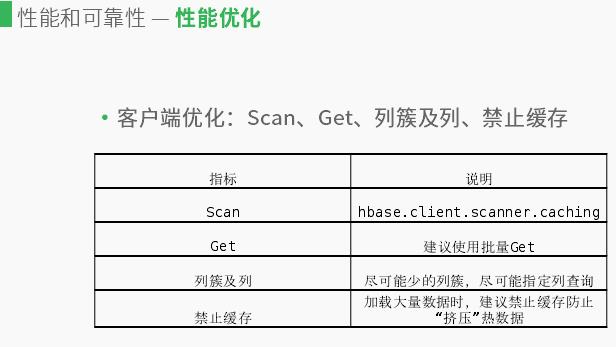
性能方面是在应用程序方面,用户调用HBase集群遇到的一些性能问题,还有就是如何保证高可用。首先是客户端优化,介绍几个用户在客户端调用HBase的API所做的优化,在客户端Scan操作请求数据,并不是全部返回,通过多次IPC请求交互,数据得到返回,如果数据量较大,可能降低IPC交互次数,降低耗时。另一个就是Get方面,有两个层面。第一个可以通过单个row-key去进行Get操作,另一个是将row-key操作封装到一个list集合,进行批量Get。建议批量Get,原理基本和Scan原理类似,主要是减少用户IPC交互次数,从而降低耗时。
接下来是列簇及列的优化,存储时相同的列簇是存在一个序列中,不同列簇数据分开存储。有多个列簇进行检索时,如果只是row-key检索而没有指定列簇,索引会独立去检索,相对于指定列簇检索效率较低;如果列簇越多影响越大。用户在涉及表的时候,有时会涉及上千列,检索时只检索有用的列,尽可能检索你指定的列,这样可以降低耗时。第四个是禁止缓存,在写数据时,客户端会加载很多数据,如果不禁止缓存,会将热数据挤压出去,业务在检索数据会先从热数据检索,这样导致从HDFS中重新加载,这样也会导致延时。

另一个可以从服务端优化,也有几个优化。首先是均衡优化,HBase均衡操作有两种方式,一种是通过balance_switch参数,如果是true就是自动均衡,false就是关闭当前均衡操作。第二种就是通过balancer,需要手动执行。如HBase节点挂机重启导致region不均衡,还有就是扩容新HBase节点导致region不均衡。如果balance_switch没效果,可以开启balancer手动强制均衡。需要注意是均衡操作遇到RIT问题,均衡操作无效。在判断regionserver的region值处于均衡状态,通过当前region总个数除以所有regionserver数,然后用比值乘以0.8这是其最小值,最大值是比值乘以1.2,在这个范围做均衡操作会跳过,做均衡可以避免节点挂掉负载转移到正常节点而引起负载过高导致的延时。
第二个是Block Cache,是读操作比较有效的一种手段。有时缓存命中率不高,可以开始对外内存提高缓存命中率;同时开启对外内存对GC也有好处。第三个是Compaction操作,这个可以保证数据本地性为1。在Compaction操作是避免自动执行,空闲时段定时执行避免影响集群IO。
另一个方面是高可靠性,HBase是高可用的、有组备,可以不用担心存在单点问题,master挂点可以立即切换到备用master,备用master可以立即切换为可用状态,对外提供服务。还有就是数据迁移问题。迁移场景可能有:HBase集群从一个地方搬到另一个地方,涉及到HBase集群迁移;还有就是原先数据存储于hive中,需要将其迁移到HBase中。
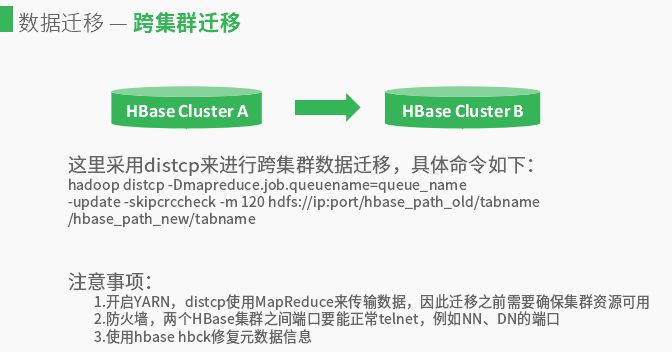
两个集群数据迁移格式一样,可以通过distcp来进行跨集群数据迁移,具体命令hadoop distcp -Dmapreduce.job.queuename=queue_name-update –skipcrccheck -m 120 hdfs://ip:port/hbase_path_old/tabname/hbase_path
_new/tabname,因为需要使用Map Reduce需要指定队列名。迁移过程需要注意:
(1)开启YARN,distcp使用Map Reduce来传输数据,因此迁移之前需要确保集群资源可用。
(2)防火墙,两个HBase集群之间端口要能正常telnet,例如NN、DN的端口。

在集群迁移可以回遇到上述问题,迁移文件时原集群文件未关闭,处于写状态,distcp检验长度不一致就会处于失败状态。解决方案是先通过检测文件状态,执行hdfs fsck [hdfs_file_path]|[hdfs://ip:port/path],未关闭,执行hdfs debug recover Lease-path [hdfs_file_path],重新进行数据迁移,执行hadoop distcp。需要注意是解决方案第2步中,关闭HDFS文件时,可能会失败,例如出现异常“Giving up on recover Lease”,可再次执行关闭,成功后会有“recover Lease SUCCEEDED on”信息出现。
接下来是Hive数据迁移到HBase,在集群A(不包含HBase),将集群A中的Hive数据迁移到集群B中的HBase。迁移方式有两种,第一种在集群A中生成HFile⽂件,然后使用distcp将HFile⽂件迁移到集群B,最后使用HBase的Bulk Load的方式将数据导入到HBase表。第二种方式是写代码使用API接口,直接通过Bulk Load的方式进行数据迁移,以应用程序的形式来实现数据迁移的工作。
3.如何保证HBase集群的高效和稳定
如何保证HBase集群的高效和稳定,首先监控必不可少,然后就是其修复机制,其次还有一些特殊处理。
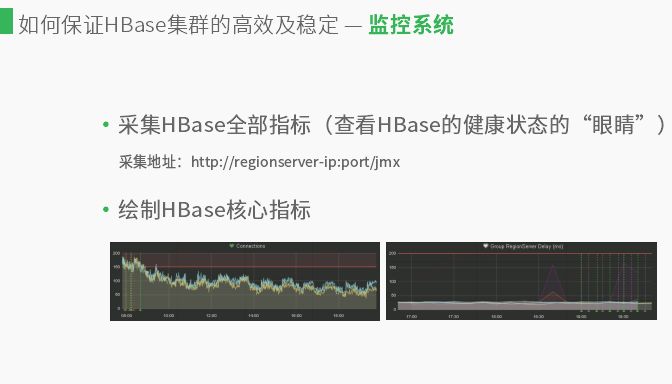
如果采集了HBase的全部指标就掌握了HBase的健康状态,regionserver提供监控接口采集指标数据,http://regionserver-ip:port/jmx。然后对核心指标绘制图表,如图在红线以下是正常的,红线以上可能是集群有抖动,应用程序可能存在问题。后边的图是集群耗时状态,用户在反馈时,应用程序访问HBase很慢,他们关心的是应用程序。

修复机制方面,监控系统只是去发现问题反馈问题。这里需要监控系统协同完成。监控系统发现、反馈问题,修复系统自动修复问题,能自动修复的尽可能配置自动修复策略,例如集群进程可用性、存在性、负载均衡修复等。
RIT问题,⼀般情况下,RIT都是瞬时的,但是有些情况会让其进入永久RIT状态,永久RIT状态带来的不良后果就是管理员无法干预Region均衡操作,从而影响集群的负载均衡。这里有个实际案例告诉应该如何解决,用户在合并Region操作时,发现RIT状态直显示MERGING_NEW状态,查看HBase JIRA发现这是触发了HBASE-17682的BUG,需要打补丁进行修复。需要注意是这种应用程序没问题,只是会影响regionserver重启均衡得不到保证,MERGING_NEW状态产生的原因是客户端发起合并请求命令,master会组织regionserver上两个region进行合并,合并前会生成一个MERGING_NEW状态,会存在master内存中。这样可能当前master有这个状态,backup的master没有这个状态,做一个主备的切换,这个是临时解决方案,后续还需要打上补丁进行修复。
4.后续规划
后续规划会降低HBase使用门槛,让用户能更加方便的接入HBase。然后是更加智能化的监控系统和修复系统,另外在HBase2会去做一个POC的测试,做一个版本升级。
作者介绍:
哥不是小萝莉,平安科技数据平台部大数据高级工程师,主要从事大数据平台建设,专注于HBase底层核心工作优化,开源Kafka Eagle监控系统,热衷于Kafka等大数据套件技术,出版《Hadoop大数据挖掘从入门到进阶实战》书籍,新书《Kafka并不难学》即将上市。
北京上海深圳杭州Hbase交流群招募中感兴趣的小伙伴,欢迎加管理员微信入群:tianmuqu
——END——
文章没看够?下面还有:
以上是关于「回顾」HBase应用与高可用实践的主要内容,如果未能解决你的问题,请参考以下文章
如何保证 HBase 服务的高可用?看看这份 HBase 可用性分析与高可用实践吧!